このトピックでは、Hive に関するよくある質問への回答を提供します。
説明
- Hive ジョブに関連する問題のトラブルシューティング方法については、Hive ジョブに関連する問題のトラブルシューティング をご参照ください。
- HiveMetaStore および HiveServer に関連する問題のトラブルシューティング方法については、Hive サービスに関連する問題のトラブルシューティング をご参照ください。
- ジョブが長時間待機状態になっている場合はどうすればよいですか?
- マップステージで小さなファイルが読み取られる場合はどうすればよいですか?
- Reduce タスクに時間がかかる場合はどうすればよいですか?
- 同時に実行できる Hive ジョブの最大数をどのように見積もりますか?
- Hive で作成された外部テーブルにデータが含まれていないのはなぜですか?
ジョブが長時間待機状態になっている場合はどうすればよいですか?
問題を特定するには、次の手順を実行します。
- E-MapReduce(EMR)コンソールの [アクセスリンクとポート] タブに移動し、YARN UI に対応する [アクセス URL] 列のリンクをクリックします。
- アプリケーションの ID をクリックします。
- [トラッキング URL] の横にあるリンクをクリックします。複数のジョブが待機状態になっています。

- 左側のナビゲーションペインで、[スケジューラ] をクリックします。キュー内のリソースがすべて占有されているかどうか、または現在のジョブに時間がかかっているかどうかを確認できます。キューに十分なリソースがない場合は、待機状態のジョブを現在のキューからアイドル状態のキューに切り替えることができます。現在のジョブに時間がかかる場合は、コードを最適化します。
マップステージで小さなファイルが読み取られる場合はどうすればよいですか?
問題を特定するには、次の手順を実行します。
- EMR コンソールの [アクセスリンクとポート] タブに移動し、YARN UI に対応する [アクセス URL] 列のリンクをクリックします。
- アプリケーションの ID をクリックします。各マップタスクで読み取られるデータのサイズは、[マップタスク] ページで確認できます。次の図に示すように、読み取られるデータのサイズは 2 バイトです。ほとんどのマップタスクで読み取られるファイルのデータサイズが小さい場合は、小さなファイルをマージします。

各マップタスクのログで詳細を確認することもできます。
Reduce タスクに時間がかかる場合はどうすればよいですか?
問題を特定するには、次の手順を実行します。
- EMR コンソールの [アクセスリンクとポート] タブに移動し、YARN UI に対応する [アクセス URL] 列のリンクをクリックします。
- アプリケーションの ID をクリックします。
- [Reduce タスク] ページで、完了時間で Reduce タスクを降順に並べ替え、実行時間が最も長い上位の Reduce タスクを見つけます。

- 上位の Reduce タスクの名前をクリックします。
- タスク詳細ページの左側のナビゲーションペインで、[カウンター] をクリックします。
 現在の Reduce タスクの [Reduce 入力レコード] と [Reduce シャッフルバイト] メトリックの値を表示します。2 つのメトリックの値が他のタスクの 2 つのメトリックの値よりも大きい場合、データの偏りが発生しています。
現在の Reduce タスクの [Reduce 入力レコード] と [Reduce シャッフルバイト] メトリックの値を表示します。2 つのメトリックの値が他のタスクの 2 つのメトリックの値よりも大きい場合、データの偏りが発生しています。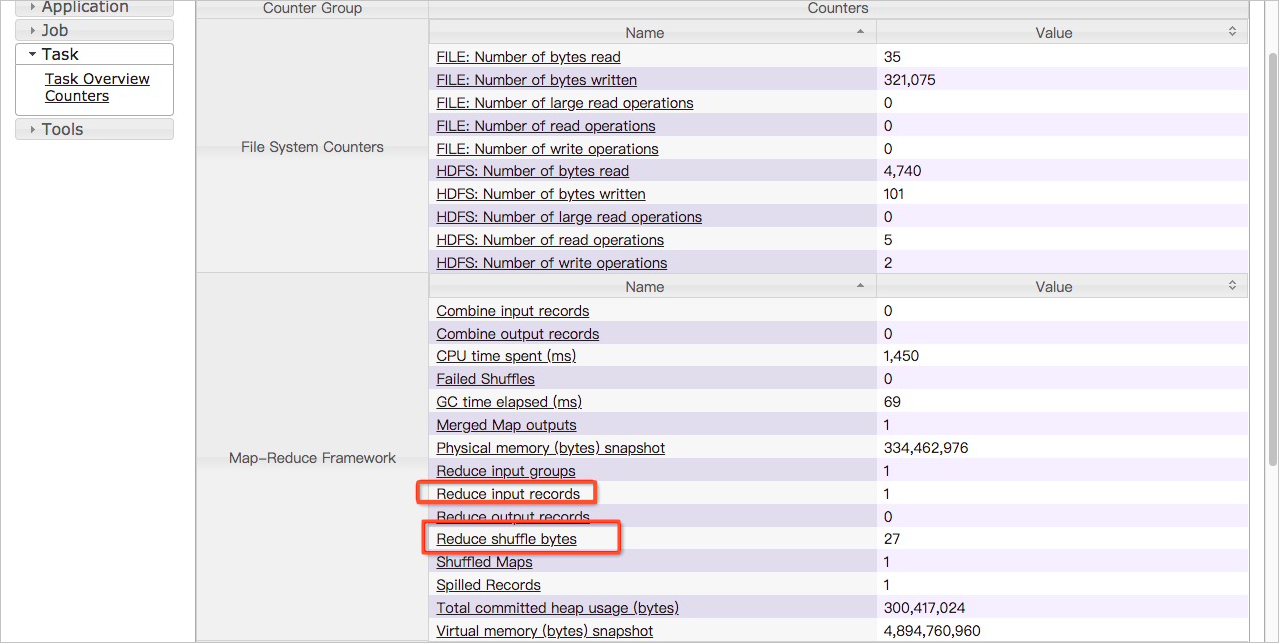
同時に実行できる Hive ジョブの最大数をどのように見積もりますか?
同時に実行できる Hive ジョブの最大数は、HiveServer2 のメモリサイズとマスターノードの数によって異なります。次の式を使用して、最大同時実行数を推定できます。
max_num = master_num × max(5, hive_server2_heapsize/512)式の パラメータ :
- master_num: クラスタ内のマスターノードの数。
- hive_server2_heapsize: hive-env.sh 構成ファイルで指定されている HiveServer2 のメモリサイズ。デフォルトサイズは 512 MB です。
例:クラスタに 3 つのマスターノードがあり、HiveServer2 のメモリサイズが 4 GB の場合、最大同時実行数は 24 です。この場合、最大 24 個の Hive ジョブを同時に実行できます。
Hive で作成された外部テーブルにデータが含まれていないのはなぜですか?
- 問題の説明:外部テーブルを作成した後、テーブルをクエリしてもデータが返されません。外部テーブルの作成に使用されるステートメントの例:
// 外部テーブルを作成するサンプルステートメントCREATE EXTERNAL TABLE storage_log(content STRING) PARTITIONED BY (ds STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION 'oss://log-12453****/your-logs/airtake/pro/storage';データのクエリに使用されるコマンド:
// データをクエリするために使用されるコマンドselect * from storage_log; - 原因:Hive は Partitions ディレクトリを自動的に関連付けません。
- 解決策:
- Partitions ディレクトリを手動で指定します:
// Partitionsディレクトリを手動で指定しますalter table storage_log add partition(ds=123); - データをクエリします。
// データをクエリしますselect * from storage_log;次のデータが返されます:
// 返されるデータOK abcd 123 efgh 123
- Partitions ディレクトリを手動で指定します: