Data Transmission Service (DTS) を使用して、ApsaraDB for MongoDB のレプリカセットまたはシャードクラスターインスタンスから Lindorm ワイドテーブルへデータを同期します。このガイドでは、完全同期と増分同期の両方について説明します。
前提条件
開始する前に、以下の要件を満たしていることを確認してください。
ドイツ (フランクフルト) リージョンに、レプリカセットまたはシャードクラスター構成でデプロイされた ApsaraDB for MongoDB インスタンスがあること。
重要ソースがシャードクラスターインスタンスの場合、各シャードノードのエンドポイントを事前に申請してください。すべてのシャードノードは同じアカウントとパスワードを共有します。詳細については、「シャードのエンドポイントを申請する」をご参照ください。
ワイドテーブルエンジンを使用した Lindorm インスタンスがあり、その利用可能なストレージ容量がソース MongoDB インスタンスの総データサイズよりも大きいこと。最適な結果を得るには、ソースデータサイズよりも少なくとも 10 % 多いストレージを確保することを推奨します。詳細については、「インスタンスの作成」をご参照ください。
Lindorm インスタンス内にワイドテーブルが作成済みであること。詳細については、「Lindorm-cli を使用して LindormTable に接続および利用する」および「Lindorm Shell を使用して LindormTable に接続する」をご参照ください。
テーブルは、クォータと制限を遵守する必要があります。Apache HBase API を使用してテーブルを作成する場合は、同期タスクの設定前に列マッピングを追加します。詳細については、「Apache HBase API テーブルの列マッピングを追加する」をご参照ください。
課金
| 同期タイプ | 費用 |
|---|---|
| 完全データ同期 | 無料 |
| 増分データ同期 | 課金対象です。「課金概要」をご参照ください。 |
サポートされる同期タイプ
| タイプ | 説明 |
|---|---|
| 完全データ同期 | ソースインスタンスの選択したデータベースまたはコレクション内の既存データすべてを、宛先 Lindorm インスタンスにコピーします。 |
| 増分データ同期 | コレクションに対する挿入、更新、削除操作を継続的にレプリケートします。ファイルの増分同期中は、$set コマンドのみが同期的に適用されます。 |
スキーマ同期はサポートされていません。
必要な権限
| データベース | 必要な権限 | 権限の付与方法 |
|---|---|---|
| ソース ApsaraDB for MongoDB | ソース、admin、および local データベースに対する読み取り権限 | MongoDB データベースユーザーの権限管理 |
| 宛先 Lindorm | ターゲット名前空間に対する読み取りおよび書き込み権限 | アクセス制御の権限管理 |
制限事項
ソースデータベースの制限事項
ソースサーバーに十分なアウトバウンド帯域幅がない場合、同期速度が低下します。
同期対象のコレクションには PRIMARY KEY または一意制約が必要であり、すべてのフィールド値が一意である必要があります。そうでない場合、宛先に重複レコードが発生する可能性があります。
DTS は SRV エンドポイント経由で MongoDB インスタンスに接続できません。
ソースとして Azure Cosmos DB for MongoDB クラスターや Amazon DocumentDB エラスティッククラスターは使用できません。
単一のデータ入力は 16 MB を超えてはなりません。
ソースがシャードクラスターインスタンスの場合:
各コレクションの
_idフィールドは一意である必要があります。そうでない場合、データの不整合が発生する可能性があります。Mongos ノードの数は 10 個を超えてはなりません。
同期中に次のコマンドを実行しないでください:
shardCollection、reshardCollection、unshardCollection、moveCollection、またはmovePrimary。これらのコマンドはデータ分散を変更し、データの不整合を引き起こす可能性があります。タスクを開始する前に、ソースインスタンスに孤立ドキュメントがないことを確認してください。それらを削除する方法については、「MongoDB ドキュメント」および「DTS のよくある質問」をご参照ください。
ソースでバランサーがアクティブな場合、遅延が発生する可能性があります。
ソースに TTL インデックスが含まれている場合、同期後にデータの不整合が発生する可能性があります。
oplog が有効になっており、少なくとも 7 日分のデータを保持している必要があります。または、チェンジストリームが有効になっており、過去 7 日分をカバーしている必要があります。いずれの条件も満たされない場合、DTS は増分変更を取得できず、データ損失またはデータの不整合が発生する可能性があります。このようなケースは DTS サービスレベル契約 (SLA) の適用外です。
可能であれば、データ変更を記録するために oplog を使用してください。
チェンジストリームには MongoDB 4.0 以降が必要であり、双方向同期はサポートされていません。
非エラスティック Amazon DocumentDB クラスターの場合は、チェンジストリームを使用し、移行方法 を ChangeStream に、アーキテクチャ を Sharded Cluster に設定してください。
完全データ同期中は、データベースまたはコレクションのスキーマ、および ARRAY 型のデータを変更しないでください。完全同期のみを実行する場合は、ソースデータベースへの書き込みも行わないでください。
同期オブジェクトとしてコレクションを選択し、宛先で名前を変更する必要がある場合、1 つのタスクで最大 1,000 コレクションまでサポートされます。1,000 コレクションを超える場合は、複数のタスクを構成するか、同期オブジェクトとしてデータベース全体を選択してください。
宛先およびタスクの制限事項
ドイツ (フランクフルト) リージョン内でのタスクのみがサポートされます。
DTS は
admin、config、またはlocalデータベースからのデータ同期を実行できません。宛先 Lindorm インスタンスには、
_idまたは_valueカラムを持つコレクションがあってはなりません。トランザクションは保持されません。DTS は各トランザクションを宛先で個別のレコードに変換します。
Lindorm に書き込まれるデータは、データリクエストの使用制限の要件を満たす必要があります。
増分同期中の UPDATE および DELETE 操作について:
ワイドテーブルが Lindorm SQL を使用して作成されている場合、テーブル作成時にプライマリキー以外のカラムとして
_mongo_id_という名前のカラムを追加してください。このカラムのデータ型は、ソースの_idカラムの型と一致している必要があります。また、このカラムに対してセカンダリインデックスを作成してください。ワイドテーブルが Apache HBase API を使用して作成されている場合、カラムファミリー
fに_mongo_id_という名前のプライマリキー以外のカラムを追加してください。このカラムのデータ型は、ソースの_idカラムの型と一致している必要があります。また、このカラムに対してセカンダリインデックスを作成してください。追加カラムを追加し、抽出・変換・書き出し (ETL) 機能を使用する場合は、Lindorm インスタンスに重複データがないことを確認してください。
DTS は
ROUND(COLUMN,PRECISION)を使用して FLOAT および DOUBLE カラムから値を取得します。デフォルトの精度は、FLOAT が 38 桁、DOUBLE が 308 桁です。これらの精度設定が要件を満たしているか確認してください。DTS は失敗したタスクを最大 7 日間再開しようと試みます。ワークロードを宛先に切り替える前に、失敗したタスクを停止またはリリースするか、
REVOKEを実行して宛先に対する DTS の書き込み権限を削除してください。そうしない場合、再開されたタスクによって宛先データがソースデータで上書きされます。タスクはピーク時を避けて実行してください。完全データ同期はソースおよび宛先データベースの両方に対して読み取りおよび書き込みを行うため、サーバー負荷が増加し、宛先コレクションに一時的な断片化が発生する可能性があります。
同期遅延は、最新の同期済みデータのタイムスタンプと現在のソースタイムスタンプとの差で計算されます。ソースに長時間書き込みがない場合、このメトリックが不正確になる可能性があります。遅延値を更新するには、ソースに書き込みを実行してください。
DTS タスクが失敗した場合、テクニカルサポートが 8 時間以内に復旧を試みます。復旧中にタスクが再起動され、一部のタスクパラメーターが変更される可能性があります。ただし、データベースパラメーターは変更されません。
同期タスクの作成
ステップ 1:データ同期ページを開く
以下のいずれかの方法を使用してください。
DTS コンソール
DMS コンソール
正確な手順は、DMS コンソールのモードおよびレイアウトによって異なる場合があります。『シンプルモード』および『DMS コンソールのレイアウトとスタイルのカスタマイズ』をご参照ください。
ステップ 2:ソースおよび宛先データベースを構成する
タスクの作成 をクリックし、パラメーターを構成します。
タスク設定:
| パラメーター | 説明 |
|---|---|
| タスク名 | DTS タスクの名前です。DTS は自動的に名前を生成します。タスクを識別しやすくするため、わかりやすい名前を指定してください。名前は一意である必要はありません。 |
ソースデータベース:
| パラメーター | 説明 |
|---|---|
| 既存の接続を選択 | 登録済みのデータベースインスタンスを選択するか、空白のままにして以下のパラメーターを構成します。DMS コンソールでは、DMS データベースインスタンスの選択 ドロップダウンリストから選択します。 |
| データベースタイプ | MongoDB を選択します。 |
| アクセス方法 | Alibaba Cloud インスタンス を選択します。 |
| インスタンスリージョン | ソース ApsaraDB for MongoDB インスタンスのリージョンです。 |
| Alibaba Cloud アカウント間でデータをレプリケート | 同一アカウント内での同期の場合は いいえ を選択します。 |
| アーキテクチャ | ソースインスタンスに応じて、レプリカセット または シャードクラスター を選択します。シャードクラスター を選択した場合、シャードアカウント および シャードパスワード パラメーターも構成する必要があります。 |
| 移行方法 | DTS がソースから増分データを読み取る方法です。Oplog(推奨)は操作ログを読み取り、低遅延を実現します。ChangeStream は MongoDB チェンジストリームを使用します(MongoDB 4.0 以降が必要。双方向同期はサポートされません)。ChangeStream を使用し、アーキテクチャ パラメーターで シャードクラスター を選択した場合、シャードアカウント および シャードパスワード パラメーターを構成する必要はありません。 |
| インスタンス ID | ソース ApsaraDB for MongoDB インスタンスの ID です。 |
| 認証データベース | アカウント認証情報を格納するデータベースです。デフォルトは admin です。 |
| データベースアカウント | ソースインスタンスのデータベースアカウントです。 |
| データベースパスワード | アカウントのパスワードです。 |
| 暗号化 | 暗号化なし、SSL 暗号化、または Mongo Atlas SSL を選択します。利用可能なオプションは、アクセス方法 および アーキテクチャ の値によって異なります。アーキテクチャ が シャードクラスター で、移行方法 が Oplog の場合、SSL 暗号化は利用できません。 |
宛先データベース:
| パラメーター | 説明 |
|---|---|
| 既存の接続を選択 | 登録済みのデータベースインスタンスを選択するか、空白のままにして以下のパラメーターを構成します。DMS コンソールでは、DMS データベースインスタンスの選択 ドロップダウンリストから選択します。 |
| データベースタイプ | Lindorm を選択します。 |
| アクセス方法 | Alibaba Cloud インスタンス を選択します。 |
| インスタンスリージョン | 宛先 Lindorm インスタンスのリージョンです。 |
| インスタンス ID | 宛先 Lindorm インスタンスの ID です。 |
| データベースアカウント | 宛先インスタンスのデータベースアカウントです。 |
| データベースパスワード | アカウントのパスワードです。 |
ステップ 3:接続性をテストする
接続性をテストして次へ進む をクリックします。
DTS は、自動的にそのサーバーの CIDR ブロックをソースデータベースおよびターゲットデータベースのセキュリティ設定に追加します。アクセス方法が Alibaba Cloud インスタンス 以外の自己管理データベースを使用している場合、[接続性のテスト] をクリックして、[DTS サーバーの CIDR ブロック] ダイアログボックスで接続性を確認してください。詳細については、「DTS サーバーの CIDR ブロックを追加する」をご参照ください。
ステップ 4:同期オブジェクトを構成する
オブジェクトの構成 ステップで、以下のパラメーターを設定します。
| パラメーター | 説明 |
|---|---|
| 同期タイプ | 増分データ同期 が選択されています。完全データ同期 のみを選択することもできます。スキーマ同期は利用できません。 |
| 競合テーブルの処理モード | デフォルト設定のままにしてください。 |
| 宛先インスタンスでのオブジェクト名の大文字小文字 | 宛先インスタンスにおけるデータベース名およびコレクション名の大文字小文字を制御します。デフォルトは [DTS デフォルトポリシー] です。詳細については、「宛先インスタンスにおけるオブジェクト名の大文字小文字の指定」をご参照ください。 |
| ソースオブジェクト | 1 つ以上のオブジェクトを選択し、 |
| 選択済みオブジェクト | 各コレクションのカラムマッピングを構成します。宛先ワイドテーブルに追加されていないカラムは同期されません。 |
MongoDB フィールドを Lindorm カラムにマッピングする:
選択済みオブジェクト にコレクションを追加すると、DTS は各フィールドに対して bson_value() 式を自動的に生成します。カラムマッピングを確定させるには、以下の手順に従ってください。
データベース名を編集する(任意):選択済みオブジェクト でデータベースを右クリックし、スキーマの編集 ダイアログでターゲットスキーマ名を入力し、同期する DML 操作を選択します。OK をクリックします。
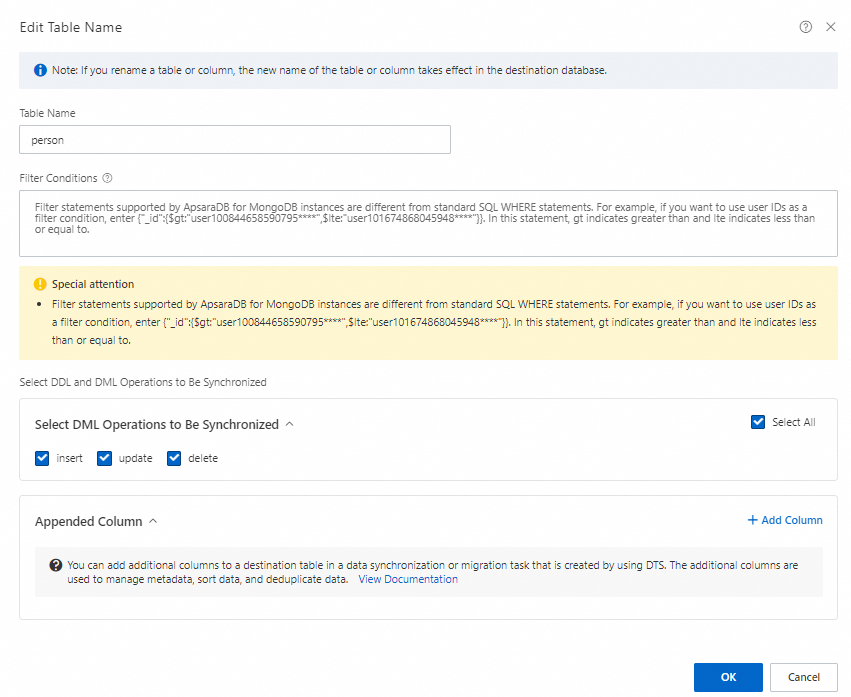
コレクション名を編集する(任意):選択済みオブジェクト でコレクションを右クリックし、テーブル名の編集 ダイアログでターゲットテーブル名を入力し、必要に応じてフィルター条件を指定するか、DML 操作を選択します。OK をクリックします。
カラムマッピングを構成する:DTS は各行に対して
bson_value()式を自動生成します。各行を確認し、カラム名、型、長さ、および 精度 を指定します。各bson_value()式内の""内の文字列は、ソース MongoDB ドキュメント内のフィールド名です。たとえば、bson_value("age")はageフィールドをマッピングします。フィールドの同期を除外するには、該当行の横にある をクリックします。
をクリックします。式が要件を満たしている場合
カラム名 を設定します:
SQL で作成されたテーブルの場合:宛先カラム名を使用します。
Apache HBase API テーブルの場合:プライマリキーカラムには
ROWを使用し、プライマリキー以外のカラムにはカラムファミリー:カラム名(例:person:name)を使用します。必要に応じて、事前にカラムマッピングを作成してください。「Apache HBase API テーブルのカラムマッピングを追加する」をご参照ください。
各カラムの 型 を選択します。ソースデータ型と互換性があることを確認してください。
必要に応じて 長さ および 精度 を設定します。
すべてのカラムに対して繰り返します。
式が要件を満たしていない場合
該当行の横にある
をクリックし、+ 新規カラム をクリックします。
カラム名、型、長さ、および 精度 を設定します。
値の割り当て に
bson_value()式を入力します。参考として、「値の割り当て例」をご参照ください。> 重要: プライマリキーカラムにはbson_value("_id")を割り当ててください。ネストされたフィールドの場合は、bson_value()内に完全な階層パスを指定します。たとえば、bson_value("person","name")を使用し、bson_value("person")は使用しないでください。親フィールドのみを使用すると、増分操作時にデータ損失またはタスク失敗が発生する可能性があります。すべてのカラムに対して繰り返します。
OK をクリックします。
ステップ 5:詳細設定を構成する
次へ:詳細設定 をクリックし、以下のパラメーターを構成します。
| パラメーター | 説明 |
|---|---|
| タスクスケジューリング用専用クラスター | デフォルトでは、DTS はタスクを共有クラスターにスケジュールします。より高い安定性が必要な場合は、専用クラスターをご購入ください。詳細については、「DTS 専用クラスターとは」をご参照ください。 |
| 接続失敗時の再試行時間 | DTS が接続失敗後にリトライを続ける時間を設定します。有効値:10~1440 分。デフォルト値:720 分。この値は少なくとも 30 分以上に設定してください。複数のタスクでソースまたは送信先が共通している場合、最も短い再試行時間が適用されます。DTS はリトライ中も課金されます。 |
| その他の問題発生時の再試行時間 | DDL または DML の失敗後に DTS がリトライを続ける時間を設定します。有効値:1~1440 分。デフォルト値:10 分。この値は少なくとも 10 分以上に設定してください。また、この値は 接続失敗時の再試行時間 より小さくする必要があります。 |
| 完全データ同期時のスロットリングを有効化 | 完全同期中にソースデータベースおよびターゲットデータベースへの負荷を制限します。ソースデータベースへのクエリ数 (QPS)、完全データ移行の RPS、および 完全移行時のデータ移行速度 (MB/s) を設定できます。このオプションは、完全データ同期 を選択した場合のみ利用可能です。 |
| 同期対象テーブルのプライマリキー _id のデータの型を統一 | コレクション内のすべてのドキュメントで _id のデータの型が同一である場合は、[はい]アラート通知設定_id に設定してください。これにより、DTS は型スキャンをスキップして完全同期を高速化します。 のデータの型が異なる場合は、[いいえ]_id に設定してください。この場合、DTS は同期前にすべての型をスキャンします。データ損失を回避するために、この設定を正しく指定してください。このオプションは、完全データ同期 を選択した場合のみ利用可能です。 |
| 増分データ同期時のスロットリングを有効化 | 増分同期中に送信先への負荷を制限します。増分データ同期の RPS および 増分同期時のデータ同期速度 (MB/s) を設定できます。 |
| 環境タグ | DTS インスタンスの環境を識別するための任意のタグです。 |
| ETL の設定 | 同期中にデータを変換する ETL 機能を有効化します。[はい] に設定すると、コードエディタで処理文を入力できます。詳細については、「データ移行またはデータ同期タスクでの ETL の設定」および「Apache HBase API テーブル向けの ETL の例」をご参照ください。送信先テーブルが Apache HBase API を使用して作成されている場合は、ETL スクリプトで含めるカラムと除外するカラムを指定してください。デフォルトでは、トップレベルのフィールドは f カラムファミリーに格納されます。以下のコードは、_id および name 以外のカラムのデータ行を動的カラムとして送信先テーブルに書き込む方法を示しています:script:e_expand_bson_value("*", "_id,name")。DTS は、ETL タスクで定義されていないカラムや追加カラムを同期しません。 |
| モニタリングとアラート | タスクが失敗した場合や同期遅延がしきい値を超えた場合にアラートを受け取るには、[はい] に設定してください。アラートのしきい値および通知設定を構成します。詳細については、「DTS タスク作成時のモニタリングとアラートの設定」をご参照ください。 |
ステップ 6:事前チェックを実行する
次へ:タスク設定を保存して事前チェック をクリックします。
このタスク構成の OpenAPI パラメーターを表示するには、次へ:タスク設定を保存して事前チェック にポインターを合わせ、次へ進む前に OpenAPI パラメーターをプレビュー をクリックしてください。
DTS はタスク開始前に事前チェックを実行します。事前チェックが失敗した場合は、以下を実行してください。
失敗した項目の横にある 詳細を表示 をクリックして問題を解決し、再度事前チェック をクリックします。
無視可能なアラートが表示された場合は、アラートの詳細を確認 をクリックし、詳細を表示 ダイアログで 無視 > OK をクリックしてから、再度事前チェック をクリックします。アラートを無視すると、データの不整合が発生する可能性があることにご注意ください。
ステップ 7:インスタンスを購入する
成功率 が 100% に達したら、次へ:インスタンスを購入 をクリックします。
購入 ページで、以下のパラメーターを構成します。
| パラメーター | 説明 |
|---|---|
| 課金方法 | サブスクリプション:固定期間分を前払い。長期利用にコスト効率的です。従量課金:1 時間単位で課金。短期利用に適しています。不要になったらインスタンスをリリースして、不要な課金を回避してください。 |
| リソースグループ設定 | 同期インスタンスのリソースグループです。デフォルト:デフォルトリソースグループResource Management とは |
| インスタンスクラス | 同期スループットクラスです。詳細については、「データ同期インスタンスのインスタンスクラス」をご参照ください。 |
| サブスクリプション期間 | サブスクリプション 課金方法で利用可能です。オプション:1~9 か月、または 1、2、3、5 年。 |
Data Transmission Service (従量課金) サービス利用規約 を読み、同意します。
購入して開始 をクリックし、確認ダイアログで OK をクリックします。
タスクがタスクリストに表示されます。ここから進行状況をモニターできます。
Apache HBase API を呼び出して作成されたテーブルのカラムマッピングを追加する例
次の例では SQL Shell を使用します。Lindorm インスタンスのバージョンは 2.4.0 以降である必要があります。
カラムマッピングを作成します:
ALTER TABLE test MAP DYNAMIC COLUMN f:_mongo_id_ HSTRING/HINT/..., person:name HSTRING, person:age HINT;セカンダリインデックスを作成します:
CREATE INDEX idx ON test(f:_mongo_id_);
Apache HBase API を呼び出して作成されたテーブルの ETL タスクを構成する例
ApsaraDB for MongoDB のソースドキュメント:
{
"_id": 0,
"person": {
"name": "cindy0",
"age": 0,
"student": true
}
}ETL スクリプト — _id を除くすべてのトップレベルフィールドを動的カラムとして展開します:
script:e_expand_bson_value("*", "_id")同期結果:

値の割り当て例
ネストされたフィールドの bson_value() 式を構成する際の参考として、この例を使用してください。
ソースドキュメント構造:
{
"_id": "62cd344c85c1ea6a2a9f****",
"person": {
"name": "neo",
"age": "26",
"sex": "male"
}
}Lindorm の宛先テーブルスキーマ:
| カラム名 | 型 |
|---|---|
| id | STRING |
| person_name | STRING |
| person_age | INT |
カラム構成:
bson_value() 内では常に完全な階層パスを指定してください。bson_value("person","name") の代わりに bson_value("person") を使用すると、DTS はネストされたフィールドへの増分データの書き込み時に失敗し、データ損失またはタスク失敗が発生する可能性があります。
| カラム名 | 型 | 値の割り当て |
|---|---|---|
| id | STRING | bson_value("_id") |
| person_name | STRING | bson_value("person","name") |
| person_age | BIGINT | bson_value("person","age") |