Impala は、高パフォーマンスと低レイテンシを特長とするリアルタイム SQL クエリエンジンです。Impala では、SELECT 句、JOIN 句、および集計関数を使用して、Hadoop Distributed File System(HDFS)または HBase に保存されているデータをリアルタイムでクエリできます。
背景情報
Impala は、Apache Hive と同じメタデータ、SQL 構文(Hive SQL)、および Open Database Connectivity(ODBC)ドライバーを使用して、バッチ処理またはリアルタイムクエリのための使い慣れた統合プラットフォームを提供します。
使用上の注意
Impala の使用時に Hive テーブルのパーティションを削除する場合は、Impala または Hive CLI でコマンドを実行してパーティションを削除します。システムファイルパスからパーティションディレクトリを直接削除すると、Hive テーブルが使用できなくなります。
メリット
レイテンシを最小限に抑えるため、Impala は MapReduce ではなく分散クエリエンジンを使用してデータにアクセスします。このエンジンは、リレーショナルデータベース管理システム(RDBMS)のエンジンに似ています。このエンジンのパフォーマンスは、クエリと構成のタイプによって異なり、Hive よりも桁違いに高速です。
Hadoop と比較して、Impala は SQL クエリに次のメリットをもたらします。
データノードでローカル処理が実行されるため、ネットワークボトルネックを回避できます。
データ形式を変換する必要はありません。そのため、データ形式の変換に対して課金されることはありません。
単一のオープンで統合されたメタデータストレージを使用できます。
抽出、変換、ロード(ETL)操作の遅延なしに、すべてのデータをすぐにクエリできます。
すべてのハードウェアが Impala クエリと MapReduce に使用されます。
スケーラビリティを実装するには、単一の工作機械のみが必要です。
Impala の詳細については、「Apache Impala」をご参照ください。
Impala コンポーネント
次の図は、E-MapReduce(EMR)クラスターの Impala のコンポーネントを示しています。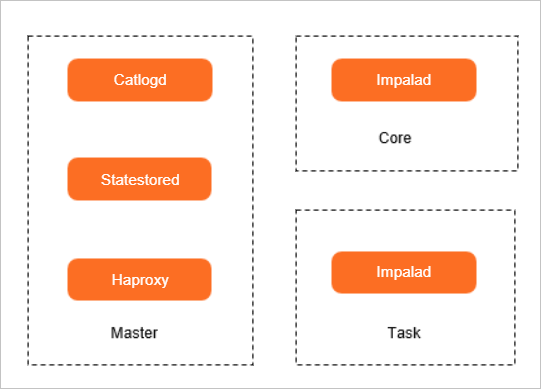
Impala は、次のコンポーネントで構成されています。
Impalad
Impalad プロセスはコアノードとタスクノードにデプロイされ、スケーリングできます。
Impala のコアコンポーネントは、各ノードで実行される Impala Daemon です。Impala Daemon は、Impalad という名前のプロセスで表されます。Impala Daemon は、ファイルからのデータの読み取りとファイルへのデータの書き込み、
impala-shellコマンドを使用するか、Hue、Java Database Connectivity(JDBC)、または ODBC から送信されたクエリステートメントの受信、クエリの並列化、クラスターの Impala ノードへのタスクの分散に使用されます。さらに、Impala Daemon は、ローカルで計算されたクエリ結果をコーディネーターノードに返すためにも使用できます。Statestored
Statestored プロセスは、master-1-1 ノードにデプロイされます。
StateStore Daemon は、Statestored という名前のプロセスで表されます。StateStore Daemon は、クラスター内のすべての Impalad プロセスのヘルスステータスを管理し、ステータス結果をすべての Impalad プロセスに転送するために使用されます。ノードの例外、ネットワークの例外、またはソフトウェアの問題が原因で Impalad プロセスが使用できない場合、StateStore Daemon は異常を他の Impalad プロセスに通知します。新しいクエリ要求が開始されると、クエリ要求は使用できない Impalad プロセスに配信されません。
Catalogd
Catalogd プロセスは、master-1-1 ノードにデプロイされます。
Catalog Daemon は、Catalogd という名前のプロセスで表されます。Catalog Daemon は、各 Impalad プロセスのメタデータの変更を同じクラスター内の他の Impalad プロセスに同期するために使用されます。すべての要求は Statestored プロセスを使用して配信されるため、StateStore Daemon と Catalog Daemon を同じノードで実行することをお勧めします。