Elastic GPU Service は、高い計算密度、低レイテンシーのネットワーク、柔軟な課金方法を備えた GPU インスタンスを提供します。さらに、コードを変更することなくトレーニングと推論のワークロードを高速化する無料のツールキット DeepGPU も利用できます。
Elastic GPU Service
世界 17 リージョンでのグローバルデプロイ。世界 17 のリージョンで GPU インスタンスを大規模にデプロイできます。自動プロビジョニングと自動スケーリングにより、手動での介入なしに突然の需要急増に対応します。
最大 1,000 TFLOPS の混合精度コンピューティング。パフォーマンス専有型の CPU プラットフォームと組み合わせることで、GPU インスタンスは最大 1,000 兆回/秒の浮動小数点演算 (TFLOPS) の混合精度コンピューティング性能を提供します。これは、大規模な大規模言語モデル (LLM) のトレーニングや高スループットの推論に十分な性能です。
あらゆるワークロードタイプに対応する 2 層ネットワーク。各 GPU インスタンスは、最大 32 Gbit/s の内部帯域幅と 450 万パケット/秒 (Mpps) を備えた VPC に接続し、一般的なワークロードに対応します。分散トレーニングタスクには、インスタンスを Super Computing Cluster (SCC) と組み合わせることで、ノード間に最大 50 Gbit/s のリモートダイレクトメモリアクセス (RDMA) 帯域幅を追加し、勾配同期がボトルネックになるのを防ぎます。
使用パターンに合わせた課金。サブスクリプション、従量課金、プリエンプティブルインスタンス、リザーブドインスタンス、ストレージ容量ユニット (SCU) から、コストモデルに合わせて選択できます。複数の課金方法を組み合わせることで、定常的なワークロードとバースト的なワークロードの両方に対応できます。
DeepGPU
DeepGPU は、Elastic GPU Service 上の GPU ワークロードを高速化する無料のツールキットです。Deepytorch、AIACC-ACSpeed (ACSpeed)、AIACC-AGSpeed (AGSpeed)、FastGPU、cGPU が含まれます。
FastGPU
FastGPU は、インフラストラクチャのセットアップを自動化するクラスターデプロイツールです。これにより、計算、ストレージ、ネットワークリソースを手動でプロビジョニングすることなく、AI トレーニングと推論タスクを実行できます。
5 分でクラスターを準備完了。FastGPU は、完全に構成されたクラスターを 5 分でデプロイします。すべてのリソースはインフラストラクチャ層でプロビジョニングされ、デバッグのために直接アクセスできます。
タスクのライフサイクルに連動したリソースライフサイクル。FastGPU は、トレーニングまたは推論タスクが終了すると、GPU インスタンスを自動的にリリースします。コストを削減するために、プリエンプティブルインスタンスがサポートされています。
完全な可観測性。FastGPU は、可視化、ログ管理、タスクトレースを提供し、すべての実行が監査可能であることを保証します。
cGPU
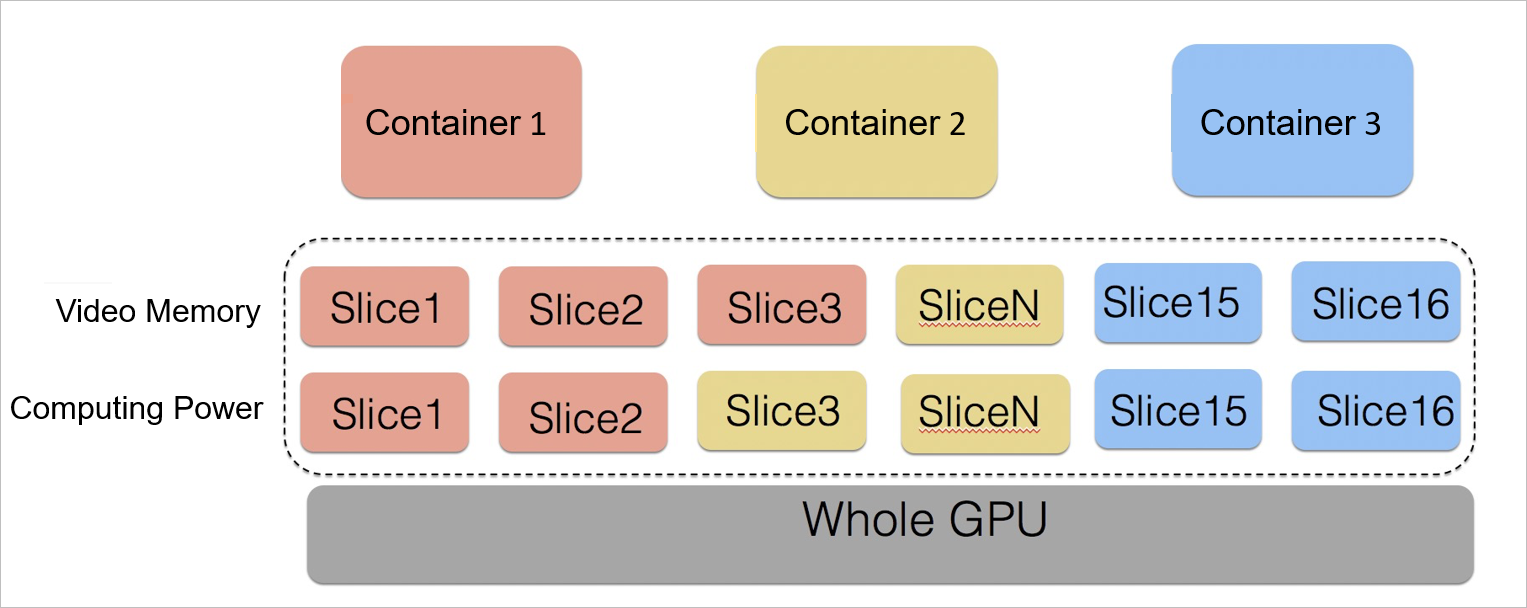
cGPU を使用すると、複数のコンテナが単一の物理 GPU を共有でき、厳格なリソース隔離により、GPU 使用率の向上、コストの削減、セキュリティの強化が実現します。
ビジネスデータを公開することなく、コンテナ間で 1 つの GPU を共有。ほとんどの AI ワークロードは、GPU 全体を必要としません。cGPU は、各コンテナのデータを隔離しながら、コンテナ間で GPU リソースを割り当てるため、各ワークロードが実際に使用する GPU メモリと計算能力に対してのみ料金が発生します。
GPU メモリまたは計算能力による柔軟な割り当て。各コンテナの要件に合わせて、GPU メモリまたは計算能力の比率に基づいてリソースを割り当てます。
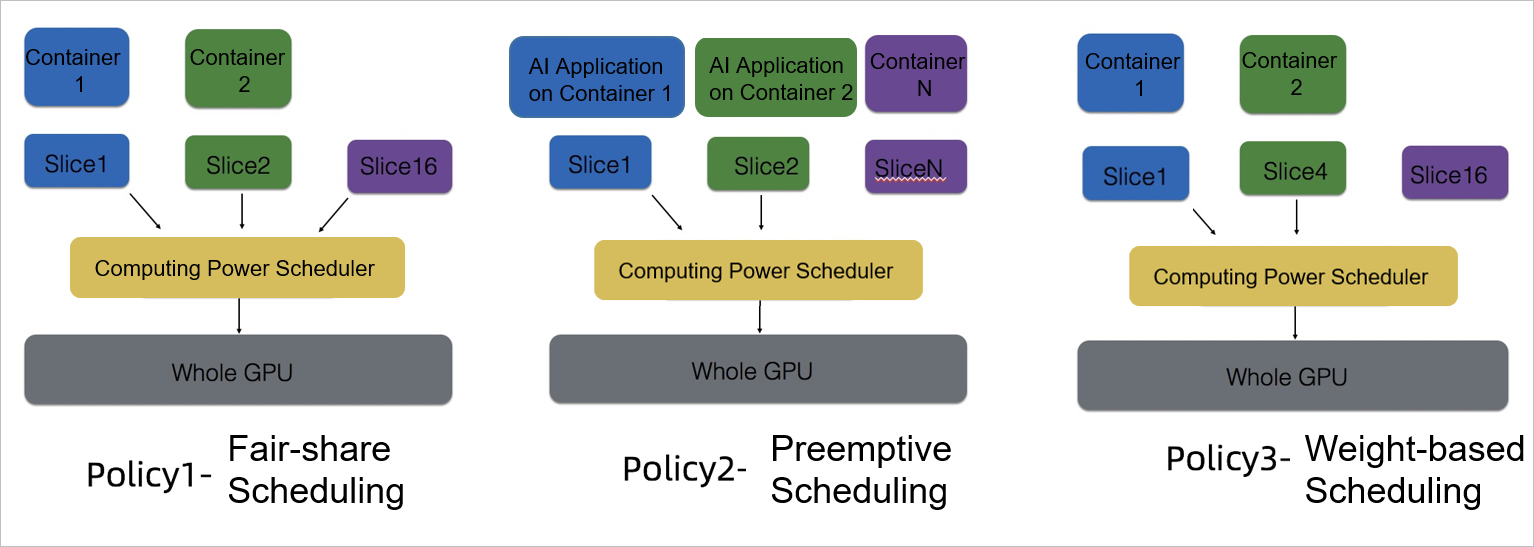
ピーク時とオフピーク時に対応する 3 つの切り替え可能なスケジューリングポリシー。再起動不要で、ワークロードの強度に合わせて 3 つの計算能力割り当てポリシーをリアルタイムで切り替えることができます。