BigDL PPML を使用して、Intel® TDX 対応 g8i インスタンス上で、データの暗号化、セキュアコンピューティング、プライバシー保護のために、分散型でエンドツーエンドのセキュアな Apache Spark アプリケーションを実行します。
背景情報
企業がデータとコンピューティングリソースをクラウドに移行するにつれて、データプライバシーと機密性の保護は、ビッグデータ分析および AI アプリケーションにとって重要な課題となっています。
BigDL PPML を使用すると、Alibaba Cloud TDX インスタンス上で標準的なビッグデータおよび AI アプリケーション (Apache Spark、Apache Flink、Tensorflow、PyTorch など) を実行しながら、転送中および使用中のデータを保護し、アプリケーションの完全性を保証できます。詳細については、「BigDL-PPML」をご参照ください。
-
Intel® Trusted Domain Extensions (Intel® TDX) は、ファームウェアやホストのセキュリティステータスに依存しないハードウェア支援によるデータ保護を提供し、物理マシン上でのコンフィデンシャルコンピューティングを可能にします。
-
Alibaba Cloud g8i インスタンスは、ハードウェアで強制されるコンフィデンシャルコンピューティングを提供する Intel® TDX 対応インスタンス (以下、TDX インスタンス) です。TDX インスタンスは、マルウェア攻撃のリスクを軽減し、データプライバシーとアプリケーションの完全性を保証します。
-
BigDL PPML は、データ分析および AI アプリケーションを保護するために Intel® TDX 上に構築されたソリューションです。
アーキテクチャ
BigDL PPML は、既存の分散型ビッグデータ分析および AI アプリケーション (Apache Spark、Apache Flink、Tensorflow、PyTorch など) を、コードの変更なしにコンフィデンシャルな環境で実行します。アプリケーションは TDX インスタンスに基づく Kubernetes クラスター上で実行され、そこで Intel® TDX がコンピューティングとメモリを保護します。BigDL PPML は、以下のエンドツーエンドのセキュリティメカニズムを提供します。
-
TDX インスタンスに基づく Kubernetes クラスターにおける、信頼されたクラスターのリモートアテステーション。
-
Key Management Service (KMS):分散データの暗号化と復号のためのキーの管理。
-
セキュアな分散コンピューティングと通信。
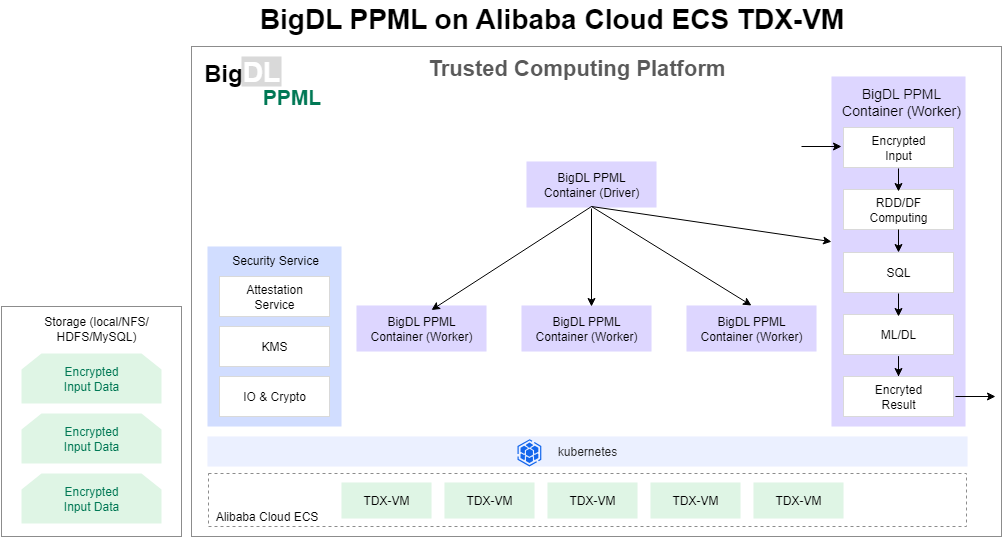
上の図に示すように、BigDL PPML は、Intel® TDX 対応インスタンス上にデプロイされた Kubernetes クラスターにおいて、エンドツーエンドのビッグデータおよび AI パイプラインを保護します。すべてのデータは暗号化され、データレイクやデータウェアハウスに保存されます。
-
BigDL PPML ワーカーは、暗号化された入力データをロードし、リモートアテステーションまたは KMS を使用してデータキーを取得し、TDX インスタンス上で入力データを復号します。
-
BigDL PPML ワーカーは、分散方式でデータを前処理し、モデルをトレーニングし、ビッグデータおよび AI フレームワークで推論を実行します。
-
BigDL PPML ワーカーは、最終結果、出力データ、またはモデルを暗号化して分散ストレージに書き込みます。
ノード間で転送されるデータは、Advanced Encryption Standard (AES) や Transport Layer Security などのセキュリティプロトコルによって転送中に暗号化され、エンドツーエンドのデータセキュリティとプライバシーが保証されます。
操作手順
この例では、TDX インスタンス上で Apache Spark Simple Query アプリケーションを使用します。他のビッグデータおよび AI アプリケーションについては、「BigDL PPML チュートリアルと事例」をご参照ください。
ステップ 1:Kubernetes クラスターとランタイム環境のデプロイ
この例では、1 つのマスターノードと 2 つのワーカーノードで構成される Kubernetes クラスターを使用します。ノード数は、購入する TDX インスタンスの数と一致させる必要があります。要件に基づいてクラスターのサイズを調整してください。
-
Intel® TDX 対応 g8i インスタンスを作成します。
詳細については、「カスタム起動でインスタンスを作成」をご参照ください。次のパラメーターにご注意ください。
-
インスタンスタイプ:少なくとも 32 vCPU と 64 GiB のメモリを備えたインスタンスタイプを選択します。この例では ecs.g8i.8xlarge を使用します。
-
イメージ:Alibaba Cloud Linux 3.2104 LTS 64 ビットを選択します。
-
パブリック IP アドレス:[パブリック IPv4 アドレスを割り当てる] を選択します。
-
数量:3 と入力します。
-
-
インスタンスに接続します。
詳細については、「接続方法の選択」をご参照ください。
-
Kubernetes クラスターをデプロイし、セキュリティ設定を構成します。
-
g8i インスタンスに Kubernetes クラスターをデプロイします。
詳細については、「kubeadm でクラスターを作成」をご参照ください。
-
マスターノードでセキュリティ設定 (ロールベースのアクセス制御) を構成します。
kubectl create serviceaccount spark kubectl create clusterrolebinding spark-role --clusterrole=edit --serviceaccount=default:spark --namespace=default
-
-
PersistentVolume を作成します。
-
root ユーザーとして
pv-volume.yamlファイルを作成します。vim pv-volume.yaml -
Iキーを押して挿入モードに入ります。 -
pv-volume.yamlに次の内容を追加します。apiVersion: v1 kind: PersistentVolume metadata: name: task-pv-volume labels: type: local spec: storageClassName: manual capacity: storage: 10Gi accessModes: - ReadWriteOnce hostPath: path: "/mnt/data" -
Escキーを押し、:wqと入力して変更を保存し、挿入モードを終了します。 -
PersistentVolume を作成して表示します。
kubectl apply -f pv-volume.yaml kubectl get pv task-pv-volume
-
-
PersistentVolumeClaim を作成します。
-
root ユーザーとして
pv-claim.yamlファイルを作成します。vim pv-claim.yaml -
Iキーを押して挿入モードに入ります。 -
pv-claim.yamlに次の内容を追加します。apiVersion: v1 kind: PersistentVolumeClaim metadata: name: task-pv-claim spec: storageClassName: manual accessModes: - ReadWriteOnce resources: requests: storage: 3Gi -
Escキーを押し、:wqと入力して変更を保存し、挿入モードを終了します。 -
PersistentVolumeClaim を作成して表示します。
kubectl apply -f pv-claim.yaml kubectl get pvc task-pv-claim
-
ステップ 2:トレーニングデータの暗号化
-
Kubernetes クラスターの各ノードで BigDL PPML イメージを取得します。
このイメージは、データの暗号化と復号を行う標準の Apache Spark アプリケーションを実行します。
docker pull intelanalytics/bigdl-ppml-trusted-bigdata-gramine-reference-16g:2.3.0-SNAPSHOT -
トレーニングデータセットファイル
people.csvを生成します。-
マスターノードにトレーニングスクリプト
generate_people_csv.pyをダウンロードします。wget https://github.com/intel-analytics/BigDL/raw/main/ppml/scripts/generate_people_csv.py -
people.csvを生成します。python generate_people_csv.py </save/path/of/people.csv> <num_lines>説明-
</save/path/of/people.csv>:
people.csvの出力パス。この例では /home/user を使用します。 -
<num_lines>:
people.csvの行数。この例では 500 を使用します。
-
-
people.csvをターゲットディレクトリに移動します。sudo scp /home/user/people.csv /mnt/data/simplekms/重要-
/home/userを実際のディレクトリに置き換えます。 -
この例では、暗号化されたデータと復号されたデータを保存するために
/mnt/data/simplekms/を使用します。/mnt/data/simplekms/ディレクトリは、以降のセクションでは別途説明されていません。
-
-
-
マスターノードで
bigdl-ppml-clientコンテナを実行します。このコンテナはトレーニングデータを暗号化および復号します。
説明コンテナの実行ユーザーに応じて
/home/user/kuberconfig:/root/.kube/configを置き換えます。-
root ユーザーの場合、
/root/kuberconfig:/root/.kube/configに置き換えます。 -
一般ユーザー (例: test) の場合は、
/home/test/kuberconfig:/root/.kube/configに置き換えます。
export K8S_MASTER=k8s://$(kubectl cluster-info | grep 'https.*6443' -o -m 1) echo The k8s master is $K8S_MASTER . export SPARK_IMAGE=intelanalytics/bigdl-ppml-trusted-bigdata-gramine-reference-16g:2.3.0-SNAPSHOT sudo docker run -itd --net=host \ -v /etc/kubernetes:/etc/kubernetes \ -v /home/user/kuberconfig:/root/.kube/config \ -v /mnt/data:/mnt/data \ -e RUNTIME_SPARK_MASTER=$K8S_MASTER \ -e RUNTIME_K8S_SPARK_IMAGE=$SPARK_IMAGE \ -e RUNTIME_PERSISTENT_VOLUME_CLAIM=task-pv-claim \ --name bigdl-ppml-client \ $SPARK_IMAGE bash docker exec -it bigdl-ppml-client bash -
-
Kubernetes クラスターのマスターノードで
people.csvを暗号化します。-
アプリケーション ID (APPID) と API キー (APIKEY) からプライマリーキー (primarykey) を生成します。
Simple KMS を使用して、APPID と APIKEY (1〜12 文字) を生成します。この例では、APPID は 98463816****、APIKEY は 15780936**** です。
--primaryKeyPathは、プライマリーキーのストレージディレクトリを指定します。java -cp '/ppml/spark-3.1.3/conf/:/ppml/spark-3.1.3/jars/*:/ppml/bigdl-2.3.0-SNAPSHOT/jars/*' \ com.intel.analytics.bigdl.ppml.examples.GeneratePrimaryKey \ --primaryKeyPath /mnt/data/simplekms/primaryKey \ --kmsType SimpleKeyManagementService \ --simpleAPPID 98463816**** \ --simpleAPIKEY 15780936**** -
暗号化スクリプト
encrypt.pyを作成します。-
/mnt/data/simplekmsディレクトリに切り替えます:cd /mnt/data/simplekms -
encrypt.pyファイルを作成して開きます。sudo vim encrypt.py -
Iキーを押して挿入モードに入ります。 -
encrypt.pyファイルに次の内容を追加します。# encrypt.py from bigdl.ppml.ppml_context import * args = {"kms_type": "SimpleKeyManagementService", "app_id": "98463816****", "api_key": "15780936****", "primary_key_material": "/mnt/data/simplekms/primaryKey" } sc = PPMLContext("PPMLTest", args) csv_plain_path = "/mnt/data/simplekms/people.csv" csv_plain_df = sc.read(CryptoMode.PLAIN_TEXT) \ .option("header", "true") \ .csv(csv_plain_path) csv_plain_df.show() output_path = "/mnt/data/simplekms/encrypted-input" sc.write(csv_plain_df, CryptoMode.AES_CBC_PKCS5PADDING) \ .mode('overwrite') \ .option("header", True) \ .csv(output_path) -
Escキーを押し、:wqと入力して変更を保存し、挿入モードを終了します。
-
-
bigdl-ppml-clientコンテナ内で、APPID、APIKEY、および primarykey を使用してpeople.csvを暗号化します。暗号化されたデータは
/mnt/data/simplekms/encrypted-outputに保存されます。java \ -cp '/ppml/spark-3.1.3/conf/:/ppml/spark-3.1.3/jars/*:/ppml/bigdl-2.3.0-SNAPSHOT/jars/*' \ -Xmx1g org.apache.spark.deploy.SparkSubmit \ --master 'local[4]' \ --conf spark.network.timeout=10000000 \ --conf spark.executor.heartbeatInterval=10000000 \ --conf spark.python.use.daemon=false \ --conf spark.python.worker.reuse=false \ --py-files /ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-ppml-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip,/ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip,/ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-dllib-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip \ /mnt/data/simplekms/encrypt.py
-
-
マスターノードから各ワーカーノードに
/mnt/data/simplekmsをコピーします。cd /mnt/data sudo scp -r user@192.168.XXX.XXX:/mnt/data/simplekms .説明userを実際のユーザー名に、192.168.XXX.XXXをマスターノードの実際の IP アドレスに置き換えてください。
ステップ 3:BigDL PPML に基づくビッグデータ分析事例の実行
-
bigdl-ppml-clientコンテナで、Spark ジョブをサブミットして Simple Query の例を実行します。説明spark.driver.host=192.168.XXX.XXXで、192.168.XXX.XXXを実際のマスターノードの IP アドレスに置き換えてください。${SPARK_HOME}/bin/spark-submit \ --master $RUNTIME_SPARK_MASTER \ --deploy-mode client \ --name spark-simplequery-tdx \ --conf spark.driver.memory=4g \ --conf spark.executor.cores=4 \ --conf spark.executor.memory=4g \ --conf spark.executor.instances=2 \ --conf spark.driver.host=192.168.XXX.XXX \ --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \ --conf spark.cores.max=8 \ --conf spark.kubernetes.container.image=$RUNTIME_K8S_SPARK_IMAGE \ --class com.intel.analytics.bigdl.ppml.examples.SimpleQuerySparkExample \ --conf spark.network.timeout=10000000 \ --conf spark.executor.heartbeatInterval=10000000 \ --conf spark.kubernetes.executor.deleteOnTermination=false \ --conf spark.driver.extraClassPath=local://${BIGDL_HOME}/jars/* \ --conf spark.executor.extraClassPath=local://${BIGDL_HOME}/jars/* \ --conf spark.kubernetes.file.upload.path=/mnt/data \ --conf spark.kubernetes.driver.volumes.persistentVolumeClaim.${RUNTIME_PERSISTENT_VOLUME_CLAIM}.options.claimName=${RUNTIME_PERSISTENT_VOLUME_CLAIM} \ --conf spark.kubernetes.driver.volumes.persistentVolumeClaim.${RUNTIME_PERSISTENT_VOLUME_CLAIM}.mount.path=/mnt/data \ --conf spark.kubernetes.executor.volumes.persistentVolumeClaim.${RUNTIME_PERSISTENT_VOLUME_CLAIM}.options.claimName=${RUNTIME_PERSISTENT_VOLUME_CLAIM} \ --conf spark.kubernetes.executor.volumes.persistentVolumeClaim.${RUNTIME_PERSISTENT_VOLUME_CLAIM}.mount.path=/mnt/data \ --jars local:///ppml/bigdl-2.3.0-SNAPSHOT/jars/bigdl-ppml-spark_3.1.3-2.3.0-SNAPSHOT.jar \ local:///ppml/bigdl-2.3.0-SNAPSHOT/jars/bigdl-ppml-spark_3.1.3-2.3.0-SNAPSHOT.jar \ --inputPartitionNum 8 \ --outputPartitionNum 8 \ --inputEncryptModeValue AES/CBC/PKCS5Padding \ --outputEncryptModeValue AES/CBC/PKCS5Padding \ --inputPath /mnt/data/simplekms/encrypted-input \ --outputPath /mnt/data/simplekms/encrypted-output \ --primaryKeyPath /mnt/data/simplekms/primaryKey \ --kmsType SimpleKeyManagementService \ --simpleAPPID 98463816**** \ --simpleAPIKEY 15780936**** -
マスターノードで Spark ジョブのステータスを表示します。
-
ドライバーとエグゼキューターの名前とステータスを表示します。
kubectl get podジョブが完了すると、STATUS が
RunningからCompletedに変わります。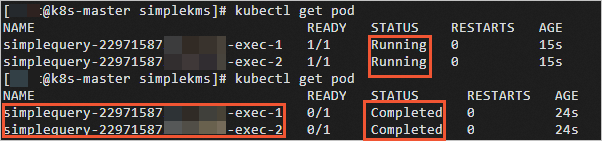
-
Pod のログを表示します。
kubectl logs simplequery-xxx-exec-1説明simplequery-xxx-exec-1を前の手順で確認した Name の値に置き換えてください。ジョブが完了すると、ポッドログに
Finishedが表示されます。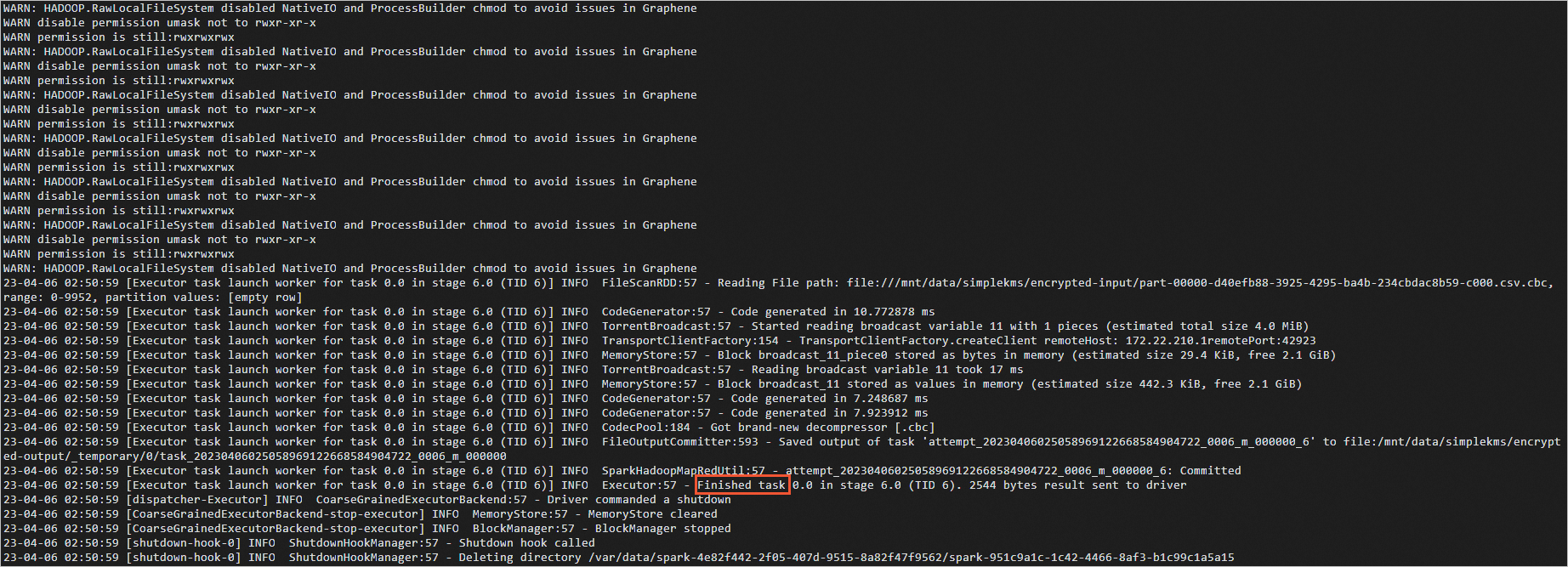
-
ステップ 4:結果の復号
-
各ワーカーノードの encrypted-output ディレクトリから
.metaファイルとpart-XXXX.csv.cbcファイルをマスターノードの encrypted-output ディレクトリにアップロードします。アップロード後、マスターノードの
encrypted-outputディレクトリのデータは以下のようになります。
-
マスターノードの
/mnt/data/simplekmsに decrypt.py ファイルを作成します。-
/mnt/data/simplekmsディレクトリに切り替えます:cd /mnt/data/simplekms -
decrypt.pyファイルを作成して開きます。sudo vim decrypt.py -
Iキーを押して挿入モードに入ります。 -
decrypt.pyファイルに次の内容を追加します。from bigdl.ppml.ppml_context import * args = {"kms_type": "SimpleKeyManagementService", "app_id": "98463816****", "api_key": "15780936****", "primary_key_material": "/mnt/data/simplekms/primaryKey" } sc = PPMLContext("PPMLTest", args) encrypted_csv_path = "/mnt/data/simplekms/encrypted-output" csv_plain_df = sc.read(CryptoMode.AES_CBC_PKCS5PADDING) \ .option("header", "true") \ .csv(encrypted_csv_path) csv_plain_df.show() output_path = "/mnt/data/simplekms/decrypted-output" sc.write(csv_plain_df, CryptoMode.PLAIN_TEXT) \ .mode('overwrite') \ .option("header", True)\ .csv(output_path) -
Escキーを押し、:wqと入力して変更を保存し、挿入モードを終了します。
-
-
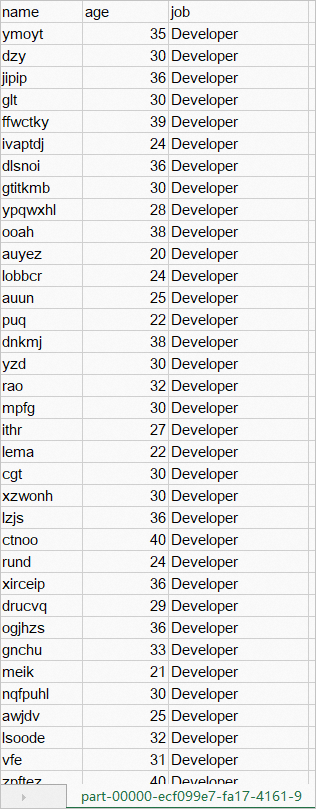
マスターノード上の
encrypted_csv_pathディレクトリにあるデータを復号化します。APPID、APIKEY、および primarykey によってデータが復号化されます。 復号化されたファイル
part-XXXX.csvは/mnt/data/simplekms/decrypted-outputに保存されます。java \ -cp '/ppml/spark-3.1.3/conf/:/ppml/spark-3.1.3/jars/*:/ppml/bigdl-2.3.0-SNAPSHOT/jars/*' \ -Xmx1g org.apache.spark.deploy.SparkSubmit \ --master 'local[4]' \ --conf spark.network.timeout=10000000 \ --conf spark.executor.heartbeatInterval=10000000 \ --conf spark.python.use.daemon=false \ --conf spark.python.worker.reuse=false \ --py-files /ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-ppml-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip,/ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip,/ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-dllib-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip \ /mnt/data/simplekms/decrypt.py復号されたデータは、以下のように表示されます。