Data Transmission Service (DTS) を使用して、ApsaraDB for MongoDB のレプリカセットまたはシャードクラスターインスタンスから Lindorm のワイドテーブルインスタンスへデータを移行します。DTS は完全なデータ移行および増分データ移行をサポートしているため、アプリケーションを停止せずに移行が可能です。
移行タイプの選択
アプリケーションがダウンタイムを許容できるかどうかに応じて、移行タイプを選択してください。
| 移行タイプ | 使用するタイミング | 必要なダウンタイム |
|---|---|---|
| 完全なデータ移行のみ | アプリケーションがメンテナンスウィンドウを許容できる場合。移行開始前にソースへの書き込みを停止します。 | あり — 移行中はソースへの書き込みを停止します |
| 完全 + 増分データ移行 | アプリケーションを移行中にオンラインで維持する必要がある場合。DTS は切り替え(cut over)まで継続的な変更を同期します。 | なし — 任意のタイミングで切り替え可能です |
完全なデータ移行のみを選択した場合、タスク開始前にソースデータベースへの書き込みを停止してください。完全移行のみの実行中にソースへの書き込みを行うと、データの不整合が発生します。
前提条件
開始する前に、以下の点を確認してください。
ドイツ (フランクフルト) リージョン内でのみ移行タスクがサポートされています。
ApsaraDB for MongoDB のソースインスタンスは、レプリカセット または シャードクラスター アーキテクチャを使用している必要があります。
ワイドテーブルエンジンを搭載した Lindorm インスタンスが作成済みである必要があります。「インスタンスの作成」をご参照ください。
Lindorm インスタンス内にワイドテーブルが作成済みである必要があります。「Lindorm-cli を使用した LindormTable への接続および利用方法」または「Lindorm Shell を使用した LindormTable への接続方法」をご参照ください。
宛先インスタンスの利用可能なストレージ容量が、ソースインスタンス内の合計データサイズより少なくとも 10 % 大きいことを確認してください。
送信先に作成するオブジェクトは、クォータと制限に準拠している必要があります。
シャードクラスターをソースとする場合:
シャードノードのエンドポイントが設定済みであり、すべてのシャードノードで同一のアカウントおよびパスワードが使用されている必要があります。「シャード向けエンドポイントの申請」をご参照ください。
移行対象のすべてのコレクションにおける
_idフィールドが、シャード間で一意である必要があります。Mongos ノードの数が 10 を超えないようにしてください。
増分データ移行の場合:
UPDATE および DELETE 操作を移行するには、タスク開始前に Lindorm のワイドテーブルに、非プライマリキー列として
_mongo_id_を追加してください。SQL で作成されたテーブルの場合: 列のデータ型は、ソースの ApsaraDB for MongoDB インスタンスにおける
_id列の型と一致させる必要があります。この列に対してセカンダリインデックスを作成してください。Apache HBase API で作成されたテーブルの場合: 列はカラムファミリー
fに所属する必要があります。データ型は_id列の型と一致させる必要があります。この列に対してセカンダリインデックスを作成してください。ETL 機能を活用して追加の列を追加する場合は、Lindorm インスタンスに重複データが存在しないことを確認してください。
ソースデータベースで oplog 機能が有効化されており、操作ログが最低 7 日間保持されている必要があります。あるいは、change streams が有効化されており、DTS が過去 7 日間の変更をサブスクライブ可能である必要があります。
Apache HBase API を使用してワイドテーブルを作成した場合、移行タスクの構成前にカラムマッピングを設定してください。「Apache HBase API テーブルのカラムマッピングの追加」をご参照ください。
課金
| 移行タイプ | タスク構成料金 | データ転送料金 |
|---|---|---|
| 完全なデータ移行 | 無料 | 無料ですが、アクセス方法 が [パブリックIPアドレス] に設定されている場合は、インターネットトラフィックに対して課金されます。詳しくは、「課金対象項目」をご参照ください。 |
| 増分データ移行 | 課金対象です。「課金概要」をご参照ください。 | — |
移行タイプ
| 移行タイプ | 説明 |
|---|---|
| 完全なデータ移行 | DTS は、移行対象のオブジェクトの既存データを、ソースの ApsaraDB for MongoDB インスタンスから宛先の Lindorm インスタンスへ移行します。 説明 DTS は、データベースおよびコレクション単位での完全なデータ移行をサポートしています。 |
| 増分データ移行 | 完全なデータ移行が完了した後、DTS はソースの ApsaraDB for MongoDB インスタンスから宛先の Lindorm インスタンスへ増分データを移行します。文書に対する INSERT、UPDATE、DELETE 操作のみが移行されます。UPDATE 操作については、$set を使用した更新のみが移行されます。 |
必要な権限
| データベース | 完全なデータ移行 | 増分データ移行 |
|---|---|---|
| ソース ApsaraDB for MongoDB | ソースデータベースの読み取り | ソースデータベース、admin データベース、および local データベースでの読み取り |
| 宛先の Lindorm インスタンス | 読み取りおよび書き込み権限 | 読み取りおよび書き込み権限 |
「MongoDB データベースユーザーの権限を管理する」および「ユーザーの管理」をご参照ください。
MongoDB から Lindorm へのデータ移行
以下の手順では、Lindorm SQL ステートメントで作成したワイドテーブルを例として説明します。
ステップ 1:データ移行ページを開く
以下のいずれかの方法を使用してください。
DTS コンソール
DMS コンソール
実際の手順は、DMS コンソールのモードおよびレイアウトによって異なる場合があります。詳しくは、「シンプルモード」および「DMS コンソールのレイアウトとスタイルのカスタマイズ」をご参照ください。
ステップ 2:ソースおよび宛先データベースの構成
タスクの作成 をクリックし、以下の表に記載されているパラメーターを構成してください。
ソースデータベースのパラメーター
| パラメーター | 説明 |
|---|---|
| タスク名 | DTS タスクの名前です。DTS が自動的に名前を生成しますが、タスクを容易に識別できるよう、意味のある名前を指定することを推奨します。名前は一意である必要はありません。 |
| 既存の接続を選択 | MongoDB インスタンスがすでに DTS に登録済みの場合は、一覧から選択してください。DTS が接続パラメーターを自動入力します。それ以外の場合は、以下のパラメーターを手動で構成してください。 |
| データベースタイプ | MongoDB を選択します。 |
| アクセス方法 | クラウドインスタンス を選択します。 |
| インスタンスリージョン | ソースの ApsaraDB for MongoDB インスタンスが配置されているリージョンです。 |
| Alibaba Cloud アカウント間でのデータ複製 | いいえ を選択します。 |
| アーキテクチャ | ソースインスタンスのアーキテクチャです。本例では レプリカセット を選択します。ソースが シャードクラスター アーキテクチャを使用する場合は、シャードアカウント および シャードパスワード も構成してください。 |
| 移行方法 | DTS がソースから増分変更を取得する方法です。Oplog(推奨) — oplog 機能が有効化されている場合に利用可能です。ApsaraDB for MongoDB インスタンスでは、oplog 機能がデフォルトで有効化されています。低遅延の増分移行に適しています。ChangeStreamChange Streams — change streams が有効化されている場合に利用可能です。弾力性のない Amazon DocumentDB クラスターで必須です。MongoDB v4.0 以降が必要です。シャードクラスター を アーキテクチャ として選択した場合、この方法を使用すると シャードアカウント および シャードパスワード の構成は不要です。 |
| インスタンス ID | ソースの ApsaraDB for MongoDB インスタンスの ID です。 |
| 認証データベース | アカウントおよびパスワードを格納するデータベースです。デフォルト値:admin。 |
| データベースアカウント | ソースインスタンスのデータベースアカウントです。 |
| データベースパスワード | データベースアカウントのパスワードです。 |
| 暗号化 | 要件に応じて、暗号化なし、SSL 暗号化、または Mongo Atlas SSL を選択します。利用可能なオプションは、アクセス方法 および アーキテクチャ の選択内容によって異なります。DTS コンソールに表示されるオプションが適用されます。制限事項:アーキテクチャ が シャードクラスター で、移行方法 が Oplog の場合、SSL 暗号化 は利用できません。 |
宛先データベースのパラメーター
| パラメーター | 説明 |
|---|---|
| 既存の接続を選択 | Lindorm インスタンスがすでに DTS に登録済みの場合は、一覧から選択してください。それ以外の場合は、以下のパラメーターを手動で構成してください。 |
| データベースタイプ | Lindorm を選択します。 |
| アクセス方法 | Alibaba Cloud インスタンス を選択します。 |
| インスタンスリージョン | 宛先の Lindorm インスタンスが配置されているリージョンです。 |
| インスタンス ID | 宛先の Lindorm インスタンスの ID です。 |
| データベースアカウント | 宛先の Lindorm インスタンスのデータベースアカウントです。 |
| データベースパスワード | データベースアカウントのパスワードです。 |
ステップ 3:接続性のテストと続行
ページ下部の 接続性のテストと続行 をクリックします。
DTS は、ソースデータベースおよびターゲットデータベースの両方にアクセスできる必要があります。DTS サーバーの CIDR ブロックが、両方のデータベースのセキュリティ設定に追加されていることを確認してください。詳細については、「DTS サーバーの CIDR ブロックをオンプレミスデータベースのセキュリティ設定に追加する」をご参照ください。ソースまたはターゲットが、[Alibaba Cloudインスタンス]を介さずにアクセスされる自己管理データベースである場合、[DTS サーバーの CIDR ブロック]ダイアログボックスで[接続のテスト]をクリックします。
ステップ 4:移行対象オブジェクトの構成
オブジェクトの構成 ページで、以下のパラメーターを設定してください。
移行タイプおよびオブジェクト
| パラメーター | 説明 |
|---|---|
| 移行タイプ | 一度限りの移行には 完全なデータ移行 を選択します。移行中にソースと宛先を同期させ、ダウンタイムを最小限に抑えるには、完全なデータ移行 および 増分データ移行 の両方を選択します。 |
| 競合するテーブルの処理モード | 構成は不要です。 |
| 宛先インスタンスにおけるオブジェクト名の大文字小文字の扱い | 宛先のデータベース名およびコレクション名の大文字・小文字の使用ポリシー。デフォルト: [DTS デフォルトポリシー]。「宛先インスタンスでのオブジェクト名の大文字・小文字の使用方法を指定する」をご参照ください。 |
| ソースオブジェクト | 移行するコレクションを選択し、 |
選択済みのオブジェクトの構成
選択済みのオブジェクト 内の各コレクションについて、スキーマ名、テーブル名、およびカラムマッピングを構成します。
以下は、ソースの MongoDB 文書が Lindorm のワイドテーブルの行にどのようにマップされるかを示す例です。
ソース文書(ApsaraDB for MongoDB)
{
"_id": "62cd344c85c1ea6a2a9f****",
"person": {
"name": "neo",
"age": "26",
"sex": "male"
}
}宛先テーブルの行(Lindorm)
| カラム名 | 型 | 値の式 |
|---|---|---|
id | STRING | bson_value("_id") |
person_name | STRING | bson_value("person","name") |
person_age | BIGINT | bson_value("person","age") |
スキーマ、テーブル名、カラムマッピングを構成するには、以下の手順を実行します。
スキーマ名の編集:
選択済みのオブジェクト で、コレクションを含むデータベースを右クリックします。
スキーマ編集ダイアログボックスで、スキーマ名 フィールドに、Lindorm インスタンスで使用するデータベース名を入力します。
(任意)同期する DDL および DML 操作の選択 で、増分データ移行中に移行する操作を選択します。
OK をクリックします。
テーブル名の編集:
選択済みのオブジェクト で、コレクションを右クリックします。
テーブル名編集ダイアログボックスで、テーブル名 フィールドに、Lindorm インスタンスで使用するテーブル名を入力します。
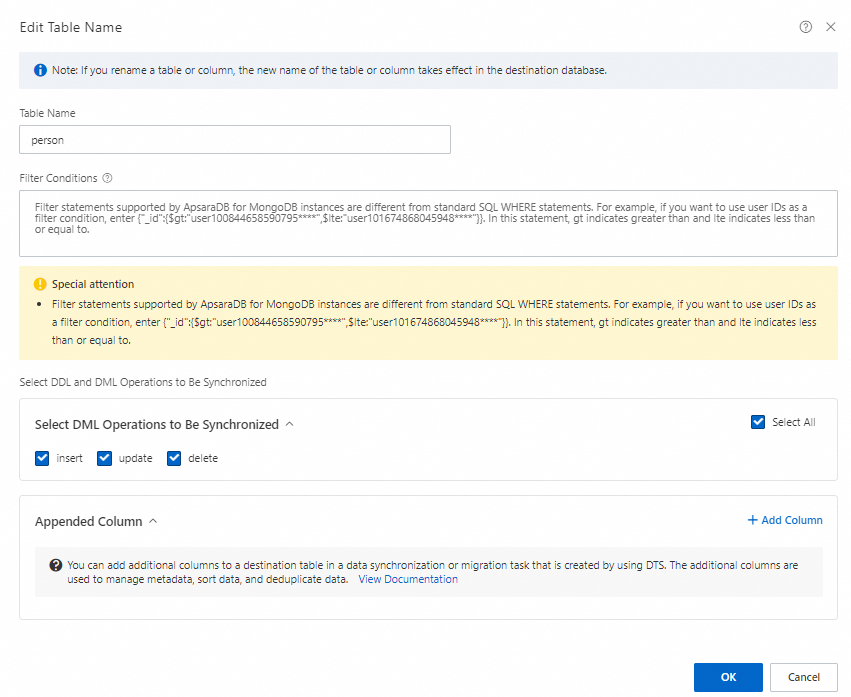
(任意)フィルター条件を指定します。「フィルター条件の指定」をご参照ください。
(任意)同期する DDL および DML 操作の選択 で、増分データ移行中に移行する操作を選択します。
ソースフィールドと宛先カラムのマッピング: DTS は、ソースコレクション内の各フィールドを
bson_value()式を使用して自動的にマップし、カラムに割り当てます。bson_value()式内で""で囲まれたフィールド名は、ソースの MongoDB インスタンスにおけるフィールド名です。たとえば、bson_value("age")はageフィールドをマップします。(任意)カラムの横にある アイコンをクリックして、移行不要なフィールドを削除できます。また、
アイコンをクリックして、移行不要なフィールドを削除できます。また、bson_value()式が要求される宛先カラムと一致していることを確認してください。値の割り当て 列の
bson_value()式内で、MongoDB のフィールド名を確認します。""内のフィールドが MongoDB のフィールド名です。たとえば、式がbson_value("age")の場合、この式は MongoDB のageフィールドをマップします。(任意)移行不要なフィールドの横にある
アイコンをクリックします。説明移行不要なフィールドを削除するには、そのフィールドの行にある
をクリックします。移行するフィールドを構成します。
bson_value()式が要件を満たすかどうかに応じて、次の手順を実行します。式が要件を満たすフィールド
宛先テーブルの カラム名 を入力します。
説明SQL で作成されたテーブルの場合:テーブルで定義されたカラム名を使用します。
Apache HBase API で作成されたテーブルの場合:プライマリキー列には ROW を使用し、その他のカラムには カラムファミリー:カラム名 形式(例:person:name)を使用します。まずカラムマッピングを設定してください。「Apache HBase API テーブルのカラムマッピングの追加」をご参照ください。
カラムデータの 型 を選択します。
重要宛先カラムのデータ型は、ソースフィールドの型と互換性がある必要があります。
(任意)長さ および 精度 を設定します。
すべての必要なフィールドをマップするまで、これらの手順を繰り返します。
式が要件を満たさないフィールド
説明たとえば、階層構造(親子構造)を持つフィールドです。
カラムの横にある
アイコンをクリックします。+ カラムの追加 をクリックします。

カラム名、型、長さ、および 精度 を設定します。
値の割り当て 下のテキストボックスに、
bson_value()式を入力します。詳細については、「値の割り当ての例」をご参照ください。重要常にプライマリキー列を
bson_value("_id")として割り当てます。ネストされたフィールドの場合は、式内でフィールドとサブフィールドの両方を指定します — たとえば、
bson_value("person","name")。単にbson_value("person")を使用すると、サブフィールドのデータが失われます。
各フィールドについて、これらの手順を繰り返します。
OK をクリックします。
ステップ 5:高度な設定の構成
次へ:高度な設定 をクリックし、以下のパラメーターを構成します。
| パラメーター | 説明 |
|---|---|
| タスクスケジューリング専用クラスター | デフォルトでは、DTS はタスクを共有クラスターにスケジュールします。より高い安定性を得るには、専用クラスターをご購入ください。詳細については、「DTS 専用クラスターとは」をご参照ください。 |
| 接続失敗時の再試行時間 | ソースまたは宛先データベースに到達不能な場合の再試行期間です。有効範囲:10~1,440 分。デフォルト:720 分。少なくとも 30 分に設定することを推奨します。この期間内に DTS が再接続できた場合、移行は自動的に再開されます。この期間内に再接続できなかった場合、タスクは失敗します。 |
| その他の問題発生時の再試行時間 | DDL または DML 操作の失敗時の再試行期間です。有効範囲:1~1,440 分。デフォルト:10 分。10 分を超える値を設定することを推奨します。この値は 接続失敗時の再試行時間 よりも小さくする必要があります。 |
| 完全なデータ移行のレート制御を有効化 | 完全移行中の読み取り/書き込みレートを制御し、ソースおよび宛先の負荷を軽減します。QPS(ソースへのクエリ/秒)、完全データ移行の RPS、および 完全移行のデータ移行速度(MB/s) を構成します。完全なデータ移行 が選択されている場合にのみ利用可能です。 |
| 同期対象のテーブルでプライマリキー _id に単一のデータ型のみを使用 | コレクション内のすべての文書において、_id フィールドのデータ型が一貫しているかどうかを指定します。はいアラート通知設定 — DTS は完全移行中にデータ型のスキャンをスキップします。いいえ — DTS は完全移行中に _id のデータ型をスキャンします。完全なデータ移行 が選択されている場合にのみ利用可能です。データに応じて有効化してください。誤った設定によりデータ損失が発生する可能性があります。 |
| 増分データ移行のレート制御を有効化 | 増分移行のレートを制御します。増分データ移行の RPS および 増分移行のデータ移行速度(MB/s) を構成します。増分データ移行 が選択されている場合にのみ利用可能です。 |
| 環境タグ | DTS インスタンスを識別するための任意のタグです。 |
| ETL の構成 | 抽出・変換・書き出し(ETL)機能を有効化して、移行中にデータを変換します。はいデータ移行またはデータ同期タスクでの ETL 設定 — コードエディタにデータ処理ステートメントを入力します。「」をご参照ください。いいえ — ETL を無効化します。Apache HBase API で作成されたテーブルの場合、ETL スクリプトを使用して移行するカラムを指定します。デフォルトでは、すべての最上位レベルのフィールドがカラムファミリー f に送られます。例:script:e_expand_bson_value("*", "_id,name") は、_id および name を除くすべてのフィールドを動的カラムとして書き込みます。DTS は、ETL タスクに含まれていない追加カラムやカラムは移行しません。追加カラムを追加して ETL を使用する場合は、Lindorm インスタンスに重複データが存在しないことを確認してください。 |
| モニタリングとアラート | タスクの失敗または高い移行遅延に対するアラートを設定します。はい — アラートのしきい値と通知の連絡先を設定します。「DTS タスクを作成するときにモニタリングとアラートを設定する」をご参照ください。いいえ — アラート機能はありません。 |
ステップ 6:事前チェックの実行と設定の保存
次へ:タスク設定の保存と事前チェック をクリックします。
保存前にこのタスク構成の API パラメーターを表示するには、次へ:タスク設定の保存と事前チェック の上にポインターを合わせ、OpenAPI パラメーターのプレビュー をクリックします。
DTS は移行開始前に事前チェックを実行します。事前チェックの失敗項目に対処してください。
失敗した項目の場合: 詳細の表示 をクリックし、問題を修正した後、再び事前チェック をクリックします。
警告項目の場合:
警告を無視できない場合は、問題を修正して再度事前チェックを実行してください。
警告を無視できる場合は、警告の詳細の確認 > 無視 > OK をクリックし、その後 再び事前チェック をクリックします。警告を無視すると、データの不整合が発生する可能性があります。
ステップ 7:インスタンスの購入および起動
成功率 が 100% に達するまで待機し、次へ:インスタンスの購入 をクリックします。
インスタンスの購入 ページで、以下のパラメーターを構成します。
パラメーター 説明 リソースグループ データ移行インスタンスのリソースグループ。 デフォルト: [デフォルトリソースグループ]。 詳細については、「Resource Management とは インスタンスクラス 移行スループット階層です。クラスが高くなるほど、移行速度が速くなります。詳細については、「データ移行インスタンスのインスタンスクラス」をご参照ください。 Data Transmission Service(従量課金)サービス利用規約 を読み、チェックボックスをオンにしてください。
購入および起動 をクリックし、確認ダイアログボックスで OK をクリックします。
移行ステータスの確認
データ移行 ページで、タスクのステータスを確認します。
完全なデータ移行のみ: 完了時にタスクが自動的に停止します。ステータスは 完了 に変わります。
完全 + 増分データ移行: 増分移行は継続的に実行され、停止しません。ステータスは 実行中 と表示されます。宛先データベースへの切り替え準備が整ったら、手動でタスクを停止またはリリースしてください。
ワークロードを宛先データベースに切り替える前に、失敗したタスクを停止またはリリースしてください。あるいは、宛先データベース上の DTS アカウントの書き込み権限を取り消すために REVOKE を実行してください。この手順を省略した場合、DTS が 7 日以内に失敗したタスクを自動再開すると、ソースからのデータが宛先のデータを上書きする可能性があります。
制限事項
ソースデータベースの制限事項
ソースサーバーには十分なアウトバウンド帯域幅が必要です。帯域幅が不足していると、移行速度が低下します。
コレクションには PRIMARY KEY または UNIQUE 制約が必要であり、すべてのフィールドが一意である必要があります。そうでない場合、宛先に重複レコードが発生する可能性があります。
DTS は
admin、config、またはlocalデータベースからデータを移行できません。DTS は SRV エンドポイント経由で MongoDB に接続できません。
コレクションを移行対象として選択し、名前を変更する場合、1 つのタスクで最大 1,000 個のコレクションを移行できます。この上限を超えるとリクエストエラーが発生します。移行を複数のタスクに分割してください。
完全なデータ移行の制限事項
完全なデータ移行中に、配列型の更新を含むデータベースまたはコレクションのスキーマ変更を行わないでください。スキーマ変更により、タスクが失敗したりデータの不整合が発生したりする可能性があります。
完全なデータ移行のみを実行する場合、ソースデータベースへの書き込みを行わないでください。ソースへの書き込みにより、データの不整合が発生します。
完全移行中の同時 INSERT 操作により、宛先コレクションに断片化が発生します。宛先コレクションで使用されるストレージは、ソースよりも大きくなります。
増分データ移行の制限事項
文書に対する INSERT、UPDATE、DELETE 操作のみが移行されます。UPDATE 操作については、
$setを使用した更新のみが移行されます。oplog 機能が有効化されており、操作ログが最低 7 日間保持されている必要があります。あるいは、change streams が有効化されており、DTS が過去 7 日間の変更をサブスクライブ可能である必要があります。これらの要件を満たさない場合、DTS が操作ログを取得できず、タスクが失敗する可能性があります。例外的なケースでは、データの不整合または損失が発生する可能性があります。
可能な限り、oplog 機能を使用してデータ変更を取得してください。change streams は、ソースが MongoDB v4.0 以降を実行している場合にのみ使用してください。
トランザクション情報は保持されません。トランザクションは単一のレコードに変換されます。
DTS は、宛先で最新に移行されたレコードのタイムスタンプとソースの現在のタイムスタンプに基づいて移行遅延を計算します。ソースで長期間更新が行われない場合、遅延値が不正確になる可能性があります。遅延を更新するには、ソースに更新を書き込んでください。
シャードクラスターの制限事項
_idフィールドは、すべてのシャード間で一意である必要があります。_id値が重複すると、データの不整合が発生します。Mongos ノードの数は 10 を超えてはなりません。
タスク実行中に、移行対象のオブジェクトに対して以下のコマンドを実行しないでください:
shardCollection、reshardCollection、unshardCollection、moveCollection、movePrimary。これらのコマンドはデータ分布を変更し、データの不整合を引き起こします。ソースのシャードクラスターで Balancer がアクティブな場合、移行遅延が発生する可能性があります。
Lindorm 宛先の制限事項
宛先の Lindorm インスタンスには、
_idまたは_valueという名前のカラムを含むコレクションを含めることはできません。このようなカラムが存在する場合、タスクは失敗します。移行されたデータは、データリクエストの使用制限に準拠する必要があります。
FLOAT の精度はデフォルトで 38 桁、DOUBLE の精度はデフォルトで 308 桁です。DTS はこれらの値を取得するために
ROUND(COLUMN,PRECISION)を使用します。移行開始前に、精度設定がビジネス要件を満たしていることを確認してください。ソースに TTL インデックスが含まれている場合、移行後にデータの不整合が発生する可能性があります。
Azure Cosmos DB および Amazon DocumentDB の制限事項
Azure Cosmos DB for MongoDB クラスターおよび Amazon DocumentDB エラスティッククラスターの場合:完全なデータ移行のみがサポートされています。
弾力性のない Amazon DocumentDB クラスターの場合:change streams を有効化し、移行方法 を ChangeStream に、アーキテクチャ を シャードクラスター に設定します。
その他の運用に関する注意事項
移行を開始する前に、ソースおよび宛先データベースのパフォーマンスへの影響を評価してください。可能な場合は、ピーク時を避けて移行を実行してください。完全なデータ移行では、両方のデータベースで読み取りおよび書き込みリソースが使用され、サーバー負荷が増加する可能性があります。
DTS タスクが失敗した場合、DTS テクニカルサポートは 8 時間以内に復旧を試みます。復旧中、タスクが再起動される場合や、パラメーターが変更される場合があります。変更されるのは DTS タスクのパラメーターのみであり、データベースのパラメーターは変更されません。変更される可能性のあるパラメーターには、「DTS インスタンスのパラメーターを変更する」で説明されているものも含まれます。
Apache HBase API を呼び出して作成したテーブルのカラムマッピング追加の例
Lindorm インスタンスのテーブルエンジンバージョンは 2.4.0 以降である必要があります。
本例では、SQL Shell を使用します。
テーブルのカラムマッピングを作成します。
ALTER TABLE test MAP DYNAMIC COLUMN f:_mongo_id_ HSTRING/HINT/..., person:name HSTRING, person:age HINT;_mongo_id_カラムにセカンダリインデックスを作成します。CREATE INDEX idx ON test(f:_mongo_id_);
Apache HBase API を呼び出して作成したテーブルの ETL タスク構成の例
ApsaraDB for MongoDB のソース文書
{
"_id": 0,
"person": {
"name": "cindy0",
"age": 0,
"student": true
}
}ETL スクリプト
script:e_expand_bson_value("*", "_id")移行結果

値の割り当ての例
ソース文書の構造
{
"_id": "62cd344c85c1ea6a2a9f****",
"person": {
"name": "neo",
"age": "26",
"sex": "male"
}
}宛先テーブルのスキーマ
| カラム名 | 型 |
|---|---|
id | STRING |
person_name | STRING |
person_age | INT |
カラム割り当ての構成
ネストされたフィールドの場合は、bson_value() 式内でフィールドとサブフィールドの両方を指定してください。たとえば、bson_value("person") のみを使用すると、name、age、sex などのサブフィールドは移行されず、親フィールドのみが参照されます。これにより、データ損失またはタスク失敗が発生します。
| カラム名 | 型 | 値の式 |
|---|---|---|
id | STRING | bson_value("_id") |
person_name | STRING | bson_value("person","name") |
person_age | BIGINT | bson_value("person","age") |