このトピックでは、YARN のノードラベル機能と、その使用方法について説明します。また、この機能に関するよくある質問への回答も提供します。
概要
ノードラベル機能を使用すると、クラスターにデプロイされている NodeManager を、異なるパーティションに基づいて管理できます。 1 つのノードは 1 つのパーティションにのみ属することができます。ノードラベル機能を使用して、クラスターを異なるノードを含む複数のパーティションに分割できます。デフォルトでは、ノードのパーティションパラメーターは空の文字列に設定されています(partition="")。これは、ノードが DEFAULT パーティションに属していることを意味します。
パーティションは、次のタイプに分類できます。
排他的パーティション:コンテナーは、パーティションが完全に一致する場合にのみ、排他的パーティションのノードに割り当てることができます。
非排他的パーティション:コンテナーは、パーティションが完全に一致する場合、非排他的パーティションのノードに割り当てることができます。コンテナーを割り当てるパーティションが指定されていない場合、または DEFAULT パーティションが指定されている場合は、アイドルリソースを持つ非排他的パーティションのノードにコンテナーを割り当てることができます。
Capacity Scheduler のみがノードラベル機能をサポートしています。スケジューラまたはコンピューティングエンジンの node-label-expression パラメーターを構成して、キュー内のコンテナーを、キューがアクセスできるパーティションに割り当てることができます。
ノードラベルの詳細については、「YARN ノードラベル」をご参照ください。
制限事項
クラスターのマイナーバージョンが E-MapReduce(EMR)V5.11.1 または EMR V3.45.1 より前の場合、
yarn-site.xmlファイルのyarn.node-labels.configuration-type設定項目の値が centralized である場合、このトピックの手順に従ってノードラベル機能を使用できます。クラスターが EMR V5.11.1、EMR V3.45.1、または EMR V5.11.1 または EMR V3.45.1 より後のマイナーバージョンの場合、EMR コンソールで YARN パーティションを管理できます。詳細については、「EMR コンソールで YARN パーティションを管理する」をご参照ください。
ノードラベル機能の使用
EMR コンソールでノードラベル機能を有効にする
[構成] タブの YARN サービスページで、yarn-site.xml タブをクリックし、次の表に示す設定項目を追加して、[保存] をクリックします。次に、ResourceManager を再起動して、構成を有効にします。
キー | 値 | 説明 |
yarn.node-labels.enabled | true | ノードラベル機能を有効にするかどうかを指定します。 |
yarn.node-labels.fs-store.root-dir | /tmp/node-labels | ノードラベルのデータが保存されるディレクトリを指定します。デフォルトでは、ノードラベルは集中モードで構成されます。このモードでは、ノードラベルのストレージディレクトリを指定できます。 |
ノードラベル機能の動作原理をよりよく理解するために、このトピックでは、集中モードでノードラベルを構成する方法について説明します。 EMR V5.11.1、EMR V3.45.1、または EMR V5.11.1 または EMR V3.45.1 より後のマイナーバージョンでは、
yarn.node-labels.configuration-typeパラメーターはデフォルトで distributed に設定されています。この場合、コマンドを手動で追加する必要はありません。代わりに、EMR コンソールで YARN パーティションを管理できます。詳細については、「EMR コンソールで YARN パーティションを管理する」をご参照ください。ノードラベルの詳細については、Apache Hadoop ドキュメントの「YARN ノードラベル」を参照してください。yarn.node-labels.fs-store.root-dir パラメーターを URL ではなくディレクトリに設定すると、
fs.defaultFS変数で指定されたファイルシステムが使用されます。これは、${fs.defaultFS}/tmp/node-labelsの構成と同等です。ほとんどの場合、EMR で使用されるファイルシステムは Hadoop 分散ファイルシステム(HDFS)です。
コマンドを実行してパーティションを作成し、ノードをパーティションにマップする
スケールアウトされたノードグループにある NodeManager が存在する各ノードのパーティションをシステムが自動的に指定するようにするには、1 つ以上のパーティションを作成し、ビジネス要件に基づいて yarn rmadmin -replaceLabelsOnNode コマンドをノードグループのブートストラップスクリプトに追加します。このようにして、コマンドは NodeManager が起動された後に実行されます。
サンプルコード:
# YARN のデフォルトの管理者 hadoop としてログオンします。
sudo su - hadoop
# クラスターにパーティションを作成します。
yarn rmadmin -addToClusterNodeLabels "DEMO"
yarn rmadmin -addToClusterNodeLabels "CORE"
# クラスター内の YARN ノードをクエリします。
yarn node -list
# 各ノードをパーティションにマップします。
yarn rmadmin -replaceLabelsOnNode "core-1-1.c-XXX.cn-hangzhou.emr.aliyuncs.com=DEMO"
yarn rmadmin -replaceLabelsOnNode "core-1-2.c-XXX.cn-hangzhou.emr.aliyuncs.com=DEMO"コマンドの実行後、ResourceManager の Web UI で構成結果を確認します。
ノードの構成
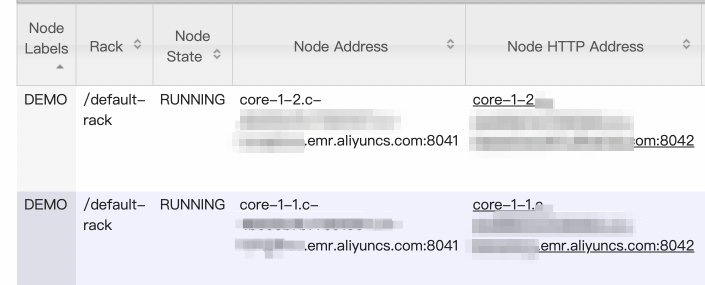
ノードラベルの構成
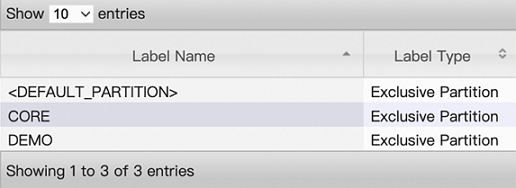
Capacity Scheduler を使用して、キューとジョブがアクセスできるパーティションを構成する
Capacity Scheduler を使用してパーティションを構成する前に、yarn-site.xml ファイルの yarn.resourcemanager.scheduler.class パラメーターが org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler に設定されていることを確認してください。
キューに対してアクセス可能なパーティションと各パーティションで使用可能なリソース容量を指定するには、次の表に示す設定項目を capacity-scheduler.xml ファイルに追加します。<queue-path> はキューのパスに、<label> はパーティションの名前に置き換えます。 DEFAULT パーティションにキューがアクセスできるようにするには、yarn.scheduler.capacity.<queue-path>.accessible-node-labels.<label>.capacity および yarn.scheduler.capacity.<queue-path>.accessible-node-labels.<label>.maximum-capacity 設定項目のデフォルト値を使用します。
設定項目 | 値 | 説明 |
yarn.scheduler.capacity.<queue-path>.accessible-node-labels | パーティションの名前。複数のパーティションはカンマ(,)で区切ります。 | 特定のキューがアクセスできるパーティション。 |
yarn.scheduler.capacity.<queue-path>.accessible-node-labels.<label>.capacity | 有効な値の詳細については、yarn.scheduler.capacity.<queue-path>.capacity 設定項目を参照してください。 | 特定のキューで使用可能な、特定のパーティションのリソース容量。 重要 この構成をキューに対して有効にするには、対応するすべての祖先キューのリソース容量を指定する必要があります。 |
yarn.scheduler.capacity.<queue-path>.accessible-node-labels.<label>.maximum-capacity | 有効な値の詳細については、yarn.scheduler.capacity.<queue-path>.maximum-capacity 設定項目を参照してください。デフォルト値:100。 | 特定のキューで使用可能な、特定のパーティションの最大リソース容量。 |
yarn.scheduler.capacity.<queue-path>.default-node-label-expression | パーティションの名前。デフォルト値は空の文字列で、DEFAULT パーティションを示します。 | コンテナーにパーティションが指定されていない場合に、特定のキューによって送信されたジョブのコンテナーに割り当てられるデフォルトパーティション。 |
キューで使用可能なパーティションの実際のリソース容量を 0 より大きい値に設定するには、対応するすべての祖先キューに同じリソース容量を指定する必要があります。これは、
yarn.scheduler.capacity.<queue-path>.accessible-node-labels.<label>.capacity設定項目のデフォルト値がすべてのキューで 0 であるためです。ルートキューのyarn.scheduler.capacity.root.accessible-node-labels.<label>.capacity設定項目を 100 に設定する必要があります。このようにして、すべての子孫キューで使用可能なパーティションの実際のリソース容量を 0 より大きくすることができます。理論的には、ルートキューの設定項目を 0 より大きい値に設定するだけで済みます。ただし、設定項目を 100 より小さい値に設定すると、子孫キューの実際のリソース容量は計算値よりも小さくなります。この場合、構成は無意味です。キューの祖先キューで使用可能なパーティションのデフォルトリソース容量が 0 に設定されている場合、キューで使用可能なパーティションの実際のリソース容量は依然として 0 です。ルートキューの
yarn.scheduler.capacity.root.accessible-node-labels.<label>.capacity設定項目を 0 より大きい値に設定した場合、同じパーティション内の対応する子キューのリソース容量の合計は 100 である必要があります。同じルールがyarn.scheduler.capacity.<queue-path>.capacity設定項目にも適用されます。次のサンプルコードは、パーティションとリソース容量を構成する方法の例を示しています。
<configuration> <!-- ノードラベルに関連する設定項目を capacity-scheduler.xml ファイルに追加します。 --> <property> <!-- 必須。 DEMO パーティションがデフォルトキューにアクセスできるように指定します。 --> <name>yarn.scheduler.capacity.root.default.accessible-node-labels</name> <value>DEMO</value> </property> <property> <!-- 必須。 DEMO パーティションのデフォルトキューのすべての祖先キューで使用可能なリソース容量を指定します。 --> <name>yarn.scheduler.capacity.root.accessible-node-labels.DEMO.capacity</name> <value>100</value> </property> <property> <!-- 必須。 DEMO パーティションのデフォルトキューで使用可能なリソース容量を指定します。 --> <name>yarn.scheduler.capacity.root.default.accessible-node-labels.DEMO.capacity</name> <value>100</value> </property> <property> <!-- オプション。 DEMO パーティションのデフォルトキューで使用可能な最大リソース容量を指定します。デフォルト値は 100 です。 --> <name>yarn.scheduler.capacity.root.default.accessible-node-labels.DEMO.maximum-capacity</name> <value>100</value> </property> <property> <!-- オプション。デフォルトキューによって送信されたジョブのコンテナーが送信されるデフォルトパーティションを指定します。デフォルト値は空の文字列で、DEFAULT パーティションを示します。 --> <name>yarn.scheduler.capacity.root.default.default-node-label-expression</name> <value>DEMO</value> </property> <configuration>
capacity-scheduler.xml ファイルを保存します。YARN サービス ページの [ステータス] タブで、ResourceManager の refreshQueues 機能を使用して、スケジューラ キューの構成をリアルタイムで更新します。更新が完了したら、ResourceManager の Web UI で構成結果を確認します。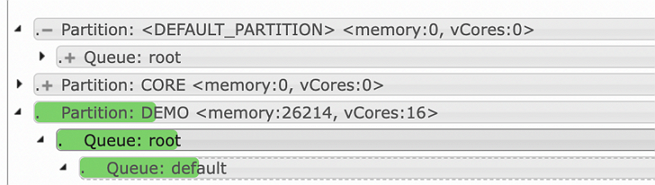
スケジューラキューのデフォルトのパーティション機能に加えて、コンピューティングエンジン (Tez を除く) はノード label 機能もサポートしています。次の表は、さまざまなエンジンに必要なパラメーターについて説明しています。
エンジン | 構成項目 | 説明 |
MapReduce | mapreduce.job.node-label-expression | ジョブのすべてのコンテナーで使用されるノードを含むデフォルトのパーティション。 |
mapreduce.job.am.node-label-expression | ApplicationMaster によって使用されるノードを含むパーティション。 | |
mapreduce.map.node-label-expression | マップ タスクによって使用されるノードを含むパーティション。 | |
mapreduce.reduce.node-label-expression | reduce タスクによって使用されるノードを含むパーティション。 | |
Spark | spark.yarn.am.nodeLabelExpression | ApplicationMaster によって使用されるノードを含むパーティション。 |
spark.yarn.executor.nodeLabelExpression | Executor によって使用されるノードを含むパーティション。 | |
Flink | yarn.application.node-label | ジョブのすべてのコンテナーで使用されるノードを含むデフォルトのパーティション。 |
yarn.taskmanager.node-label | TaskManager によって使用されるノードを含むパーティション。このパラメーターは、EMR V3.44.0、EMR V5.10.0、または EMR V3.44.0 あるいは EMR V5.10.0 以降のマイナー バージョンのクラスターで Apache Flink 1.15.0 以降を使用する場合にのみサポートされます。 |
よくある質問
HA クラスターで集中モードで構成されたノード label のデータが分散ファイルシステムに保存されるのはなぜですか。
HA クラスターでは、ResourceManager は複数のノードにデプロイされます。 デフォルトでは、オープンソースの Hadoop はノード label のデータを file:///tmp/hadoop-yarn-${user}/node-labels/ パスに保存します。 ノードのフェールオーバーが発生した場合、アクティブ状態の新しいノードはローカルパスからノード label のデータを読み取ることができません。 yarn.node-labels.fs-store.root-dir パラメーターを、/tmp/node-labels や ${fs.defaultFS}/tmp/node-labels など、分散ファイルシステムのストレージディレクトリに設定する必要があります。 EMR のデフォルトのファイルシステムは HDFS です。 詳細については、この Topic のノード label の使用セクションをご参照ください。
yarn.node-labels.fs-store.root-dir パラメーターを分散ファイルシステムのストレージディレクトリに設定する前に、ファイルシステムが想定どおりに動作し、hadoop ユーザーがファイルシステムからデータを読み取り、ファイルシステムにデータを書き込むことができることを確認してください。 そうしないと、ResourceManager を起動できません。
ノードをパーティションにマップするときに、NodeManager のポートが指定されないのはなぜですか。
EMR クラスターのノードには、NodeManager が 1 つだけ存在します。 したがって、NodeManager のポートを指定する必要はありません。 NodeManager の無効なポートまたはランダムなポートを指定すると、yarn rmadmin -replaceLabelsOnNode コマンドを実行するときに、指定したノードを指定したパーティションにマップできません。 yarn node -list -showDetails コマンドを実行して、ノードが属するパーティションをクエリできます。
ノード label のユースケースシナリオは何ですか。
ほとんどの場合、ノード label 機能は EMR クラスターでは有効になっていません。 これは、オープンソースの Hadoop YARN サービスによって収集された統計情報が、ノードのパーティションマッピングではなく、DEFAULT パーティションのステータスのみを考慮しているためです。 これにより、O&M の複雑さが増します。 また、パーティションスケジューリングでは、クラスター内のリソースが十分に活用されない場合があります。 これにより、リソースが無駄になります。 ノード label はさまざまなシナリオに適しています。 たとえば、バッチジョブとストリーミングジョブを分離して、ジョブがクラスター内の異なるパーティションで同時に実行できるようにすることができます。 パーティションマッピングが実行された後、重要度の高いジョブを、柔軟に追加されていないノードで実行できます。 クラスター内のノードの仕様が異なる場合は、異なるパーティションのノードでジョブを実行して、リソースの不均衡を防ぐことができます。