Routine Load は、Apache Kafka から EMR 上の StarRocks にデータを継続的に取り込みます。ロードジョブが実行されると、StarRocks は Kafka トピックを自動的にポーリングします。SQL ステートメント (一時停止、再開、または停止) を使用して、ジョブのライフサイクルを制御できます。
Kafka から永続的で常時稼働の取り込みパイプラインが必要な場合は、Routine Load を使用します。1回限りの一括ロードが必要な場合は、代わりに Stream Load または Broker Load を使用してください。
仕組み
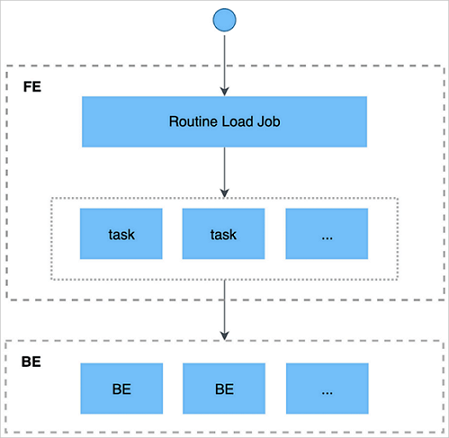
Routine Load は、2層スケジューリングモデルを使用します。
MySQL 互換クライアントを介して、フロントエンド (FE) にロードジョブを送信します。
JobScheduler は、ジョブを複数のタスクに分割します。各タスクは、Kafka パーティションの特定のサブセットをカバーします。
TaskScheduler は、各タスクをバックエンド (BE) に割り当てます。BE はタスクを Stream Load ジョブとして扱い、StarRocks にデータを書き込みます。
タスクが完了すると、BE は結果を FE に報告します。
FE は、次のバッチのために新しいタスクを作成するか、失敗したタスクを再試行します。
このサイクルは継続的に繰り返され、データフローを中断なく維持します。
基本概念
| 用語 | 説明 |
|---|---|
| RoutineLoadJob | FE に送信されるロードジョブ |
| JobScheduler | 設定されたルールに基づいて RoutineLoadJob をタスクに分割します |
| Task | RoutineLoadJob から派生した単一の作業単位 |
| TaskScheduler | バックエンドノード全体でタスク実行をスケジュールします |
このトピックの画像と一部の情報は、オープンソースの StarRocks ドキュメントの「Continuously load data from Apache Kafka」から引用しています。
前提条件
開始する前に、以下を確認してください。
Kafka バージョンが V0.10.0.0 以降であること
Kafka クラスターでは、認証を使用しないか、SSL 認証を使用します(その他の認証タイプはサポートされていません)。
メッセージが CSV または JSON 形式であること (配列タイプはサポートされていません)
CSV の場合: 各メッセージは1行であり、行は改行文字で終わってはいけません
クイックスタート
この例では、ローカルの Kafka クラスターから読み取る Routine Load ジョブを作成する方法を示します。
1. ロードジョブの作成
CREATE ROUTINE LOAD routine_load_wikipedia ON routine_wiki_edit
COLUMNS TERMINATED BY ",",
COLUMNS (event_time, channel, user, is_anonymous, is_minor, is_new, is_robot, is_unpatrolled, delta, added, deleted)
PROPERTIES
(
"desired_concurrent_number"="1",
"max_error_number"="1000"
)
FROM KAFKA
(
"kafka_broker_list"= "localhost:9092",
"kafka_topic" = "starrocks-load"
);2. ジョブが実行中であることを確認
SHOW ROUTINE LOAD FOR load_test.routine_load_wikipedia;出力で State: RUNNING を探します。ステータスが NEED_SCHEDULE の場合は、しばらく待ってからコマンドを再度実行してください。スケジューリング完了後まもなく、ジョブは RUNNING に移行します。
ロードジョブの作成
構文
CREATE ROUTINE LOAD [database.][job_name] ON [table_name]
[COLUMNS TERMINATED BY "column_separator" ,]
[COLUMNS (col1, col2, ...) ,]
[WHERE where_condition ,]
[PARTITION (part1, part2, ...)]
[PROPERTIES ("key" = "value", ...)]
FROM KAFKA
[(data_source_properties1 = 'value1',
data_source_properties2 = 'value2',
...)]HELP ROUTINE LOAD; を実行して、完全な構文リファレンスを表示します。
パラメーター
必須パラメーター
| パラメーター | 説明 |
|---|---|
job_name | ロードジョブの名前。データベース内で一意である必要があります。通常、タイムスタンプとテーブル名の形式で指定されます。オプションでデータベース名をプレフィックスとして指定します: database.job_name。 |
table_name | 送信先テーブルの名前。 |
DATA_SOURCE | データソースタイプ。KAFKA に設定します。 |
データフィルタリングとマッピング
| パラメーター | 説明 |
|---|---|
COLUMNS TERMINATED BY | ソースデータ内の列区切り文字。デフォルト: \t。 |
COLUMNS | ソース列を送信先テーブル列にマッピングし、派生列を定義します。詳細については、以下の「列マッピング」をご参照ください。 |
WHERE | 読み込み前に行をフィルターします。WHERE 条件によってフィルターされた行は、エラー行としてカウントされません。 |
PARTITION | 送信先テーブルの特定のパーティションにデータをロードします。省略した場合、StarRocks はデータを一致するパーティションに自動的にルーティングします。 |
ジョブの動作 (PROPERTIES)
| パラメーター | デフォルト値 | 説明 |
|---|---|---|
desired_concurrent_number | 3 | ジョブが分割可能な同時タスクの最大数です。0 より大きい値を指定する必要があります。 |
max_batch_interval | 10 | タスクのスケジューリング間隔(秒単位)です。有効値範囲:5~60。V1.15 以降では、この値はタスクのスケジュール頻度を制御します。実際のデータ消費時間は routine_load_task_consume_second(fe.conf 内、デフォルト値:3 秒)で制御され、タスクのタイムアウトは routine_load_task_timeout_second(fe.conf 内、デフォルト値:15 秒)で制御されます。 |
max_batch_rows | 200000 | 各タスクが読み取れる行数の上限です。200,000 以上を指定する必要があります。V1.15 以降では、このパラメーターはエラー検出ウィンドウサイズの定義にのみ使用され、そのサイズは 10 × max_batch_rows となります。 |
max_batch_size | 100 MB | 各タスクが読み取れるバイト数の上限です。有効値範囲:100 MB~1 GB。V1.15 以降で非推奨 — 代わりに routine_load_task_consume_second(fe.conf 内)をご使用ください。 |
max_error_number | 0 | サンプリングウィンドウ内で許容されるエラー行数の上限です。0 以上の値を指定する必要があります。デフォルト値の 0 は、エラー行を一切許容しないことを意味します。 |
strict_mode | 有効 | 有効化すると、非 NULL のソース値が型変換後に NULL になった場合、該当行は破棄されます。無効化するには false を設定します。 |
timezone | セッションのタイムゾーン | ロード処理中に、すべてのタイムゾーン依存関数に適用されるタイムゾーンです。 |
Kafka ソースプロパティ
| プロパティ | 必須 | 説明 |
|---|---|---|
kafka_broker_list | はい | ブローカー接続情報。形式: ip:port。複数のブローカーをコンマで区切ります。 |
kafka_topic | はい | サブスクライブする Kafka トピック。 |
kafka_partitions | いいえ | サブスクライブする特定のパーティション。 |
kafka_offsets | いいえ | サブスクライブされた各パーティションの開始オフセット。 |
property | いいえ | 追加の Kafka プロパティ。Kafka Shell の --property と同等です。 |
列マッピング
COLUMNS 句を使用して、ソース列を送信先テーブル列にマッピングします。
マッピングされた列 — ソース列をスキップまたは並べ替えます。例えば、送信先テーブルに col1、col2、col3 の列があり、ソースに4つの列があり、その4番目の列が col3 にマッピングされる場合:
COLUMNS (col2, col1, temp, col3)
-- "temp" は、3番目のソース列をロードせずに吸収するプレースホルダーです派生列 — ソースデータから列値を計算します。例えば、col4 を col1 と col2 の合計として設定するには:
COLUMNS (col2, col1, temp, col3, col4 = col1 + col2)ロードジョブの管理
ジョブステータスの表示
データベース内のすべてのロードジョブ (停止およびキャンセルされたジョブを含む) をリスト表示します。
USE <database>;
SHOW ALL ROUTINE LOAD;名前で特定の実行中のジョブを表示します。
SHOW ROUTINE LOAD FOR <database>.<job_name>;StarRocks は SHOW ROUTINE LOAD で実行中のジョブのみを表示します。完了済みおよび未開始のジョブは返されません。停止およびキャンセルされたジョブを含めるには SHOW ALL ROUTINE LOAD を使用します。
その他のオプションについては、HELP SHOW ROUTINE LOAD; または HELP SHOW ROUTINE LOAD TASK; を実行してください。
出力フィールド
SHOW ROUTINE LOAD の出力には、次の主要フィールドが含まれます。
| フィールド | 説明 |
|---|---|
State | ジョブステータス: RUNNING、PAUSED、NEED_SCHEDULE、または STOPPED |
Statistic | ジョブ作成以降の累積ロード統計 |
receivedBytes | 受信した合計バイト数 |
errorRows | ロードに失敗した行数 |
committedTaskNum | FE によってコミットされたタスク数 |
loadedRows | 正常にロードされた行数 |
loadRowsRate | 行/秒単位のロードスループット |
abortedTaskNum | バックエンドで中止されたタスク数 |
totalRows | 受信した合計行数 (エラー行とフィルタリングされた行を含む) |
unselectedRows | WHERE 条件によってフィルタリングされた行 |
receivedBytesRate | バイト/秒単位のデータ受信レート |
taskExecuteTimeMs | ミリ秒単位の合計タスク実行時間 |
ErrorLogUrls | ロードプロセスからエラーログをダウンロードするための URL |
Progress | パーティションごとの現在の Kafka コンシューマオフセット |
出力例
*************************** 1. row ***************************
Id: 14093
Name: routine_load_wikipedia
CreateTime: 2020-05-16 16:00:48
PauseTime: N/A
EndTime: N/A
DbName: default_cluster:load_test
TableName: routine_wiki_edit
State: RUNNING
DataSourceType: KAFKA
CurrentTaskNum: 1
JobProperties: {"partitions":"*","columnToColumnExpr":"event_time,channel,user,is_anonymous,is_minor,is_new,is_robot,is_unpatrolled,delta,added,deleted","maxBatchIntervalS":"10","whereExpr":"*","maxBatchSizeBytes":"104857600","columnSeparator":"','","maxErrorNum":"1000","currentTaskConcurrentNum":"1","maxBatchRows":"200000"}
DataSourceProperties: {"topic":"starrocks-load","currentKafkaPartitions":"0","brokerList":"localhost:9092"}
CustomProperties: {}
Statistic: {"receivedBytes":150821770,"errorRows":122,"committedTaskNum":12,"loadedRows":2399878,"loadRowsRate":199000,"abortedTaskNum":1,"totalRows":2400000,"unselectedRows":0,"receivedBytesRate":12523000,"taskExecuteTimeMs":12043}
Progress: {"0":"13634667"}
ReasonOfStateChanged:
ErrorLogUrls: http://172.26.**.**:9122/api/_load_error_log?file=__shard_53/error_log_insert_stmt_47e8a1d107ed4932-8f1ddf7b01ad2fee_47e8a1d107ed4932_8f1ddf7b01ad2fee, http://172.26.**.**:9122/api/_load_error_log?file=__shard_54/error_log_insert_stmt_e0c0c6b040c044fd-a162b16f6bad53e6_e0c0c6b040c044fd_a162b16f6bad53e6, http://172.26.**.**:9122/api/_load_error_log?file=__shard_55/error_log_insert_stmt_ce4c95f0c72440ef-a442bb300bd743c8_ce4c95f0c72440ef_a442bb300bd743c8
OtherMsg:
1 row in set (0.00 sec)ロードジョブの一時停止
PAUSE ROUTINE LOAD FOR <job_name>;ジョブは PAUSED 状態になります。データ取り込みは停止しますが、ジョブは終了されません。Statistic と Progress の更新が停止します。準備ができたら、RESUME ROUTINE LOAD でジョブを再開してください。
例については、HELP PAUSE ROUTINE LOAD; を実行してください。
ロードジョブの再開
RESUME ROUTINE LOAD FOR <job_name>;ジョブは、FE がタスクを再スケジュールしている間、一時的に NEED_SCHEDULE 状態になります。その後まもなく RUNNING に戻り、Statistic と Progress の更新が再開されます。
例については、HELP RESUME ROUTINE LOAD; を実行してください。
ロードジョブの停止
STOP ROUTINE LOAD FOR <job_name>;ジョブは STOPPED 状態になります。取り込みは永続的に終了されます。停止されたジョブは再開できません。停止されたジョブは SHOW ROUTINE LOAD の出力には表示されません。
例については、HELP STOP ROUTINE LOAD; を実行してください。