このトピックでは、特定のシナリオでJindo DistCpを使用する方法について説明します。
前提条件
- 必要なバージョンのE-MapReduce(EMR)クラスターが作成されていること。詳細については、「クラスターの作成」をご参照ください。
- Java Development Kit(JDK) 1.8がインストールされていること。
- jindo-distcp-<version>.jar がHadoopバージョンに基づいてダウンロードされていること:
- Hadoop 2.7以降の場合 : jindo-distcp-3.0.0.jar
- Hadoop 3.Xの場合 : jindo-distcp-3.0.0.jar
シナリオ
- シナリオ 1:大量のHDFSデータまたは多数のHDFSファイル(数百万または数千万)をOSSにインポートする場合、最適化に必要なパラメーターは何ですか?
- シナリオ 2:Jindo DistCpを使用してOSSにデータをインポートした後、データの整合性をどのように検証しますか?
- シナリオ 3:DistCpタスクがHDFSデータのOSSへのインポートに失敗した場合、再開可能なアップロードをサポートするために必要なパラメーターは何ですか?
- シナリオ 4:Jindo DistCpを使用してHDFSデータをOSSにインポートするときに生成される可能性のあるファイルを処理するために必要なパラメーターは何ですか?
- シナリオ 5:Jindo DistCpタスクが存在するYARNキューと、タスクに割り当てられる使用可能な帯域幅を指定するために必要なパラメーターは何ですか?
- シナリオ 6:OSSコールドアーカイブ、アーカイブ、またはIAストレージにデータを書き込むときに必要なパラメーターは何ですか?
- シナリオ 7:小規模ファイルの割合と特定のファイルサイズに基づいてファイル転送を高速化するために必要なパラメーターは何ですか?
- シナリオ 8:Amazon S3をデータソースとして使用する場合、必要なパラメーターは何ですか?
- シナリオ 9:OSSにファイルをコピーし、コピーしたファイルをLZOまたはGZ形式で圧縮する場合、必要なパラメーターは何ですか?
- シナリオ 10:特定のルールに一致するファイル、または同じ親ディレクトリのいくつかのサブディレクトリにあるファイルをコピーする場合、必要なパラメーターは何ですか?
- シナリオ 11:ファイル数を減らすために、特定のルールに一致するファイルをマージする場合、必要なパラメーターは何ですか?
- シナリオ 12:コピー操作後に元のファイルを削除する場合、必要なパラメーターは何ですか?
- シナリオ 13:CLIでOSSのAccessKeyペアとエンドポイント情報を指定したくない場合はどうすればよいですか?
シナリオ 1:大量のHDFSデータまたは多数のHDFSファイル(数百万または数千万)をOSSにインポートする場合、最適化に必要なパラメーターは何ですか?
- HDFSからデータを読み取ることができる。
- OSSのAccessKey ID、AccessKeyシークレット、およびエンドポイントを取得している。宛先OSSバケットにデータを書き込むことができる。
- OSSバケットのストレージクラスがアーカイブではない。
- MapReduceタスクを送信できる。
- Jindo DistCpのJARパッケージがダウンロードされている。
hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --parallelism 10enableBatch をtrueに設定して最適化することもできます。最適化コマンド:hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --parallelism 500 --enableBatchシナリオ 2:Jindo DistCpを使用してOSSにデータをインポートした後、データの整合性をどのように検証しますか?
- Jindo DistCpカウンターMapReduceタスクのカウンター情報でDistCpカウンターを確認します。
Distcp Counters Bytes Destination Copied=11010048000 Bytes Source Read=11010048000 Files Copied=1001 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0ここで:- Bytes Destination Copiedは、宛先ディレクトリにコピーするファイルのサイズをバイト単位で指定します。
- Bytes Source Readは、ソースディレクトリから読み取るファイルのサイズをバイト単位で指定します。
- Files Copiedは、コピーされたファイルの数を指定します。
- Jindo DistCp --diff
--diffパラメーターで終わるコマンドを実行して、ソースディレクトリと宛先ディレクトリのファイルを比較します。このコマンドは、ソースディレクトリと宛先ディレクトリのファイルの名前とサイズを比較し、コピーされていないファイルまたはコピーに失敗したファイルを識別し、コマンドが送信されたディレクトリにマニフェストファイルを生成します。シナリオ 1で説明されているコマンドに--diffを追加します。例:シナリオ 1hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --diffすべてのファイルがコピーされると、次の情報が返されます。INFO distcp.JindoDistCp: distcp has been done completely
シナリオ 3:DistCpタスクがHDFSデータのOSSへのインポートに失敗した場合、再開可能なアップロードをサポートするために必要なパラメーターは何ですか?
--diffを追加して、すべてのファイルがコピーされているかどうかを確認します。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --diffすべてのファイルがコピーされると、次の情報が返されます。INFO distcp.JindoDistCp: distcp has been done completely.- 一部のファイルがコピーされていない場合は、マニフェストファイルが生成されます。この場合、
--copyFromManifestと--previousManifestを使用して残りのファイルをコピーします。例:hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --dest oss://destBucket/hourly_table --previousManifest=file:///opt/manifest-2020-04-17.gz --copyFromManifest --parallelism 20file:///opt/manifest-2020-04-17.gzは、マニフェストファイルが格納されているパスです。
シナリオ 4:Jindo DistCpを使用してHDFSデータをOSSにインポートするときに生成される可能性のあるファイルを処理するために必要なパラメーターは何ですか?
Jindo DistCpを使用してHDFSデータをOSSにインポートすると、アップストリームプロセスは引き続きファイルを生成します。たとえば、1時間ごとまたは1分ごとに新しいファイルが作成される場合、スケジュールに基づいてファイルを受信するようにダウンストリームプロセスを構成します。 Jindo DistCpは更新方法を提供します。
hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --parallelism 10 --update--update は、増分コピモードを指定します。ファイルをコピーする前に、JindoDistCpはファイルの名前、サイズ、およびチェックサムを順番に比較します。ファイルのチェックサムを比較したくない場合は、--disableChecksum を追加して無効にします。
シナリオ 5:Jindo DistCpタスクが存在するYARNキューと、タスクに割り当てられる使用可能な帯域幅を指定するために必要なパラメーターは何ですか?
--queue:YARNキューの名前。--bandwidth:指定された帯域幅のサイズ(MB/秒)。
hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --queue yarnqueue --bandwidth 6 --parallelism 10シナリオ 6:OSSコールドアーカイブ、アーカイブ、またはIAストレージにデータを書き込むときに必要なパラメーターは何ですか?
- コールドアーカイブストレージクラスを使用する場合は、シナリオ 1で説明されているコマンドに
--policy coldArchiveを追加します。例:シナリオ 1hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --policy coldArchive --parallelism 20説明 コールドアーカイブストレージクラスは、一部のリージョンでのみ使用できます。詳細については、「概要」をご参照ください。 - アーカイブストレージクラスを使用する場合は、シナリオ 1で説明されているコマンドに
--policy archiveを追加します。例:シナリオ 1hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --policy archive --parallelism 20 - 低頻度アクセス(IA)ストレージクラスを使用する場合は、シナリオ 1で説明されているコマンドに
--policy iaを追加します。例:シナリオ 1hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --policy ia --parallelism 20
シナリオ 7:小規模ファイルの割合と特定のファイルサイズに基づいてファイル転送を高速化するために必要なパラメーターは何ですか?
- 多数の小規模ファイルと、単一の大規模ファイルのデータ量が多い場合
コピーするファイルのほとんどが小規模ファイルであるが、単一の大規模ファイルのデータ量が大きい場合、一般的な解決策は、コピーするファイルをランダムに割り当てることです。この場合、ジョブ割り当てプランを最適化しないと、少数の大きなファイルと多数の小さなファイルが同じコピー処理に割り当てられる可能性があります。これにより、コピーのパフォーマンスが最適ではなくなります。
シナリオ 1で説明されているコマンドに--enableDynamicPlanを追加して、最適化を有効にします。 --enableDynamicPlanは、シナリオ 1--enableBalancePlanと一緒に使用することはできません。例:hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --enableDynamicPlan --parallelism 10次の図は、プランを最適化する前後のデータコピのパフォーマンスを示しています。
- ファイルサイズの大きな違いがない場合コピーするファイルのサイズに大きな違いがない場合は、
--enableBalancePlanを使用してジョブ割り当てプランを最適化します。例:hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --enableBalancePlan --parallelism 10次の図は、プランを最適化する前後のデータコピのパフォーマンスを示しています。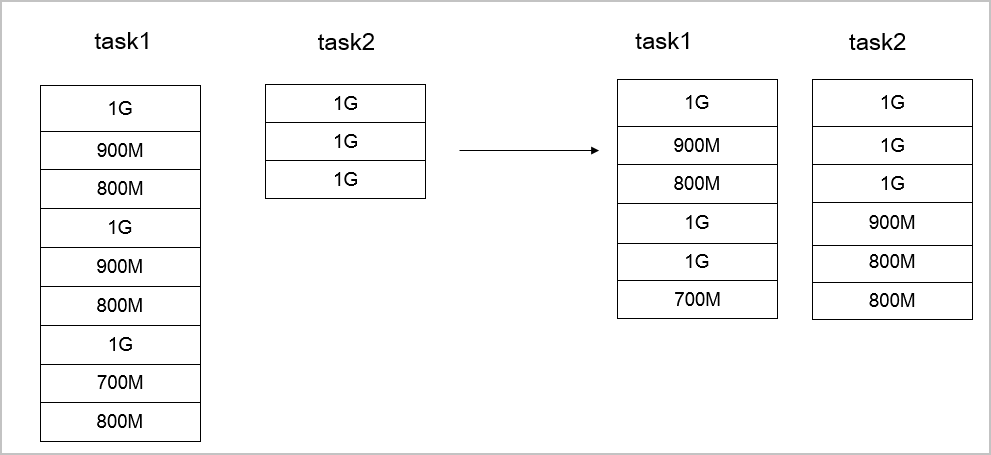
シナリオ 8:Amazon S3をデータソースとして使用する場合、必要なパラメーターは何ですか?
--s3Key:Amazon S3のAccessKey ID--s3Secret:Amazon S3のAccessKeyシークレット--s3EndPoint:Amazon S3のエンドポイント
hadoop jar jindo-distcp-<version>.jar --src s3a://yourbucket/ --dest oss://destBucket/hourly_table --s3Key yourkey --s3Secret yoursecret --s3EndPoint s3-us-west-1.amazonaws.com --parallelism 10シナリオ 9:OSSにファイルをコピーし、コピーしたファイルをLZOまたはGZ形式で圧縮する場合、必要なパラメーターは何ですか?
--outputCodec を使用して、コピーしたファイルをLZOやGZなどの形式で圧縮し、ファイルの格納に使用されるスペースを削減できます。
--outputCodec を追加します。例:シナリオ 1hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --outputCodec=gz --parallelism 10- none:Jindo DistCpはコピーされたファイルを圧縮しません。ファイルが既に圧縮されている場合、Jindo DistCpはファイルを解凍します。
- keep:Jindo DistCpは、圧縮を変更せずにファイルをコピーします。
シナリオ 10:特定のルールに一致するファイル、または同じ親ディレクトリのいくつかのサブディレクトリにあるファイルをコピーする場合、必要なパラメーターは何ですか?
- 特定のルールに一致するファイルをコピーする場合は、シナリオ 1で説明されているコマンドに
--srcPatternを追加します。例:シナリオ 1hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --srcPattern .*\.log --parallelism 10--srcPattern:コピー操作のファイルをフィルタリングする正規表現を指定します。 - 同じ親ディレクトリにあるいくつかのサブディレクトリに格納されているファイルをコピーする場合は、シナリオ 1で説明されているコマンドに
--srcPrefixesFileを追加します。シナリオ 1hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --srcPrefixesFile file:///opt/folders.txt --parallelism 20--srcPrefixesFile:Jindo DistCpが同じ親ディレクトリにある複数のフォルダー内のファイルを一度にコピーできるようにします。folders.txt ファイルの内容:hdfs://emr-header-1.cluster-50466:9000/data/incoming/hourly_table/2017-02-01 hdfs://emr-header-1.cluster-50466:9000/data/incoming/hourly_table/2017-02-02
シナリオ 11:ファイル数を減らすために、特定のルールに一致するファイルをマージする場合、必要なパラメーターは何ですか?
--targetSize:マージされたファイルの最大サイズ(MB)--groupBy:マージルール。正規表現です。
hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --targetSize=10 --groupBy='.*/([a-z]+).*.txt' --parallelism 20シナリオ 12:コピー操作後に元のファイルを削除する場合、必要なパラメーターは何ですか?
--deleteOnSuccess を追加します。例:シナリオ 1hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --deleteOnSuccess --parallelism 10シナリオ 13:CLIでOSSのAccessKeyペアとエンドポイント情報を指定したくない場合はどうすればよいですか?
- OSSのAccessKey ID、AccessKeyシークレット、およびエンドポイントを保存する場合は、次の情報を core-site.xml ファイルに保存します。
<configuration> <property> <name>fs.jfs.cache.oss-accessKeyId</name> <value>xxx</value> </property> <property> <name>fs.jfs.cache.oss-accessKeySecret</name> <value>xxx</value> </property> <property> <name>fs.jfs.cache.oss-endpoint</name> <value>oss-cn-xxx.aliyuncs.com</value> </property> </configuration> - Amazon S3のAccessKey ID、AccessKeyシークレット、およびエンドポイントを保存する場合は、次の情報を core-site.xml ファイルに保存します。
<configuration> <property> <name>fs.s3a.access.key</name> <value>xxx</value> </property> <property> <name>fs.s3a.secret.key</name> <value>xxx</value> </property> <property> <name>fs.s3.endpoint</name> <value>s3-us-west-1.amazonaws.com</value> </property> </configuration>