DataWorks の EMR Hive ノードを使用して、OSS に格納された生データをユーザープロファイル用のデータセットに変換します。本チュートリアルでは、3 段階のパイプラインを順に実行します:生の Web ログのクリーニング、ユーザー情報との結合、および結果の集計による利用可能な ADS テーブルへの生成です。
パイプラインの概要:
| ステージ | ノード | 入力 | 出力 |
|---|---|---|---|
| クリーニング (ODS → DWD) | dwd_log_info_di_emr | ods_raw_log_d_emr | リージョン、デバイス、ID フィールドを含む構造化ログレコード |
| 結合 (DWD → DWS) | dws_user_info_all_di_emr | dwd_log_info_di_emr + ods_user_info_d_emr | ログとユーザー人口統計情報の統合結果 |
| 集計 (DWS → ADS) | ads_user_info_1d_emr | dws_user_info_all_di_emr | ページビュー (PV) 数を含む日次ユーザープロファイル |
ノード依存関係:dwd_log_info_di_emr → dws_user_info_all_di_emr → ads_user_info_1d_emr
前提条件
開始する前に、以下の準備が完了していることを確認してください。
データの同期で説明されている通り、ソースデータを同期済みであること
環境用に準備済みの Object Storage Service (OSS) バケット(手順 2 で参照)
手順 1:ワークフローの設計
DataStudio ページの スケジュール済みワークフロー ウィンドウで、ワークフローをダブルクリックします。ワークフロー構成タブで、EMR セクション内の EMR Hive をクリックします。ノードの作成 ダイアログボックスで、名前 を設定し、確認 をクリックします。
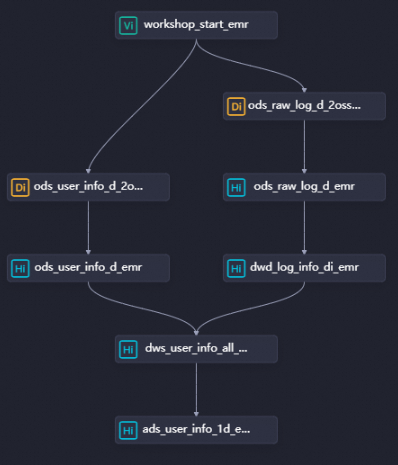
以下の 3 つの EMR Hive ノードを作成し、図に示す通りに依存関係を構成します。
dwd_log_info_di_emr— 生の OSS ログデータをクリーニングdws_user_info_all_di_emr— クリーニング済みログと基本ユーザー情報を結合ads_user_info_1d_emr— 最終的なユーザープロファイルデータを生成
手順 2:IP アドレスからリージョン名を取得する UDF の登録
生ログには訪問者の IP アドレスが格納されていますが、パイプラインではリージョンラベルが必要です。IP アドレスをリージョン名に変換する User-Defined Function (UDF) を登録します。
JAR リソースのアップロード
ip2region-emr.jar パッケージをダウンロードします。
DataStudio ページで、WorkShop ワークフローを検索し、EMR を右クリックして、リソースの作成 > EMR JAR を選択します。ダイアログボックスで以下のパラメーターを設定します。その他のパラメーターは必要に応じて設定するか、デフォルト値のままにしてください。
パラメーター 値 ストレージパス ご準備いただいた OSS バケット ファイル ダウンロードした ip2region-emr.jar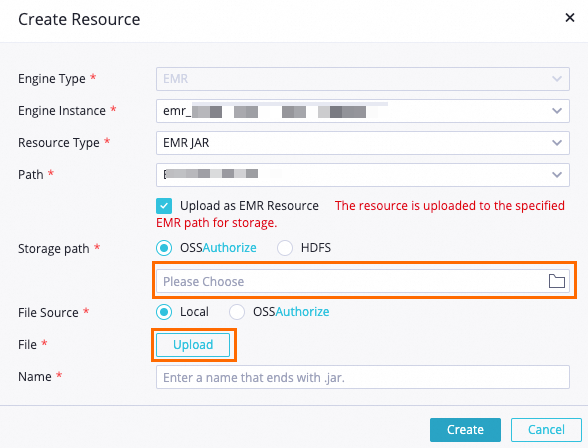
ツールバーの
 アイコンをクリックして、リソースを開発環境の EMR プロジェクトにコミットします。
アイコンをクリックして、リソースを開発環境の EMR プロジェクトにコミットします。
関数の登録
DataStudio ページで、WorkShop ワークフローを検索し、EMR を右クリックして、関数の作成 を選択します。
関数の作成 ダイアログボックスで、名前 に
getregionを設定し、作成 をクリックします。表示されるタブで以下のパラメーターを設定します。その他のパラメーターは必要に応じて設定するか、デフォルト値のままにしてください。パラメーター 値 リソース ip2region-emr.jarクラス名 org.alidata.emr.udf.Ip2Region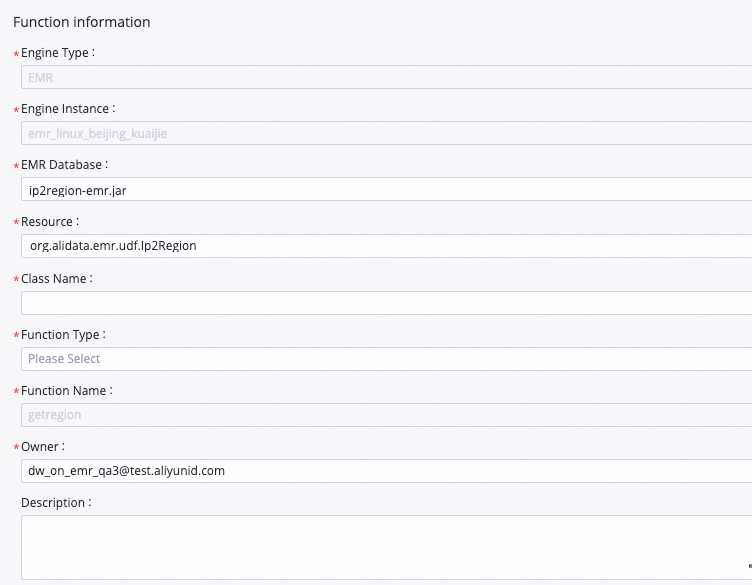
ツールバーの
アイコンをクリックして、関数を開発環境の EMR プロジェクトにコミットします。
この手順を完了すると、プロジェクト内の任意の HiveQL 文で getregion(ip) を呼び出せるようになります。
手順 3:EMR Hive ノードの構成
ワークスペースで DataStudio に関連付けられた EMR コンピュートエンジンが複数ある場合、各ノードに対して適切なコンピュートエンジンを選択します。関連付けられたコンピュートエンジンが 1 つだけの場合は、この選択をスキップしてください。
dwd_log_info_di_emr の構成(生ログのクリーニング)
このノードは、生ログテーブル (ods_raw_log_d_emr) を解析し、構造化されたレコードを dwd_log_info_di_emr に書き込みます。各生ログ行は、##@@ で区切られた単一の文字列であり、フィールドの順序は次のとおりです:ip、uid、time、request、status、bytes、referer、agent。
HiveQL コードの追加
dwd_log_info_di_emr ノードをダブルクリックして構成タブを開き、以下の文を入力します。
-- クリーニング済みログデータ用の DWD レイヤーテーブルを作成します。
CREATE TABLE IF NOT EXISTS dwd_log_info_di_emr (
ip STRING COMMENT '訪問者 IP アドレス',
uid STRING COMMENT 'ユーザー ID',
`time` STRING COMMENT 'リクエストタイムスタンプ (yyyymmddhh:mi:ss)',
status STRING COMMENT 'サーバーから返された HTTP ステータスコード',
bytes STRING COMMENT 'クライアントに返されたバイト数',
region STRING COMMENT 'UDF を使用して IP アドレスから導出したリージョン',
method STRING COMMENT 'HTTP メソッド (GET、POST など)',
url STRING COMMENT 'リクエスト URL パス',
protocol STRING COMMENT 'HTTP バージョン',
referer STRING COMMENT '参照元 URL (ドメインのみ)',
device STRING COMMENT 'デバイスタイプ:android、iphone、ipad、macintosh、windows_phone、windows_pc、または unknown',
identity STRING COMMENT 'アクセスタイプ:crawler、feed、user、または unknown'
)
PARTITIONED BY (dt STRING);
ALTER TABLE dwd_log_info_di_emr ADD IF NOT EXISTS PARTITION (dt='${bizdate}');
SET hive.vectorized.execution.enabled = false;
-- 現在の業務日付に対する生ログデータの解析およびクリーニングを行います。
-- 各生ログ行は、##@@ で区切られた単一の文字列です。
-- フィールド順序:[0]=ip、[1]=uid、[2]=tm、[3]=request、[4]=status、[5]=bytes、[6]=referer、[7]=agent
INSERT OVERWRITE TABLE dwd_log_info_di_emr PARTITION (dt='${bizdate}')
SELECT
ip
, uid
, tm
, status
, bytes
, getregion(ip) AS region -- UDF:IP アドレスをリージョン名に変換
, regexp_substr(request, '(^[^ ]+ )') AS method -- リクエスト文字列から HTTP メソッドを抽出
, regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') AS url -- リクエスト文字列から URL パスを抽出
, regexp_extract(request, '.* ([^ ]+$)') AS protocol -- リクエスト文字列から HTTP バージョンを抽出
, regexp_extract(referer, '^[^/]+://([^/]+){1}') AS referer -- パスを除去し、参照元ドメインのみを保持
, CASE
WHEN lower(agent) RLIKE 'android' THEN 'android'
WHEN lower(agent) RLIKE 'iphone' THEN 'iphone'
WHEN lower(agent) RLIKE 'ipad' THEN 'ipad'
WHEN lower(agent) RLIKE 'macintosh' THEN 'macintosh'
WHEN lower(agent) RLIKE 'windows phone' THEN 'windows_phone'
WHEN lower(agent) RLIKE 'windows' THEN 'windows_pc'
ELSE 'unknown'
END AS device -- User-Agent 文字列から導出
, CASE
WHEN lower(agent) RLIKE '(bot|spider|crawler|slurp)' THEN 'crawler'
WHEN lower(agent) RLIKE 'feed'
OR regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') RLIKE 'feed' THEN 'feed'
WHEN lower(agent) NOT RLIKE '(bot|spider|crawler|feed|slurp)'
AND agent RLIKE '^[Mozilla|Opera]'
AND regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') NOT RLIKE 'feed' THEN 'user'
ELSE 'unknown'
END AS identity -- User-Agent 文字列および URL パスから導出
FROM (
-- ##@@ デリミタを使用して各生ログ行を個別のフィールドに分割します。
SELECT
SPLIT(col, '##@@')[0] AS ip
, SPLIT(col, '##@@')[1] AS uid
, SPLIT(col, '##@@')[2] AS tm
, SPLIT(col, '##@@')[3] AS request
, SPLIT(col, '##@@')[4] AS status
, SPLIT(col, '##@@')[5] AS bytes
, SPLIT(col, '##@@')[6] AS referer
, SPLIT(col, '##@@')[7] AS agent
FROM ods_raw_log_d_emr
WHERE dt = '${bizdate}'
) a;スケジューリングプロパティの構成
| 構成項目 | 値 |
|---|---|
| パラメーターの追加(スケジューリングパラメーター セクション内) | 名前:bizdate/値:$[yyyymmdd-1] |
| 依存関係 | 出力テーブルを workspacename.dwd_log_info_di_emr |
スケジューリング周期 は 日 に設定されています。スケジュール時刻 フィールドはスキップしてください — 実行時刻は、毎日 00:30 以降にすべての子孫ノードをトリガーするルートノード workshop_start_emr から継承されます。これらの設定を保存すると、dwd_log_info_di_emr ノードは、先祖ノード ods_raw_log_d_emr が OSS からのデータ同期を完了した時点で自動的に実行されます。
ノード構成の保存
上部ツールバーの ![]() アイコンをクリックして、ノードを保存します。
アイコンをクリックして、ノードを保存します。
dws_user_info_all_di_emr の構成(ログとユーザー情報の結合)
このノードは、クリーニング済みログデータとユーザー人口統計情報テーブルを結合し、統合されたレコードを dws_user_info_all_di_emr に書き込みます。
HiveQL コードの追加
dws_user_info_all_di_emr ノードをダブルクリックして構成タブを開き、以下の文を入力します。
-- ログ動作とユーザー人口統計情報を統合する DWS レイヤーテーブルを作成します。
CREATE TABLE IF NOT EXISTS dws_user_info_all_di_emr (
uid STRING COMMENT 'ユーザー ID',
gender STRING COMMENT '性別',
age_range STRING COMMENT '年齢層',
zodiac STRING COMMENT '星座',
region STRING COMMENT 'IP アドレスから導出したリージョン',
device STRING COMMENT 'デバイスタイプ',
identity STRING COMMENT 'アクセスタイプ:crawler、feed、user、または unknown',
method STRING COMMENT 'HTTP メソッド',
url STRING COMMENT 'リクエスト URL パス',
referer STRING COMMENT '参照元ドメイン',
`time` STRING COMMENT 'リクエストタイムスタンプ (yyyymmddhh:mi:ss)'
)
PARTITIONED BY (dt STRING);
ALTER TABLE dws_user_info_all_di_emr ADD IF NOT EXISTS PARTITION (dt='${bizdate}');
-- クリーニング済みログデータ(左)とユーザー人口統計情報(右)を uid で結合します。
-- COALESCE は、uid がログに存在しユーザー情報テーブルに存在しない場合に対応します。
INSERT OVERWRITE TABLE dws_user_info_all_di_emr PARTITION (dt='${bizdate}')
SELECT
COALESCE(a.uid, b.uid) AS uid
, b.gender
, b.age_range
, b.zodiac
, a.region
, a.device
, a.identity
, a.method
, a.url
, a.referer
, a.`time`
FROM (
SELECT * FROM dwd_log_info_di_emr WHERE dt = '${bizdate}'
) a
LEFT OUTER JOIN (
SELECT * FROM ods_user_info_d_emr WHERE dt = '${bizdate}'
) b ON a.uid = b.uid;スケジューリングプロパティの構成
| 構成項目 | 値 |
|---|---|
| パラメーターの追加(スケジューリングパラメーター セクション内) | 名前:bizdate/値:$[yyyymmdd-1] |
| 依存関係 | 出力テーブルを workspacename.dws_user_info_all_di_emr |
スケジューリング周期 は 日 に設定されています。スケジュール時刻 フィールドはスキップしてください — 実行時刻は、ルートノード workshop_start_emr によって決定されます。これらの設定を保存すると、dws_user_info_all_di_emr ノードは、両方の先祖ノード(ods_user_info_d_emr および dwd_log_info_di_emr)が完了した時点で自動的に実行されます。
ノード構成の保存
上部ツールバーの ![]() アイコンをクリックして、ノードを保存します。
アイコンをクリックして、ノードを保存します。
ads_user_info_1d_emr の構成(ユーザープロファイルの生成)
このノードは、結合済みデータを日次ユーザープロファイルに集計し(uid ごとにグループ化)、結果を ads_user_info_1d_emr に書き込みます。
HiveQL コードの追加
ads_user_info_1d_emr ノードをダブルクリックして構成タブを開き、以下の文を入力します。
-- 日次ユーザープロファイル用の ADS レイヤーテーブルを作成します。
CREATE TABLE IF NOT EXISTS ads_user_info_1d_emr (
uid STRING COMMENT 'ユーザー ID',
region STRING COMMENT 'IP アドレスから導出したリージョン',
device STRING COMMENT 'デバイスタイプ',
pv BIGINT COMMENT 'ページビュー数',
gender STRING COMMENT '性別',
age_range STRING COMMENT '年齢層',
zodiac STRING COMMENT '星座'
)
PARTITIONED BY (dt STRING);
ALTER TABLE ads_user_info_1d_emr ADD IF NOT EXISTS PARTITION (dt='${bizdate}');
-- 現在の業務日付に対するユーザーごとの動作を集計します。
-- COUNT(0) は、各 uid ごとのログ行数をページビュー総数としてカウントします。
INSERT OVERWRITE TABLE ads_user_info_1d_emr PARTITION (dt='${bizdate}')
SELECT
uid
, MAX(region)
, MAX(device)
, COUNT(0) AS pv
, MAX(gender)
, MAX(age_range)
, MAX(zodiac)
FROM dws_user_info_all_di_emr
WHERE dt = '${bizdate}'
GROUP BY uid;スケジューリングプロパティの構成
| 構成項目 | 値 |
|---|---|
| パラメーターの追加(スケジューリングパラメーター セクション内) | 名前:bizdate/値:$[yyyymmdd-1] |
| 依存関係 | 出力テーブルを workspacename.ads_user_info_1d_emr |
スケジューリング周期 は 日 に設定されています。スケジュール時刻 フィールドはスキップしてください — 実行時刻は、ルートノード workshop_start_emr によって決定されます。これらの設定を保存すると、ads_user_info_1d_emr ノードは、dws_user_info_all_di_emr の完了後に自動的に実行されます。
ノード構成の保存
上部ツールバーの ![]() アイコンをクリックして、ノードを保存します。
アイコンをクリックして、ノードを保存します。
手順 4:ワークフローのテストおよびコミット
ワークフロー構成タブで、
 アイコンをクリックしてワークフローを実行します。
アイコンをクリックしてワークフローを実行します。すべてのノードの横に
 アイコンが表示されたら、
アイコンが表示されたら、 アイコンをクリックしてコミットします。
アイコンをクリックしてコミットします。コミット ダイアログボックスで、コミット対象のノードを選択し、説明を入力して、I/O 不整合アラートを無視 を選択します。
確認 をクリックします。
デプロイメントパッケージの作成 ページで、ノードをデプロイします。
手順 5:本番環境でのノード実行
デプロイ済みノードは、翌日の実行をスケジュールしたインスタンスを生成します。データバックフィル機能を使用して即時実行をトリガーし、パイプラインが本番環境でエンドツーエンドで正常に動作することを検証します。
右上隅の オペレーションセンター(またはワークフロー構成タブの上部ツールバー)をクリックします。
左側ナビゲーションウィンドウで、自動トリガー型ノードの運用管理 > 自動トリガー型ノード を選択します。
workshop_start_emrゼロロードノードの名前をクリックします。右側の有向非循環グラフ (DAG) で、
workshop_start_emrノードを右クリックし、実行 > 現在および子孫ノードの遡及的実行 を選択します。データバックフィル パネルで、バックフィル対象のノードを選択し、データタイムスタンプ パラメーターを設定して、送信してリダイレクト をクリックします。データバックフィルインスタンスページが開きます。
更新 をクリックし、すべてのノードが成功ステータスを示すまで待ちます。
次のステップ
これらのノードで生成されるデータの品質をモニターするには、DataWorks でデータ品質ルールを設定します。詳細については、「データをバックフィルし、データバックフィルインスタンスを表示する (新しいバージョン)」をご参照ください。