すべてのデータを単一の高性能ストレージレイヤーに保存すると、コストが高くなり、非効率です。古いデータはアクセス頻度が低く、ミリ秒単位のクエリ遅延を必要としません。最新かつ頻繁にアクセスされるデータを Tablestore にルーティングし、すべてのデータを Delta Lake にアーカイブすることで、高速ストレージのコストは必要な箇所にのみ発生し、全データセットを低コストでクエリ可能に保つことができます。
本トピックでは、データ作成時刻に基づくホットデータとコールドデータの分離について説明します。アクセス頻度に基づく分類については、関連ドキュメントをご参照ください。
基本概念
ホットデータ、ウォームデータ、コールドデータ は、アクセス頻度に基づいてデータを分類するものです。ホットデータは最近書き込まれ、頻繁にアクセスされます。時間の経過とともにアクセス頻度が低下すると、データはウォームデータを経て最終的にコールドデータになります。コールドデータには以下の 4 つの特徴があります。
-
大容量:長期間にわたり蓄積され、多くの場合永続的に保持されます。
-
低アクセス頻度:クエリがまれであり、数十秒以上の遅延が許容可能で、非同期処理が受け入れられます。
-
バッチ操作のみ:一括で書き込みおよび削除され、更新は行われません。クエリは特定の条件に一致するデータのみを読み取り、条件は複雑ではありません。
-
低管理コスト:アクセス頻度が低いため、低コストで高圧縮のストレージに適しています。
Time to live (TTL) は Tablestore の属性で、保存期間を超えたデータバージョンを持つ行を自動的に削除します。ソーステーブルの TTL を短く設定すると、ホットデータのみが残ります。TTL を超えた行はバージョン番号に基づいて削除されますが、Delta Lake は全履歴を保持します。
Change Data Capture (CDC) は、データソースに対する挿入、更新、削除操作を追跡し、ダウンストリームのコンシューマーにストリーミングする仕組みです。Tablestore Tunnel サービスは CDC ストリームを提供し、Streaming SQL がこれを消費して Delta Lake を同期状態に保ちます。
ユースケース
ホット・コールドデータ分離は、自然な時間ディメンションを持ち、最近のデータがクエリトラフィックの大半を占めるデータに対して特に有効です。
-
インスタントメッセージ (IM):ユーザーは主に最近のメッセージをクエリし、過去のメッセージはたまに取得されます。例:DingTalk。
-
モニタリング:最新のメトリックは継続的に確認されますが、過去のデータはインシデント調査やレポート作成時のみクエリされます。例:Cloud Monitor。
-
課金:ユーザーは主に直近 1 ヶ月の請求書を閲覧し、1 年前の請求書はほとんど開かれません。例:Alipay。
-
IoT (モノのインターネット):最近報告されたデバイステレメトリは頻繁に分析されますが、過去のデバイスデータはまれにしかアクセスされません。
-
アーカイブデータ:読み書きは容易だがクエリコストが高いデータを、低コストまたは高圧縮ストレージにアーカイブすることでコストを削減できます。
ストレージ階層の選択
| Tablestore (ホットストレージ) | Delta Lake (コールド/全データストレージ) | |
|---|---|---|
| 最適な用途 | 頻繁にアクセスされ、遅延の影響を受けやすい最新データ | 全データセットの保持と履歴分析 |
| クエリ遅延 | テラバイト規模でミリ秒単位 | データ量に応じて数十秒以上 |
| データ保持 | TTL により制御され、古いデータは自動削除 | 全データを保持し、自動期限切れなし |
| 書き込みモデル | CDC 経由で put、update、delete をサポート | ストリーミングジョブによる append および merge |
| コストプロファイル | 1 GB あたりのコストが高く、速度に最適化 | 1 GB あたりのコストが低く、容量に最適化 |
テラバイト規模の効率的なクエリのために、ホットデータは Tablestore に保存してください。コールドデータ(または全データセット)は Delta Lake に保存します。Tablestore の TTL を調整して、ホットデータの境界を制御します。
仕組み
Tablestore (OrderSource)
│
│ CDC tunnel (増分変更)
▼
Streaming SQL job (Header node)
│
│ MERGE INTO (PUT / UPDATE / DELETE)
▼
Delta Lake (delta_orders, /delta/orders)-
注文データが Tablestore ソーステーブル
OrderSourceに書き込まれます。 -
OrderSource上の CDC トンネルが、すべての挿入、更新、削除をキャプチャします。 -
EMR Header ノード上の Streaming SQL ジョブがトンネルを読み取り、変更内容を Delta Lake シンク
delta_ordersにマージします。 -
Delta Lake は完全なデータセットを保持します。一方、Tablestore は TTL ウィンドウ内のデータのみを保持し、これがホットティアとなります。
ホットデータとコールドデータの分離
本例では注文テーブルを使用して、全体の設定手順を説明します。90 日分の注文データを Tablestore および Delta Lake の両方にストリーミングし、その後 Tablestore の TTL を 30 日に短縮してホットティアを分離します。
前提条件
開始前に、以下の要件を満たしていることを確認してください。
-
Streaming SQL が有効化された EMR クラスター
-
Tablestore インスタンスおよびテーブルとトンネルを作成する権限
-
サンプルデータを書き込むための Tablestore SDK for Java
ステップ 1:ソーステーブルの設定とサンプルデータのロード
プライマリキー列 (UserId および OrderId) と属性列 (price および timestamp) を持つ、OrderSource という名前の Tablestore テーブルを作成します。
Tablestore SDK for Java の BatchWriteRow 操作を使用して、注文データをテーブルに書き込みます。本例では、タイムスタンプ範囲は直近 90 日間 (2020-02-26 ~ 2020-05-26) をカバーし、レコード総数は 3,112,400 件です。
データ書き込み時に、timestamp 列を Tablestore 行のバージョン番号属性列として設定します。テーブルに TTL を設定し、保存期間を超えたバージョン番号を持つ行が自動的に削除されるようにします。
ステップ 2:CDC トンネルの作成
Tablestore コンソールで、OrderSource テーブル上に増分同期用のトンネルを作成します。トンネル ID を記録しておき、Streaming SQL の構成で使用します。
ステップ 3:Streaming SQL の起動とソース・シンクテーブルの作成
ご利用の EMR クラスターの Header ノードで、Streaming SQL インタラクティブシェルを起動します。
streaming-sql --master yarn --use-emr-datasource --num-executors 16 --executor-memory 4g --executor-cores 4以下のコマンドを実行して、Tablestore ソーステーブル、Delta Lake シンク、増分スキャンビュー、およびストリーミングジョブを作成します。
-- 1. Tablestore ソーステーブルの作成。
DROP TABLE IF EXISTS order_source;
CREATE TABLE order_source
USING tablestore
OPTIONS(
endpoint="http://vehicle-test.cn-hangzhou.vpc.tablestore.aliyuncs.com",
access.key.id="",
access.key.secret="",
instance.name="vehicle-test",
table.name="OrderSource",
catalog='{"columns": {"UserId": {"col": "UserId", "type": "string"}, "OrderId": {"col": "OrderId", "type": "string"}, "price": {"col": "price", "type": "double"}, "timestamp": {"col": "timestamp", "type": "long"}}}'
);
-- 2. Delta Lake シンクの作成。
DROP TABLE IF EXISTS delta_orders;
CREATE TABLE delta_orders(
UserId string,
OrderId string,
price double,
timestamp long
)
USING delta
LOCATION '/delta/orders';
-- 3. ソーステーブルの増分スキャンビューの作成。
-- tunnel.id: ステップ 2 で作成したトンネルの ID。
-- maxoffsetsperchannel: トンネル経由で各パーティションに書き込める最大データ量。
CREATE SCAN incremental_orders ON order_source USING STREAM
OPTIONS(
tunnel.id="324c6bee-b10d-4265-9858-b829a1b71b4b",
maxoffsetsperchannel="10000"
);
-- 4. ストリーミングジョブの開始。
-- このジョブは CDC 変更 (PUT / UPDATE / DELETE) を delta_orders にマージします。
-- __ots_record_type__ は Tablestore ストリーミングソースから提供される事前定義列で、
-- 行操作タイプを識別します。
CREATE STREAM orders_job
OPTIONS (
checkpointLocation='/delta/orders_checkpoint',
triggerIntervalMs='3000'
)
MERGE INTO delta_orders
USING incremental_orders AS delta_source
ON delta_orders.UserId=delta_source.UserId AND delta_orders.OrderId=delta_source.OrderId
WHEN MATCHED AND delta_source.__ots_record_type__='DELETE' THEN
DELETE
WHEN MATCHED AND delta_source.__ots_record_type__='UPDATE' THEN
UPDATE SET UserId=delta_source.UserId, OrderId=delta_source.OrderId, price=delta_source.price, timestamp=delta_source.timestamp
WHEN NOT MATCHED AND delta_source.__ots_record_type__='PUT' THEN
INSERT (UserId, OrderId, price, timestamp) VALUES (delta_source.UserId, delta_source.OrderId, delta_source.price, delta_source.timestamp);上記 4 つの SQL ステートメントは、それぞれ以下の処理を行います。
| ステートメント | 処理内容 |
|---|---|
| Tablestore ソーステーブルの作成 | order_source を catalog パラメーターに基づくスキーマ (UserId、OrderId、price、timestamp 列) で定義します。 |
| Delta Lake シンクの作成 | delta_orders を定義し、Delta ファイルの保存場所として /delta/orders を指定します。 |
| 増分スキャンビューの作成 | CDC トンネル上のストリーミングビューとして incremental_orders を定義します。tunnel.id はトンネルを識別し、maxoffsetsperchannel はバッチごとのパーティションあたりフェッチ量の上限を設定します。 |
| ストリーミングジョブの開始 | incremental_orders から読み取り、プライマリキー (UserId、OrderId) を基に変更を delta_orders にマージします。CDC 操作タイプ (PUT、UPDATE、DELETE) を対応する Delta Lake 操作に変換します。 |
ステップ 4:初期同期の検証と TTL の設定
TTL を変更する前に、両方のテーブルに同じ件数のレコードが含まれていることを確認します。
order_source および delta_orders のレコード件数をクエリします。件数は一致している必要があります (各 3,112,400 件)。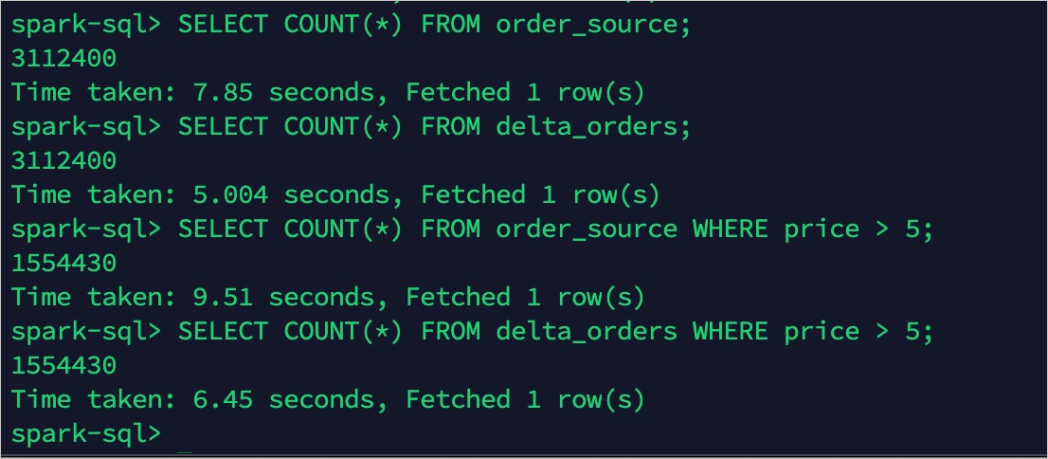
OrderSource テーブルの TTL を 30 日に設定します。TTL が適用されると、以下のようになります。
-
order_sourceは直近 30 日分のレコードのみを保持します:1,017,004 件。 -
delta_ordersは引き続き全レコードを保持します:3,112,400 件。
これにより、ホットデータとコールドデータが分離されました。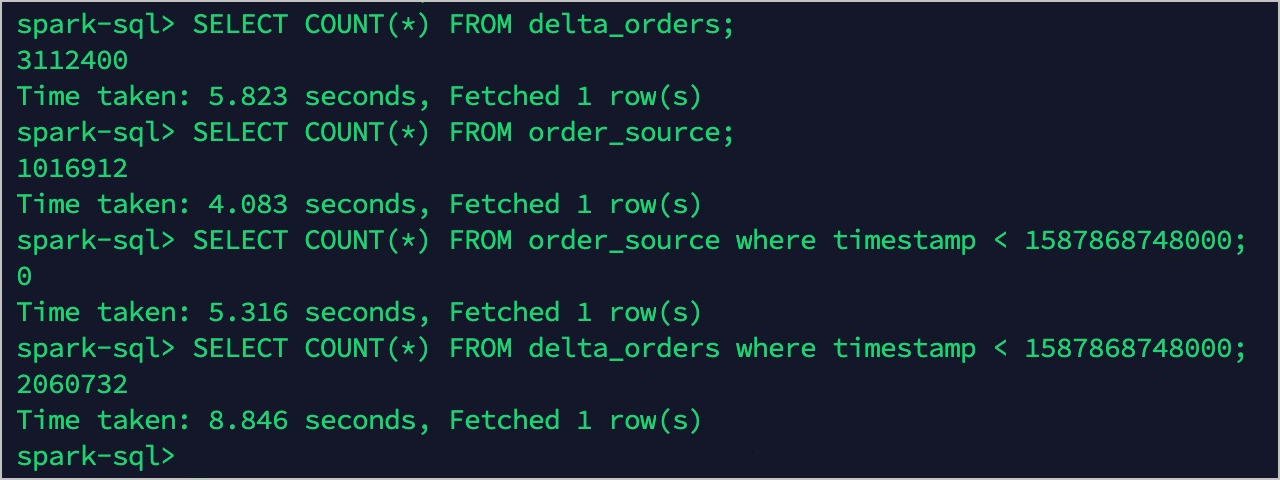
次のステップ
-
低遅延で結果を得るために、Tablestore の
order_sourceから直接ホットデータをクエリします。 -
コールドデータまたは全履歴データセットを、Delta Lake の
delta_ordersからクエリします。 -
ストレージコストおよびクエリ遅延要件の変化に応じて、Tablestore の TTL を調整してホットデータの境界をシフトします。