Data Security Center (DSC) は、堅牢なデータ検出および分類機能を提供します。識別タスクを管理することで、DSC は接続されたデータ資産をスキャンして機密情報を検出します。その後、機密度レベルとタイプに基づいてこのデータを分類し、等級付けします。この可視性により、正確なアクセス制御を実装し、全体的なデータセキュリティ体制を向上させることができます。このトピックでは、機密データを識別するための識別タスクの設定および管理方法について説明します。
前提条件
スキャン対象のデータ資産にアクセスするために、DSC に権限を付与する必要があります。詳細については、「資産の権限付与」をご参照ください。
識別タスクの概要
識別タスクは、特定の識別ルール ( [識別テンプレート] で定義) を使用して、接続された資産内のデータをスキャンします。スキャン結果を生成し、識別された機密データに自動的にタグを付けます。テンプレートの詳細については、「識別テンプレートの表示と設定」をご参照ください。
タスクタイプ
DSC は、デフォルトタスクとカスタム識別タスクの 2 種類の識別タスクをサポートしています。
デフォルトタスク
アセットを承認すると、DSC はメイン識別テンプレートを使用して、そのアセットインスタンスのスキャンタスクを自動的に作成します。これらはデフォルトタスクと呼ばれます。
次の表に、デフォルトタスクのロジックと動作を示します。
設定 | 説明 |
識別テンプレート | デフォルトタスクは、常に DSC に設定されているメイン識別テンプレートを使用します。これは個々のタスクでは変更できません。
|
スキャントリガーとサイクル (デフォルト) |
注:2 つのスキャンの最小間隔は 24 時間です。 |
スキャン範囲 | すべての権限付与済み資産に対して、スキャン範囲は次のように適用されます:
メイン識別テンプレートへの変更は、即時スキャンをトリガーしません。新しいルールは、次回のスケジュールされた実行時にのみ適用されます。 |
カスタム識別タスク
1 つ以上の有効な識別テンプレートを使用して特定のデータ資産をスキャンする必要がある場合は、カスタム識別タスクを作成します。テンプレートが現在無効になっている場合は、カスタムタスクで選択する前に有効にする必要があります。詳細については、「識別テンプレートを有効にする」をご参照ください。
スキャンメカニズムと制限
制限事項
検出カバー率とシステムパフォーマンスのバランスを取るため、DSC は特定のサンプリングルールと制限を適用します。
構造化データ/ビッグデータ (RDS、PolarDB、Tablestore、MaxCompute):デフォルトでは、テーブルの最初の 200 行がサンプリングされます。この制限は手動で最大 1,000 行まで増やすことができます。サンプリングされた行内では、フィールドごとに最初の 10 KB のデータのみがスキャンされます。
非構造化データ (OSS または Simple Log Service):
200 MB を超えるファイルはスキップされます。200 MB 以下のファイルはスキャンされます。
OSS に保存されているデータ:
圧縮またはアーカイブされたファイルの場合、最初の 1,000 個の子ファイルのみがスキャンされます。
単一の OSS バケットをスキャンする場合、最大 4 つのオブジェクトが同時にスキャンされます。
QPS 制限:単一のスキャンタスクは、OSS バケットに対して毎秒 100 API リクエストに制限されます。
帯域幅制限:単一のスキャンタスクは、OSS バケットからの内部アウトバウンド帯域幅が 200 MB/s に制限されます。
DSC は、テキスト、オフィスドキュメント、画像、デザインファイル、コード、バイナリ、アーカイブ、アプリケーション、オーディオ、ビデオ、化学構造ファイルなど、800 以上の OSS ファイルタイプのスキャンをサポートしています。詳細については、「識別可能な OSS ファイルタイプ」をご参照ください。
識別タスクの制限に関する包括的な詳細については、「制限事項」をご参照ください。
スキャン対象オブジェクト
データベース資産:
<インスタンス>/<データベース>/<テーブル>。各テーブルは単一のデータオブジェクトを表します。ビッグデータ:
<インスタンス>/<テーブル>。各テーブルは単一のデータオブジェクトを表します。OSS 資産:
<バケット>/<ファイル>。各ファイルは単一のデータオブジェクトを表します。Simple Log Service 資産:
<プロジェクト>/<Logstore>/<時間セグメント>。データは 5 分間のセグメントで処理されます。各 5 分間のセグメントは単一のデータオブジェクトを表します。
スキャン速度
以下の見積もりは参考用です。実際のスキャン速度は、システムの負荷やデータの複雑さによって異なる場合があります。
構造化データ (RDS、PolarDB、Tablestore、MaxCompute):1,000 以上のテーブルを含む大規模なデータベースの場合、スキャンレートは毎分約 1,000 カラムです。
非構造化データ (OSS、SLS):1 TB のデータのスキャンには通常 6〜48 時間かかり、平均で 24 時間です。実際の所要時間は、データセット内のファイルタイプの分布によって異なります。
スキャンロジック
タスクタイプ | 初回スキャン | 再スキャン |
デフォルトタスク | 資産内のすべての権限付与済みデータのフルスキャンを実行します。 | 新規または変更されたデータオブジェクトをスキャンします。 スキャンは手動でトリガーするか、自動スキャンサイクルを設定できます。 |
カスタム識別タスク | 指定された識別範囲に従ってデータをスキャンします。 | 指定された範囲内の新規または変更されたデータオブジェクトのみをスキャンします。 |
前回のスキャン以降に変更されていないデータオブジェクトはスキップされます。
スキャン結果
機密度レベルは、タスクのテンプレートで一致した識別ルールによって決定されます。データオブジェクトが複数のルールに一致する場合、最も高い機密度レベルが優先されます。DSC は機密データを S1 から S10 のスケールで分類し、数値が高いほど機密度レベルが高いことを示します。結果が N/A の場合は、機密データが検出されなかったことを示します。
機密度レベルの有効範囲は、関連する識別テンプレートの設定によって異なります。詳細については、「識別テンプレートの機密度レベルを設定する」をご参照ください。
推奨事項
推奨事項 | 説明 |
スキャン範囲と優先順位の確認 | 高リスク資産を優先します。 データ量が多いためにすぐにすべてのデータをスキャンできない場合は、まず資産を評価します。頻繁にアクセス、変更される、または不明な操作の対象となる資産など、リスクプロファイルが高いデータを優先してスキャンします。 |
初回スキャンの範囲の指定 | 対象を絞ったパイロットスキャンを実行します。最初のスキャンを特定のデータベースまたは OSS バケットに限定します。これにより、本格的な展開の前に識別ルールを検証および調整できます。 識別ルールを最適化します。すべての識別機能を無差別に有効にしないでください。一般的なルール (例:日付、時刻、URL) は、大規模なデータセットで過剰な誤検知を生成する可能性があります。ビジネスコンテキストに関連する特定のルールのみを有効にします。 十分なサンプリングを確保します。構造化データの場合、代表的なデータを取得するのに十分なサンプルサイズを確保してください。そうしないと、機密情報が見逃される可能性があります。 |
タスク開始時刻の指定 | データ更新とスケジュールを合わせます。 データ更新の頻度に基づいて、タスクを自動的に (毎日、毎週、または毎月) 実行するように設定します。定期的なスキャンにより、新しい機密データをタイムリーに検出し、セキュリティ体制の傾向や異常を特定するのに役立ちます。パフォーマンスへの影響を最小限に抑えるため、オフピーク時間帯にスキャンをスケジュールすることを推奨します。 |
デフォルト識別タスクの管理
デフォルトタスクの表示
Data Security Center コンソールにログインします。
左側のナビゲーションウィンドウで、 を選択します。
Tasks ページで、Identification Tasks タブをクリックし、次に Default Tasks をクリックします。
Discovery Task Monitoring ページで、デフォルトタスクのリストを表示します。
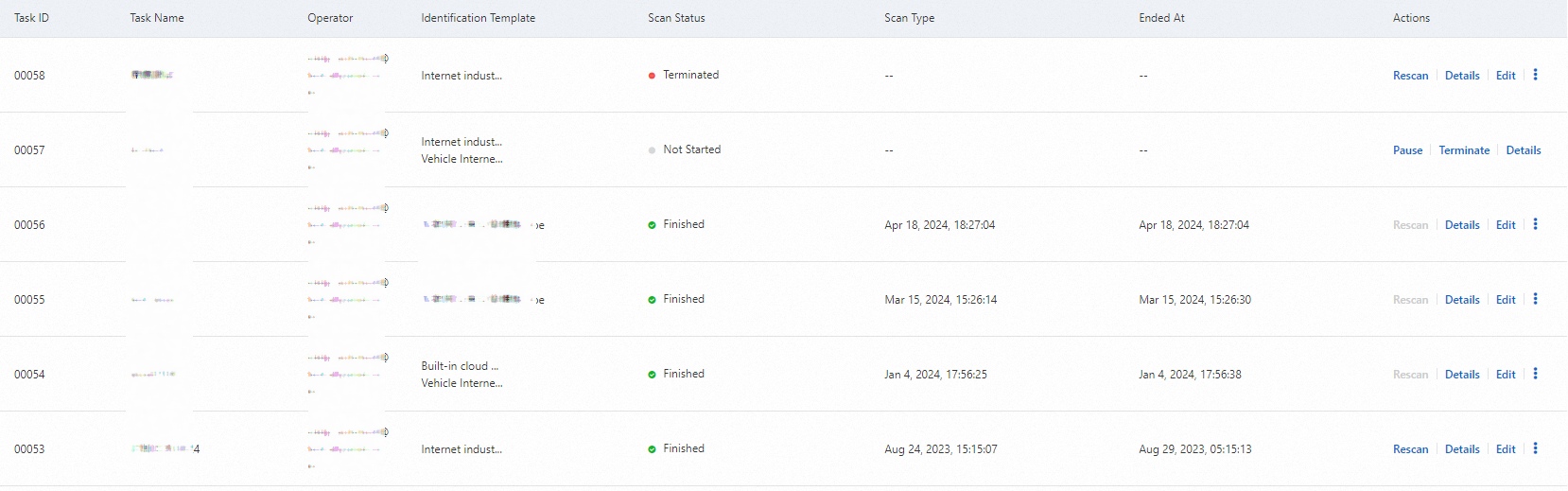
デフォルト識別タスクに対して、以下の操作を実行できます:
Rescan:手動スキャンをすぐにトリガーします。メイン識別テンプレートを更新した場合、識別モデルをアップグレードした場合、または大幅なデータ変更があった場合に使用します。
Pause:実行中のタスクを一時的に停止します (例:データベースのパフォーマンス問題が検出された場合)。
Terminate:将来のデフォルトタスクのスケジュールを無効にします。この操作は、現在進行中のスキャンを中断しません。後続のサイクルでタスクがトリガーされるのを防ぐだけです。
Enable:終了したタスクを再アクティブ化します。
説明デフォルトタスクは削除できません。
スキャン設定の構成
デフォルトタスクのスケジュールをカスタマイズできます。スキャンサイクルをデータ更新頻度 (最小:毎日) に合わせることを推奨します。
Discovery Task Monitoring ページで、スキャンサイクルを設定したいタスクのチェックボックスを選択し、タスクリストの上にある Scan Settings をクリックします。

Scan Settings ダイアログボックスで、スキャンサイクルと自動スキャン開始時刻を設定し、OK をクリックします。
重要データベースへの影響を最小限に抑えるため、開始時刻をオフピーク時間帯に設定してください。
スキャン中の CPU/メモリ使用量を監視してください。異常が発生した場合は、すぐにタスクを一時停止または終了してください。
カスタム識別タスクの作成
特定の (メインではない) 識別テンプレートを使用して特定の資産をスキャンする必要がある場合、または既存の SLS データをスキャンする必要がある場合は、カスタムタスクを作成します。
システムは最大 5 つのアクティブな識別タスク (定期的なスケジュールを持つタスク) をサポートします。この制限に達すると、追加の定期タスクを作成することはできません。
カスタム識別タスクの作成
左側のナビゲーションウィンドウで、 を選択します。
Identification Tasks タブで、識別タスクを作成したい [資産タイプ] を選択し、Create をクリックします。

Create パネルで、パラメーターを設定し、[OK] をクリックします。
カテゴリ
パラメーター
説明
Basic Information
Asset Type
前のステップで選択した資産タイプが表示されます。変更はできません。
Task Name
タスク名を入力します。
Task notes
タスクの備考を入力します。
Task and Plan
タスクの開始時刻を選択します。有効な値:
Immediate Scan:作成後すぐにタスクを実行します。
Periodic Scan:スケジュールされた頻度でタスクを実行します。Scan Frequency と Scan Time (Structured Data Only) を設定する必要があります。スケジュールと同時に即時実行をトリガーするには、Scan Once Now を選択します。
説明[スキャン時間] 設定は構造化データ資産にのみ適用されます。非構造化データのスキャンは、システムリソースの可用性に応じて実行されます。
Identification Template
このスキャンに適用する有効な識別テンプレートを最大 2 つ選択します。テンプレートの有効化の詳細については、「識別テンプレートの使用」をご参照ください。
Identification Scope
Identification Scope of Structured Data
構造化資産 (例:RDS、PolarDB) の範囲を選択します:
Global Scan:すべての権限付与済み構造化資産をスキャンします。
Specify Scan Scope:特定のインスタンスとデータベースを詳細に選択できます。
Instance Name および Database name:複数のインスタンスを追加するには、Add Identification Scope をクリックします。
Scan Limit:テーブルごとにサンプリングされる行数を定義します。デフォルトは最初の 200 行です。最大値は 1,000 行です。
[非構造化データ OSS 識別範囲]
非構造化データ (OSS) の Object、Sampling Method、Scan Depth、および Scan Limit を選択します。
Object の有効な値:
Global Scan:すべての権限付与済み OSS バケットをスキャンします。
Specify Scan Scope:特定のバケットを選択します。フィルター (プレフィックス、ディレクトリ、サフィックス) を適用して、特定のファイルを含めたり除外したりできます。
スキャンするオブジェクトを指定した後、フィルターを設定してきめ細かいスキャンを行うことができます。Prefix、Directory、および Suffix を設定して、特定の値を含めたり除外したりしてスキャン範囲をフィルタリングできます。
Sampling Method:
ListObjectsAPI を使用して OSS からデータを取得し、設定に基づいてデータをスキャンします。Global Scan:すべてのデータをスキャンします。
Specify the sampling ratio:Sampling Rate。サンプリング比率に基づいてデータをスキャンします。
説明たとえば、Sampling Rate を 1/10 に設定すると、システムは 1 番目のファイルをスキャンし、9 つをスキップして 11 番目のファイルをスキャンします。
Scan Depth の有効な値:
Global Scan:完全なディレクトリパスをスキャンします。
Specify Scan Scope:ディレクトリの深度を制限します (レベル 1〜10)。たとえば、「5」は上位 5 階層のディレクトリのみをスキャンします。
Scan Limit:ファイルごとのスキャンサイズを制限します。デフォルト:200 MB。最大:1,000 MB。制限を超えるデータはスキップされます。
[すべての識別結果を SLS に同期]:完全なログを Simple Log Service に送信するには、このオプションを選択します。
[非構造化データ SLS 識別範囲]
[SLS] の Asset Scope と Time Range を設定します。
Asset Scope の有効な値:
Global Scan:すべての権限付与済み SLS プロジェクトをスキャンします。
Specify Scan Scope:特定のプロジェクトと Logstore を選択します。
Time Range の有効な値:
Last 15 Minutes、Last 1 hour、Yesterday、Last 1 Day、Last 7 Days、または Last 30 Days。
Custom:時間範囲の単位は分で、ステップサイズは 5 分です。
[その他の設定]
Tagging Result Overwriting
以前に手動で修正されたデータとの競合をどのように処理するかを決定します:
Skip Manual Tagging Result:手動修正を保持します。システムはそれらを上書きしません。
Overwrite Manual Tagging Result:手動修正を新しいシステムスキャン結果で置き換えます。
カスタム識別タスクの変更または削除
Edit:カスタム識別タスクを再設定します。すべてのパラメーターを変更できます。
 > [削除]:冗長なカスタム識別タスクを削除します。
> [削除]:冗長なカスタム識別タスクを削除します。
タスク操作の管理
タスクの [再スキャン]
識別モデルがアップグレードされたり、データベースのデータが変更されたりした場合、再スキャンを実行して結果をすぐに更新できます。[再スキャン] は、指定された資産の即時フルスキャンをトリガーします。システムパフォーマンスへの影響を最小限に抑えるため、この操作はオフピーク時間帯に実行してください。
[再スキャン] を実行する前に、関連する識別テンプレートが有効になっていることを確認してください。
Scan Type が Immediate Scan に設定されているカスタムタスクでは、[再スキャン] 操作はサポートされていません。
Identification Tasks タブで、再スキャン操作を実行します:
カスタム識別タスクの再スキャン:タスクリストで、カスタム識別タスクの Actions 列にある Rescan をクリックします。
デフォルトタスクの再スキャン:Default Tasks をクリックし、対象の資産を見つけて、Actions 列の Rescan をクリックします。
識別タスクの Scan Status 列でスキャンの進行状況を確認できます。
タスクの [一時停止] または [終了]
Pause:実行中のタスクを一時的に停止します。サービスに異常がある場合に便利です。カスタム識別タスクの Actions 列にある Pause をクリックします。
Terminate:現在および後続の識別タスク (カスタム識別タスクおよびデフォルトタスク) の実行を停止します。
正しい識別結果
DSC がデータを誤って識別 (誤検知) したり、データを見逃したり (検知漏れ) した場合、手動で結果を修正できます。この「手動修正」により、システムはより正確になります。
Tasks ページで、Revision Tasks タブをクリックします。
左側のナビゲーションウィンドウで、管理したい資産タイプをクリックします。
対象の機密データの [操作] 列にある Revision または Resume をクリックします。ページ上の指示に従って Revised Model を変更し、OK をクリックします。
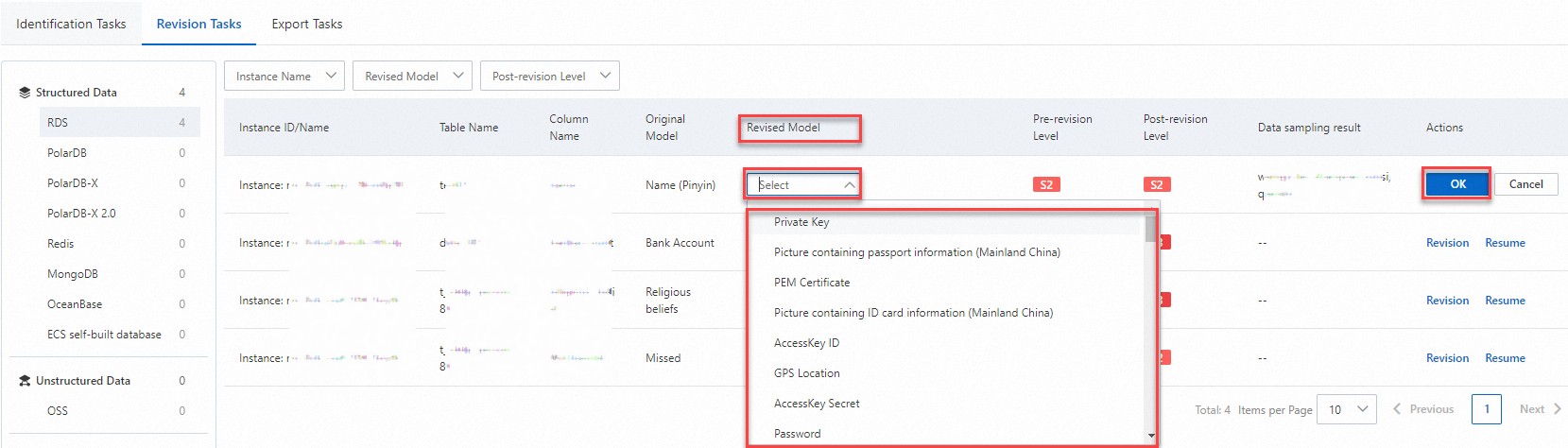
復元操作を実行すると、以前の識別モデルが復元されます。
結果の表示とエクスポート
メイン識別テンプレートによって生成された最新のスキャン結果は、 ページで表示できます。詳細については、「機密データ識別結果の表示」をご参照ください。
検出された機密データ識別結果をダウンロードするためにエクスポートタスクを作成します。対象の識別テンプレートとデータ資産を指定して、レポートを生成およびダウンロードします。
識別タスクが正常に完了した資産とテンプレートの結果のみをエクスポートできます。
エクスポートタスクの作成
以下の手順に従ってエクスポートタスクを作成し、結果をダウンロードします:
Tasks ページで、Export Tasks タブをクリックします。
Export Tasks タブで、Create をクリックします。
エクスポートタスクを設定し、OK をクリックします。
Basic Information セクションで、タスク名を入力し、識別タスクで使用されている識別テンプレートを選択します。
有効な識別テンプレートのみを選択できます。
Export Dimension セクションで、Asset Type または Asset Instance を選択します。
Asset Type:エクスポートしたい資産タイプを選択します。
Asset Instance:エクスポートしたい資産インスタンスを選択します。
エクスポートタスクを作成すると、そのステータスがエクスポートタスクリストに表示されます。データ量が多いほど、エクスポートにかかる時間が長くなります。
エクスポートされた結果のダウンロード
Export Status が Finished になったら、対象のエクスポートタスクの Actions 列にある [ダウンロード] をクリックします。

エクスポートが完了したら、3 日以内にエクスポートされたデータをダウンロードしてください。3 日後、タスクは期限切れとなり、エクスポートされた機密データをダウンロードできなくなります。
関連ドキュメント
識別テンプレートの表示と設定 - 識別タスクで使用される識別テンプレートと、識別できる機密データの種類について説明します。
サポートされているデータ資産タイプ - DSC が機密データを識別できるデータ資産の種類を一覧表示します。
データのスキャンと識別 - 識別タスクに関する一般的な問題とトラブルシューティングガイダンスを提供します。