クラスターワークロードが変動する場合、ノード数を手動で調整するのは遅く、ミスが発生しやすくなります。E-MapReduce (EMR) の Auto Scaling は、ユーザーが定義したルールに基づいてタスクノードを自動的に追加または削除し、ピーク時にタスクをスムーズに実行しつつ、オフピーク時はコストを削減します。
前提条件
作業を開始する前に、以下の要件を満たしていることを確認してください。
DataLake、Dataflow、オンライン分析処理 (OLAP)、DataServing、またはカスタムクラスターが作成済みであること。詳細については、「クラスターの作成」をご参照ください。
従量課金インスタンスまたはプリエンプティブルインスタンスを含むタスクノードグループが作成済みであること。詳細については、「ノードグループの作成」をご参照ください。
ステップ 1:トリガーモードの選択
ワークロードの特性に応じて、以下のいずれかのトリガーモードを選択します。
| シナリオ | トリガーモード |
|---|---|
| ワークロードが予測可能なスケジュールで変動する場合、または特定の期間中に固定のノード数が必要な場合。 | 時刻ベースのスケーリング |
| ワークロードが予測不可能なスケジュールで変動し、必要なノード数が実際のワークロードに応じて変化する場合。 | 負荷ベースのスケーリング |
| ワークロードには、予測可能なパターンと動的な変動の両方があります。 | 時刻ベースのスケーリングと負荷ベースのスケーリングの組み合わせ |
ステップ 2:Auto Scaling ルールの設定
複数の Auto Scaling ルールが設定され、それらの条件が同時に満たされた場合、システムは以下の順序で実行します。
スケールアウトルールはスケールインルールより優先されます。
時刻ベースおよび負荷ベースのルールは、トリガーされた順序に基づいて実行されます。
負荷ベースのルールは、クラスター負荷メトリックが評価された時刻に基づいてトリガーされます。
同じクラスター負荷メトリックを持つ負荷ベースのルールは、設定された順序でトリガーされます。
時刻ベースのスケーリング
ワークロードが増加すると予想される特定の時刻に、繰り返しまたは一度だけ実行される時刻ベースのスケールアウトルールを設定します。また、オフピーク時にノードを削減するためのスケールインルールとペアで設定します。
繰り返し実行されるルールの場合、指定した日付以降にスケーリングがトリガーされないように、ルール有効期限 を設定します。
例: ワークロードが毎日 22:00 に増加し、04:00 に減少する場合、22:00 に繰り返しスケールアウトルールを、04:00 に繰り返しスケールインルールを設定します。
パラメーターの詳細については、「カスタム Auto Scaling ルールの設定」をご参照ください。
負荷ベースのスケーリング
負荷ベースのスケーリングは、クラスター負荷メトリックをモニターし、しきい値を超えた場合にスケーリングをトリガーします。設定後は、OK をクリックし、[Auto Scaling の設定] パネルで 保存して適用 をクリックします。
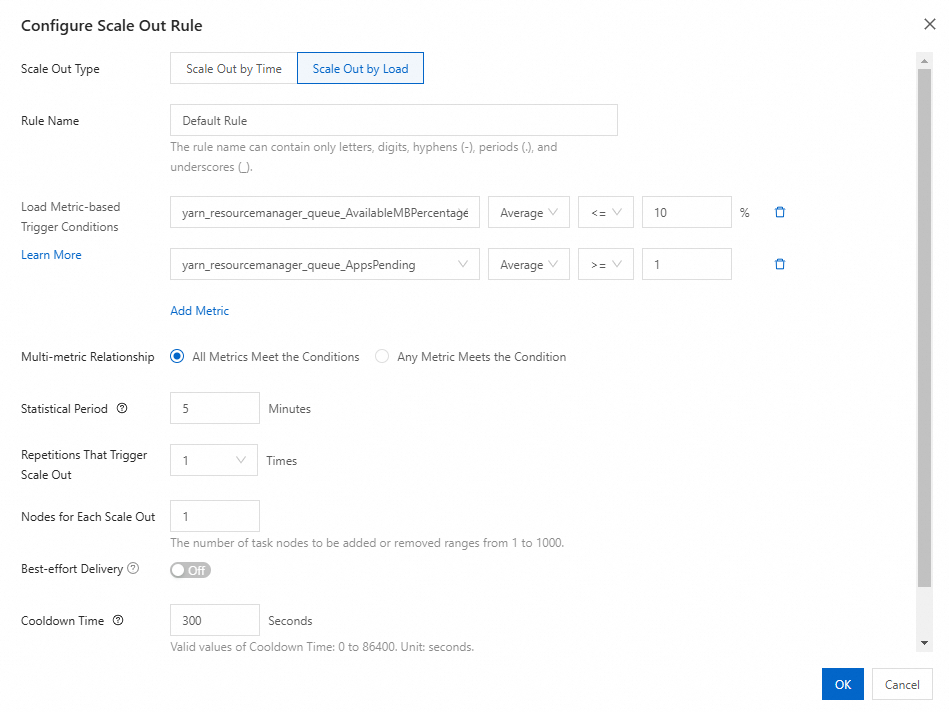
1. クラスター負荷メトリックの選択
モニタリング タブの Metric Monitoring サブタブで、ダッシュボード ドロップダウンリストから YARN-HOME を選択します。異なる期間やビジネスワークロードにおけるメトリックの変化を観察します。

スケーリングアクティビティ後にインスタンス数が増えるほどメトリック値が低下するような、クラスター容量と逆相関するメトリックを選択します。
以下の YARN メトリックを推奨します。
| メトリック | サービス | 説明 |
|---|---|---|
| yarn_resourcemanager_queue_AvailableMBPercentage | YARN | ルートキュー内の使用可能なメモリが総メモリに占める割合 |
| yarn_resourcemanager_queue_AvailableVCores | YARN | ルートキュー内の使用可能な vCPU 数 |
| yarn_resourcemanager_queue_AvailableMB | YARN | ルートキュー内の使用可能なメモリ (MB) |
| yarn_resourcemanager_queue_AppsPending | YARN | ルートキュー内の保留中のタスク数 |
| yarn_resourcemanager_queue_PendingContainers | YARN | ルートキュー内で割り当て待ちのコンテナ数 |
| yarn_resourcemanager_queue_AvailableVCoresPercentage | YARN | ルートキュー内の使用可能な vCPU の割合 |
最初の負荷ベースルールでは、スケールアウトルールには保留関連メトリック(例:yarn_resourcemanager_queue_AppsPending)、スケールインルールには使用可能関連メトリックを使用します。
例: yarn_resourcemanager_queue_AppsPending が 60 秒間で 1 以上になった場合にスケールアウトルールをトリガーします。条件が満たされると、ノードが 1 台追加され、保留中のタスク数が減少します。
2. ルールパラメーターの設定
| パラメーター | 説明 | 推奨事項 |
|---|---|---|
| トリガー条件 | AND または OR 論理で結合された 1 つ以上のメトリックしきい値 | 誤ったトリガーを減らすために、AND 演算子で複数の条件を使用します。 |
| 統計期間 | メトリック値を評価する時間ウィンドウ | 1 分に設定します。大きな値を設定すると、古いデータに基づいてスケーリングがトリガーされる可能性があります。 |
| クールダウン時間 | スケーリングアクティビティ間の最小時間 | スケールアウトルールでは 100~300 秒に設定します。ノードの追加には平均で 1.55 分(100 ノードの場合は 1.83 分)かかるため、クールダウン時間を設けることで新規ノードが安定するまで再評価を待機できます。 |
| ノード数 | 1 回のアクティビティで追加または削除するインスタンス数 | 既存ノードの容量と予想されるワークロードの増加量に基づいて見積もります。 |
| 有効時間帯 | ルールがアクティブになる 1 日の中での時間帯 | 必要に応じて、異なる時間帯に異なるルールを設定します。 |
3. ノードグループの制限の設定
現在のノードグループのノード数量制限 セクションでは、ノード数の上限と下限を定義します。
最大インスタンス数 — ノードグループの上限。無制限なスケールアウトを防止します。
最小インスタンス数 — ノードグループの下限。インスタンスが予期せずリリースされた場合、この最小値を満たすようにシステムが自動的にインスタンスを追加します。
4. 初期デプロイ後のチューニング
ルールがアクティブになった後、メトリクスの傾向とスケーリングアクティビティのレコードを確認し、設定を調整します。
スケーリングイベントが多すぎて、追加されたノードがアイドル状態になりすぐに削除される場合 — AND 演算子を使用してさらにメトリック条件を追加するか、クールダウン期間を長くします。
スケールアウトが遅すぎる、または不十分な場合 — 1 回のスケールアウトアクティビティで追加するインスタンス数を増やします。
次のステップ
カスタム Auto Scaling ルールの設定 — 高度なルールパラメーターを定義し、利用可能なすべてのクラスター負荷メトリックを確認します。