シャードクラスターインスタンスのコレクションにデータシャーディングを設定して、シャードノードのストレージスペースとコンピューティングパフォーマンスを最大限に活用します。
背景情報
コレクションがシャーディングされていない場合、そのすべてのデータは単一のシャードノードに保存されます。これにより、他のシャードノードがストレージとコンピューティングに完全には活用されなくなります。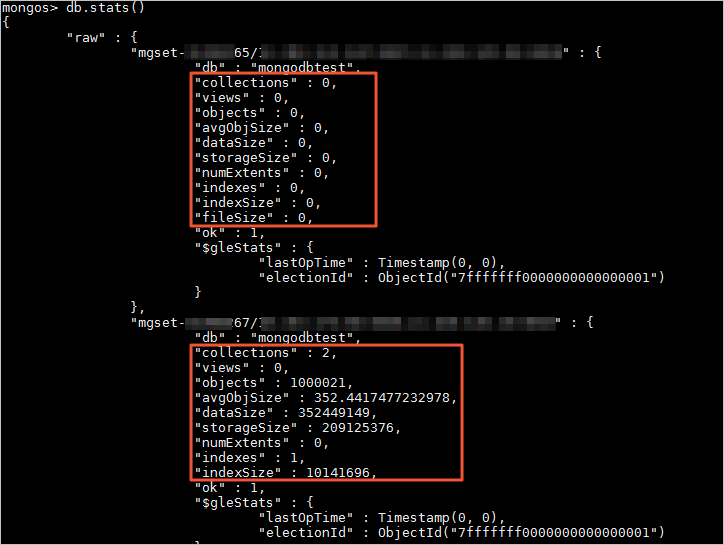
前提条件
インスタンスはシャードクラスターインスタンスです。
使用上の注意
シャードキーを変更する MongoDB の機能は、バージョンごとに改善されています。
バージョン 4.4 より前: シャードキーが設定されると、変更または削除することはできません。
バージョン 4.4 以降: refineCollectionShardKey コマンドを使用して、サフィックスフィールドを追加することでシャードキーを改良できます。
バージョン 5.0 以降: reshardCollection コマンドが導入されました。このコマンドを使用すると、コレクションのシャードキーを完全に変更できます。
データシャーディングを設定すると、バランサーは基準を満たすデータを分割します。この操作はインスタンスのリソースを消費するため、オフピーク時に実行する必要があります。
説明データシャーディングを設定する前に、バランサーのアクティブウィンドウを設定して、バランサーがオフピーク時に実行されるようにすることができます。詳細については、「バランサーのアクティブウィンドウを設定する」をご参照ください。
シャードキーの選択は、シャードクラスターインスタンスのパフォーマンスに影響します。シャードキーの選択方法の詳細については、「シャードキーの選択方法」および「Shard Keys」をご参照ください。
シャーディング戦略
シャーディング戦略 | 説明 | シナリオ |
範囲シャーディング | MongoDB は、シャードキーの値の範囲に基づいてデータをチャンクに分割します。各チャンクには、特定の範囲内のデータが含まれます。
| シャードキーの値は単調に増加または減少しません。シャードキーはカーディナリティが高く、周波数が低いです。範囲クエリが必要です。 |
ハッシュシャーディング | MongoDB は、単一フィールドの値のハッシュを計算してインデックス値として使用します。次に、ハッシュ値の範囲に基づいてデータをチャンクに分割します。
| シャードキーの値は単調に増加または減少します。シャードキーはカーディナリティが高く、周波数が低いです。データ書き込みはランダムに分散される必要があります。データ読み取りは非常にランダムです。 |
これら 2 つのシャーディング戦略に加えて、複合シャードキーを設定することもできます。たとえば、カーディナリティが低く、単調に増加するキーを使用できます。詳細については、「シャードキーの選択方法」をご参照ください。
手順
このトピックでは、`mongodbtest` データベースと `customer` コレクションを例として使用します。
コレクションが存在するデータベースのシャーディングを有効にします。
重要インスタンスが MongoDB 6.0 以降を実行している場合、このステップはスキップできます。詳細については、「sh.enableSharding()」をご参照ください。
sh.enableSharding("<database>")パラメーターの説明:
<database>はデータベースの名前です。例:
sh.enableSharding("mongodbtest")説明sh.status()コマンドを実行して、シャーディングのステータスを表示できます。シャードキーフィールドにインデックスを作成します。
db.<collection>.createIndex(<keyPatterns>,<options>)パラメーターの説明:
<collection>: コレクションの名前。<keyPatterns>: インデックスを作成するフィールドとインデックスタイプ。一般的なインデックスタイプは次のとおりです。
1: 昇順インデックスを作成します。
-1: 降順インデックスを作成します。
"hashed": ハッシュインデックスを作成します。
<options>: オプションのパラメーター。詳細については、「db.collection.createIndex()」をご参照ください。このパラメーターはこの例では使用されません。
次の例は、昇順インデックスを作成する方法を示しています。
db.customer.createIndex({name:1})ハッシュインデックスを作成します:
db.customer.createIndex({name:"hashed"})コレクションのデータシャーディングを設定します。
sh.shardCollection("<database>.<collection>",{ "<key>":<value> } )パラメーターの説明:
<database>: データベースの名前。<collection>: コレクションの名前。<key>: シャードキー。MongoDB はこのキーの値に基づいてデータをシャーディングします。<value>1: 範囲シャーディングを指定します。この戦略は、シャードキーに基づく効率的な範囲クエリをサポートします。
"hashed": ハッシュシャーディングを指定します。この戦略は、書き込みをシャードノード間で均等に分散します。
範囲シャーディングの設定例:
sh.shardCollection("mongodbtest.customer",{"name":1})ハッシュシャーディングの設定例:
sh.shardCollection("mongodbtest.customer",{"name":"hashed"})
次のステップ
インスタンスが実行され、データが一定期間書き込まれた後、mongo シェルで sh.status() コマンドを実行して、シャードノード間のデータ分布を表示できます。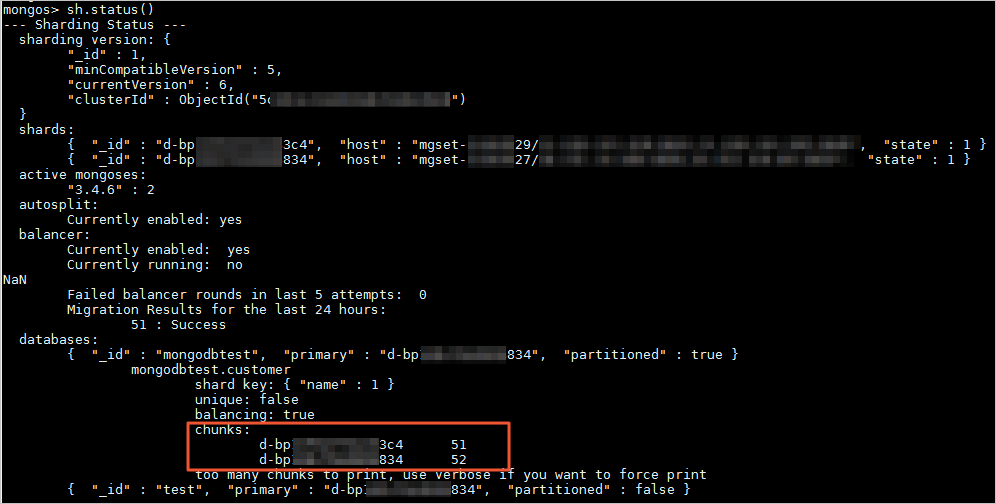
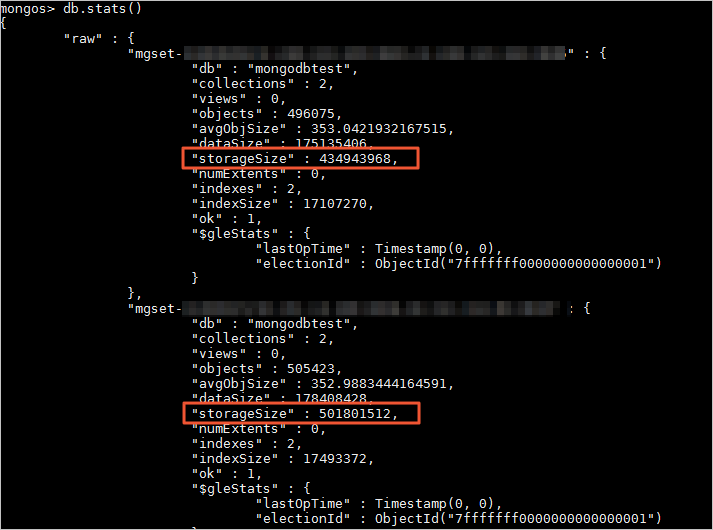
また、db.stats() コマンドを実行して、各シャードノード上のデータベースのデータストレージを表示することもできます。