E-MapReduce (EMR) V2.4.0 以降では、クラスターごとにデフォルトで使用される MySQL データベースを、集中管理型の Hive メタストアに置き換えることができます。この集中管理型メタストアはクラスターのライフサイクルとは独立してメタデータを永続化するため、計算リソースとストレージの分離および複数クラスター間でのデータ共有が可能になります。
組み込みの ApsaraDB RDS メタストアには固定制限があります: 合計容量 200 MiB、1 時間あたり最大 720,000 クエリ、1 時間あたり最大 144,000 更新処理。また、スペックアップはできません。本番ワークロードまたは大規模なデータセットを利用する場合は、専用の ApsaraDB RDS インスタンスを別途作成し、そのインスタンス上でメタストアをホストすることを推奨します。
Hive 統合メタデータのストレージタイプは段階的に廃止されます。新しい EMR コンソールでは、Data Lake Formation (DLF) 統合メタデータのストレージタイプへ移行してください。新規の EMR ユーザーの場合は、最初から DLF 統合メタデータをご利用ください。詳細については、「EMR メタデータの移行」をご参照ください。
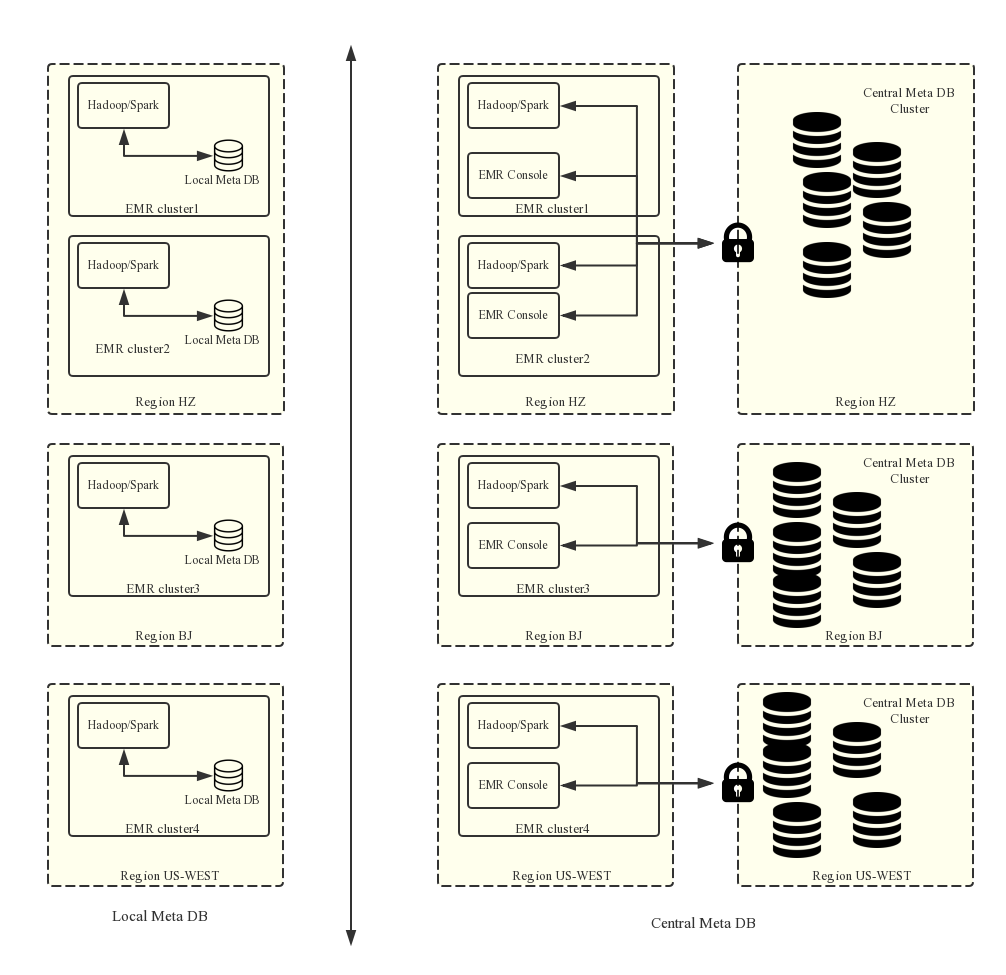
ローカルメタストアと統合メタストアの比較
| ディメンション | ローカルメタストア(デフォルト) | 統合メタストア |
|---|---|---|
| メタデータのライフサイクル | クラスターに紐づく — クラスターがリリースされると削除される | 独立 — クラスターがリリースされた後も継続して保持される |
| クラスターのリリース | リリース前に手動でメタデータをエクスポートする必要がある | メタデータの移行なしでクラスターをリリースできる |
| データ共有 | クラスター間で共有されない | すべてのクラスターが同一のメタストアから読み取りを行う |
| ストレージバックエンド | クラスターノード上の MySQL | ApsaraDB RDS(マネージド) |
| コンソールによる管理 | 利用不可 — クラスター上の Hue を使用する | EMR コンソールから利用可能 |
| 推奨利用シーン | 迅速なテストおよび開発 | 本番環境、共有ワークロード、および計算リソースとストレージの分離 |
メリット
永続的なメタデータストレージ
ローカルメタストアでは、メタデータがクラスターノード上の MySQL に格納され、クラスターがリリースされると(不要となった従量課金クラスターを含む)すべて削除されます。一方、統合メタデータでは、クラスターがリリースされた後もメタストアが存続します。クラスターをリリースする前、または Object Storage Service (OSS) や Hadoop 分散ファイルシステム (HDFS) のデータを削除する前に、対応するテーブルおよびデータベースをメタストアから明示的に削除することで、不要なメタデータの蓄積を防ぐことができます。
計算リソースとストレージの分離
EMR では、HDFS と比較して大幅に低コストな OSS 上にデータを保存できます。クラスターは純粋な計算リソースとして機能し、アイドル状態になった時点でリリース可能です。この場合、メタデータの移行は一切不要です。
データ共有
データが OSS 上に存在する場合、すべてのクラスターが共有メタストアを介して直接クエリを実行できます。メタデータの移行や再構成は不要であり、異なるサービスを実行する EMR クラスターが同一のデータセットに同時にアクセスできます。
留意事項
-
パブリック IP アドレスが必要: メタストアへのアクセスはパブリック IP アドレス経由のみ可能です。設定前にご利用のクラスターにパブリック IP アドレスが正しく設定されていることを確認してください。また、設定後にパブリック IP アドレスを変更しないでください。IP アドレスの変更により、データベースのホワイトリストが無効になります。
-
ローカルメタストアはコンソールではなく Hue でのみ管理可能: ローカルメタストアは EMR コンソールからは管理できません。代わりに、クラスター上にデプロイされた Hue ツールをご利用ください。
統合メタデータを使用したクラスターの作成
以下のいずれかの方法をご利用ください。
EMR コンソール
クラスターを作成する際、基本設定 ステップで タイプ パラメーターを 統合メタベース に設定します。詳細については、「クラスターの作成」をご参照ください。
CreateClusterV2 API
CreateClusterV2 操作を呼び出し、useLocalMetaDb パラメーターを false に設定します。
テーブルの管理
詳細については、「Hive メタデータの基本操作」をご参照ください。
メタストアの使用量および制限の確認
-
Alibaba Cloud EMR コンソール にログインします。
-
画面右上のナビゲーションバーで、ご利用のクラスターが配置されているリージョンを選択し、リソースグループを指定します。
-
メタデータ タブをクリックします。
-
左側のナビゲーションウィンドウで、メタベース情報 をクリックします。
メタベース情報 ページには、ご利用の ApsaraDB RDS インスタンスの現在の使用量および制限が表示されます。