Intel MPI Benchmarks (IMB) と Message Passing Interface (MPI) ライブラリを使用して、E-HPC クラスターの通信パフォーマンスをテストします。このチュートリアルでは、ポイントツーポイントレイテンシ (pingpong) と集団通信操作 (allreduce、alltoall) について説明します。
前提条件
開始する前に、以下を確認してください。
管理ノード 1 台と計算ノード 2 台で構成される SCC ベースの E-HPC クラスター。セットアップ手順については、「ウィザードを使用したクラスターの作成」をご参照ください。クラスターを以下の設定で構成します。
設定 値 ハードウェア設定 管理ノード 1 台と計算ノード 2 台。各計算ノードに 8 vCPU 以上の ECS インスタンスタイプを使用します。この例では、2 つの ecs.c7.2xlargeインスタンスを使用します。ソフトウェア設定 CentOS 7.6 パブリックイメージと PBS スケジューラ。 sudo 権限グループに所属する
mpitestという名前のクラスターユーザー。セットアップ手順については、「ユーザーの作成」をご参照ください。クラスターにインストールされている以下のソフトウェア。インストール手順については、「ソフトウェアのインストール」をご参照ください。
Intel MPI 2018
Intel MPI Benchmarks (IMB) 2019
基本概念
Intel MPI Benchmarks (IMB) は、HPC クラスターにおけるさまざまなメッセージ粒度でのポイントツーポイントおよびグローバルな通信パフォーマンスを測定します。
Message Passing Interface (MPI) は、並列計算のための標準化されたポータブルなメッセージパッシング標準です。複数のプログラミング言語をサポートし、高性能、同時実行性、移植性、スケーラビリティを提供します。
ステップ1:クラスターへの接続
以下のいずれかの方法でクラスターに接続します。この例では、ユーザー名として mpitest を使用します。接続後、シェルは /home/mpitest で開きます。
オプション1:E-HPC クライアント (PBS スケジューラが必要)
E-HPC クライアント環境がデプロイされていることを確認してください。セットアップ手順については、「E-HPC クライアント環境のデプロイ」をご参照ください。
E-HPC クライアントを起動してログインします。
左側のナビゲーションウィンドウで、[セッション管理] をクリックします。
[セッション管理] ページ右上の [ターミナル] をクリックします。
オプション2:E-HPC コンソール
E-HPC コンソールにログインします。
上部のナビゲーションバーの左上で、リージョンを選択します。
左側のナビゲーションウィンドウで、[クラスター] をクリックします。
[クラスター] ページで対象のクラスターを見つけ、[接続] をクリックします。
[接続] パネルでユーザー名とパスワードを入力し、[SSH 経由で接続] をクリックします。
ステップ2:ジョブの送信
このステップのすべての例では、mpirun を -genv I_MPI_DEBUG 5 フラグとともに使用して、レベル 5 の MPI デバッグ出力を有効にします。
IMB.pbsという名前のジョブスクリプトファイルを作成します。vim IMB.pbs次のスクリプトを使用します。
#!/bin/sh #PBS -j oe #PBS -l select=2:ncpus=8:mpiprocs=1 export MODULEPATH=/opt/ehpcmodulefiles/ module load intel-mpi/2018 module load intel-mpi-benchmarks/2019 echo "run at the beginning" /opt/intel/impi/2018.3.222/bin64/mpirun -genv I_MPI_DEBUG 5 -np 2 -ppn 1 -host compute000,compute001 /opt/intel-mpi-benchmarks/2019/IMB-MPI1 pingpong > IMB-pingpong「
#PBS -l select=2:ncpus=8:mpiprocs=1」の行は、2 つのノード、ノードあたり 8 つの vCPU、ノードあたり 1 つの MPI プロセスをリクエストします。これらの値は、ご利用のクラスター構成に合わせて調整してください。要件に基づいて
mpirunパラメーターを構成します。パラメーター 説明 -npMPI プロセスの総数。たとえば、各ノードに 1 つのプロセスを持つ 2 つのノードでは -np 2が必要です。-ppnノードあたりの MPI プロセス数。 -hostジョブを実行するノードのコンマ区切りのリスト。 -npmin実行可能なプロセスの最小数。 -msglogセグメント粒度の範囲。 注:すべての IMB パラメーターとサポートされている通信モードを表示するには、
/opt/intel-mpi-benchmarks/2019/IMB-MPI1 -hを実行します。(任意) スクリプト内の
mpirunコマンドを変更して、追加のベンチマークテストを実行します。Allreduce — N 個のノードにわたる集団リダクションパフォーマンスを測定します。これを使用して、N 個のノード間の all-reduce 通信のパフォーマンスをテストします。各ノードで 2 つのプロセスが開始され、さまざまなメッセージ粒度のメッセージを通信するために消費された時間を取得します。
/opt/intel/impi/2018.3.222/bin64/mpirun -genv I_MPI_DEBUG 5 -np <N*2> -ppn 2 -host <node0>,...,<nodeN> /opt/intel-mpi-benchmarks/2019/IMB-MPI1 -npmin 2 -msglog 19:21 allreduceたとえば、それぞれ 2 つのプロセスを持つ 2 つのノードをテストするには、
-np 4 -ppn 2 -host compute000,compute001と設定します。Alltoall — N 個のノードにわたる all-to-all 集団パフォーマンスを測定します。これを使用して、N 個のノード間の all-to-all 通信のパフォーマンスをテストします。各ノードでプロセスが開始され、さまざまな粒度のメッセージを通信するために消費された時間を取得します。
/opt/intel/impi/2018.3.222/bin64/mpirun -genv I_MPI_DEBUG 5 -np <N> -ppn 1 -host <node0>,...,<nodeN> /opt/intel-mpi-benchmarks/2019/IMB-MPI1 -npmin 1 -msglog 15:17 alltoallたとえば、それぞれ 1 つのプロセスを持つ 2 つのノードをテストするには、
-np 2 -ppn 1 -host compute000,compute001と設定します。ジョブを送信します。
qsub imb.pbs出力はジョブ ID を返します。
0.manager
ステップ3:ジョブ結果の表示
ジョブのステータスを確認します。
qstat -x 0.manager出力は次のようになります。
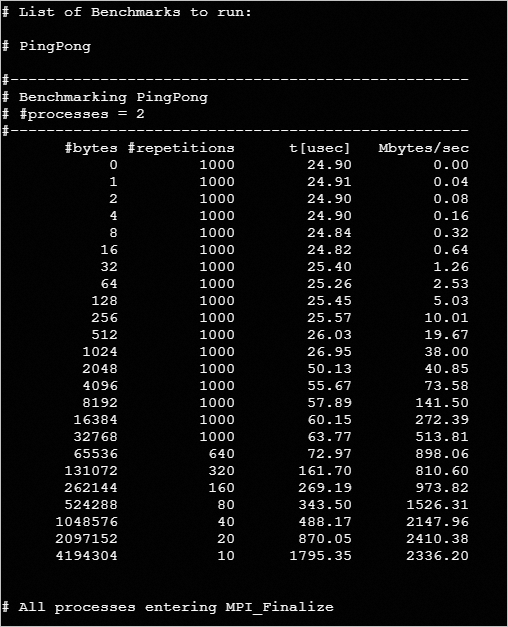
S列のRはジョブが実行中であることを意味し、Fはジョブが完了したことを意味します。Job id Name User Time Use S Queue ---------------- ---------------- ---------------- -------- - ----- 0.manager imb.pbs mpitest 00:00:04 F workqpingpong テストの結果を表示します。
cat /home/mpitest/IMB-pingpongテスト結果は次の図に示されています。