このガイドでは、DataWorks を使用してデータベースの完全同期と増分同期を行う際の Merge タスクに関する一般的な問題のトラブルシューティングと解決方法について説明します。
Merge タスク
仕組み
データベースの完全同期および増分同期タスクは、まずソーステーブルからベーステーブル (ターゲットテーブル) への既存データのオフライン同期を実行します。同時に、リアルタイム同期タスクが開始され、ソースデータベースから増分変更ログを読み取り、ログテーブルに書き込みます。翌朝 (T+1日)、Merge タスクが開始されます。このタスクは、ログテーブルの T 日のパーティションからの増分データと、ベーステーブルの T-1 日のパーティションからの完全データを組み合わせて、T 日の完全データパーティションを生成します。このプロセスを以下に示します (パーティションテーブルを例として使用):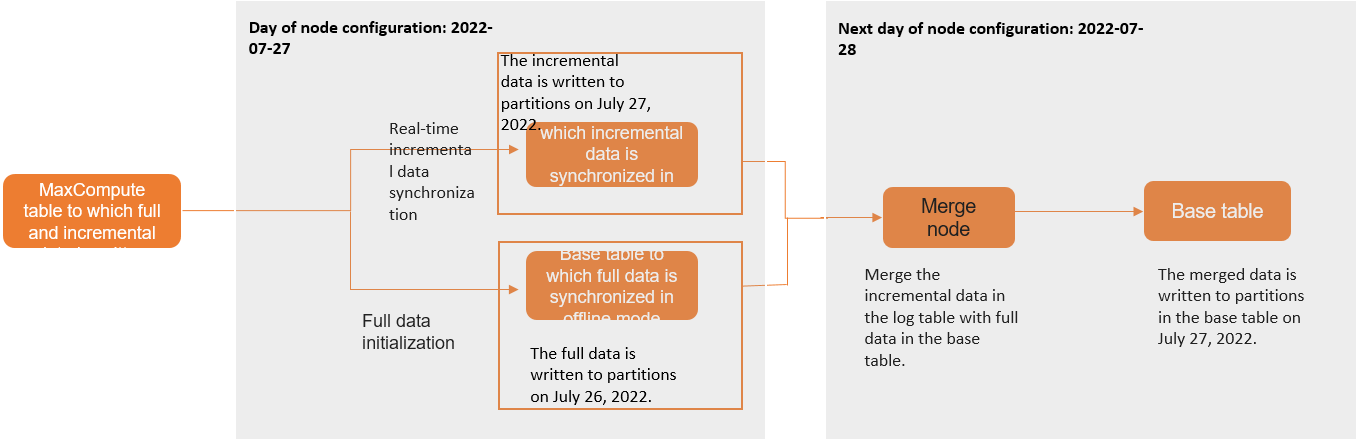
オフラインタスクノード
完全同期および増分同期タスクを設定して実行すると、Data Integration はオペレーションセンターにいくつかのノードを生成します。これらのノードは、 に移動して表示できます。次の図をご参照ください: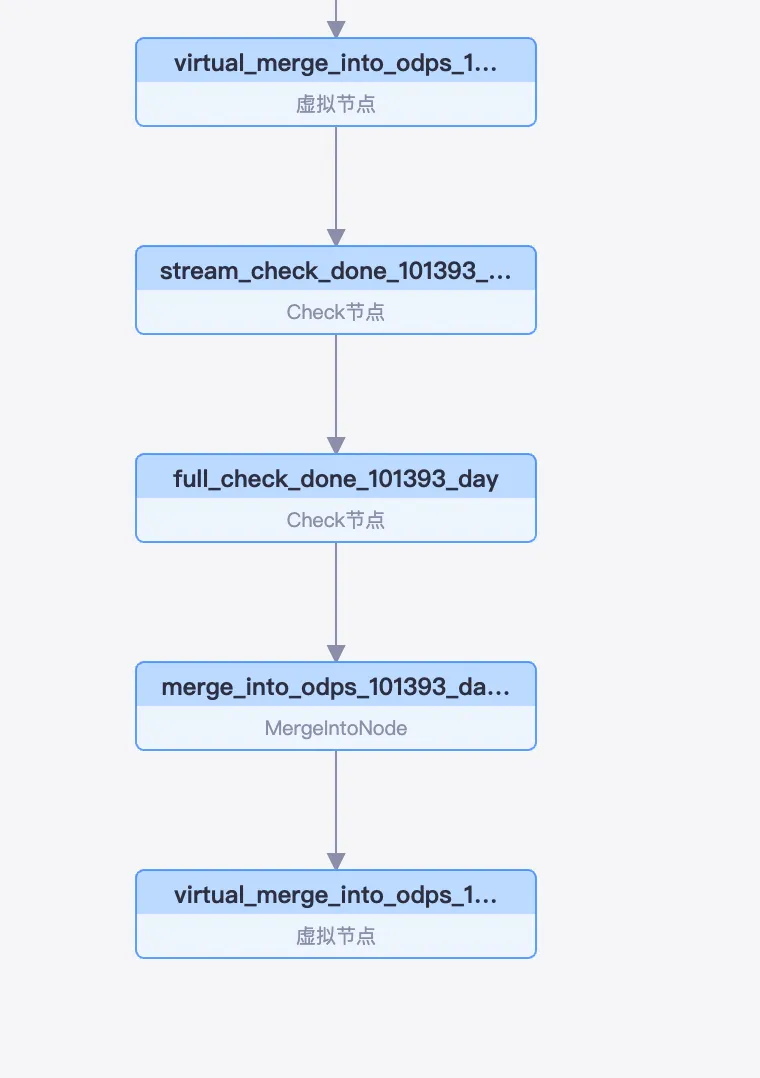
ルート仮想ノード:この同期タスクのすべてのサブタスクは、このノードの下に作成されます。
チェックノード (`stream_check` で始まる):このノードは、増分データの消費チェックポイントをチェックし、前日の増分データパーティションが完全に同期されたことを確認します。後続の Merge タスクは、このチェックが完了した後にのみ開始できます。
チェックノード (`full_check` で始まる):このノードは、完全同期が完了したかどうかをチェックします。ソーステーブルからターゲットの MaxCompute テーブルへの既存データの完全同期は、タスクが最初に実行されたとき、または新しいテーブルが追加されたときに一度だけ実行されます。このチェックにより、次に進む前にソーステーブルのすべての既存データがターゲットパーティションに同期されていることが保証されます。
MergeIntoNode:このノードは、ログテーブルの増分データをベーステーブルの完全データとマージして、新しい完全データパーティションを生成します。
ダウンストリーム仮想ノード:このノードの出力名には同期されたテーブルの名前が含まれており、DataStudio の SQL タスクがこのテーブルを参照する際に、この仮想ノードへの依存関係を自動的に解決できます。
タスクの実行
DataWorks では、 に移動して、各ノードのスケジューリングの依存関係を確認できます。
日次のタスクインスタンスは、`stream_check` ノード、`full_check` ノード、`MergeIntoNode` の順に実行されます。
`MergeIntoNode` は自己依存でスケジュールされます。つまり、各サイクルの実行は、前のサイクルが正常に完了したかどうかに依存します。
この自己依存メカニズムは、データ整合性を確保するために設計されています。具体的には、T 日の Merge タスクは T-1 日の最終データパーティションを処理・生成します。したがって、T 日のタスクが失敗すると、システムは T-1 日のデータパーティションを生成しません。その後、システムは T+1 日のインスタンスをブロックし、データチェーンの破損による計算エラーを防ぎます。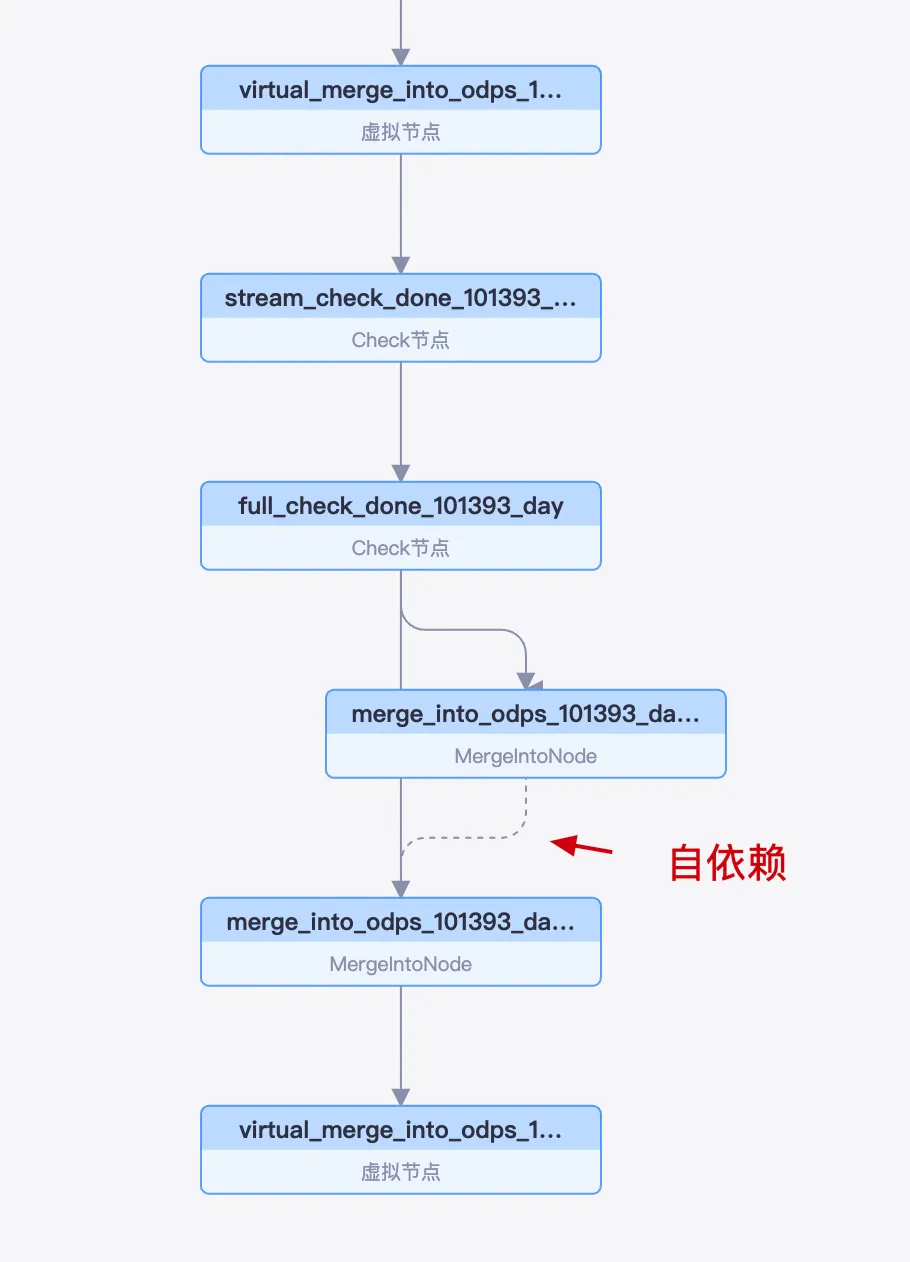
Merge タスクの実行
Merge タスクが実行されると、同期される各テーブルに対して SQL サブタスクが生成されます。このサブタスクは、ログテーブルからテーブルの増分データを読み取り、それをベーステーブルの前日のパーティションの完全データとマージし、前日時点で有効な新しい完全データパーティションを出力します。
Merge タスク内の SQL サブタスクは並行して実行されます。サブタスクが失敗した場合、リトライの条件を満たしていれば自動的にリトライされます。すべてのリトライ後にいずれかのサブタスクが最終的に失敗した場合、Merge ノード全体が失敗します。
Merge タスクの一般的な問題のトラブルシューティング
Merge タスクの失敗
Base table partition not exists.原因: 前日の完全データパーティションが生成されませんでした。これはまれなケースですが、以下のシナリオで発生する可能性があります:
データをバックフィルするために手動で Merge インスタンスを実行したが、前日の Merge インスタンスが実行されていなかった。前日の Merge インスタンスが正常に完了したことを確認してください。
初回のオフライン完全同期、または新しいテーブルを追加した後の完全同期が完了しなかった。この問題を解決するには、失敗したテーブルを一度削除してから再度追加し、再初期化してください。
原因が上記に当てはまらない場合は、サポートされていないシナリオに遭遇した可能性があります。詳細な調査については、担当エンジニアにお問い合わせください。
Run job failed,instance:XXXX.原因: MaxCompute の SQL サブタスクが失敗しました。インスタンス ID を検索してエラーログを特定してください。ログは通常、次のようになります:
Instance: XXX, Status: FAILED result: MaxCompute-0110061: Failed to run ddltask - Persist ddl plans failed. , Logview: http://Logview.MaxCompute.aliyun.com/Logview/?h=http://service.ap-southeast-1.maxcompute.aliyun-inc.com/api&p=sgods&i=20220807101011355goyu43wa&token=NFBwc2tzaEpJNGF0OVFINmJuREZrem1OamQ4PSxPRFBTX09CTzo1OTMwMzI1NTY1MTk1MzAzLDE2NjAxMjYyMTEseyJTdGF0ZW1lbnQiOlt7IkFjdGlvbiI6WyJvZHBzOlJlYWQiXSwiRWZmZWN0IjoiQWxsb3ciLCJSZXNvdXJjZSI6WyJhY3M6b2RwczoqOnByb2plY3RzL3Nnb2RzL2luc3RhbmNlcy8yMDIyMDgwNzEwMTAxMTM1NWdveXU0M3dhIl19XSwiVmVyc2lvbiI6IjEifQ== ]MaxCompute-XXXX のようなエラーメッセージは、MaxCompute の内部エラーを示します。エラーとその解決策については、「SQL エラーコード (MaxCompute-01CCCCX)」ドキュメントをご参照ください。エラーがドキュメントに記載されていない場合や、その他の質問がある場合は、MaxCompute のテクニカルサポートにお問い合わせください。
Request rejected by flow control. You have exceeded the limit for the number of tasks you can run concurrently in this project. Please try later.原因: Merge タスクによってサブミットされた同時 SQL サブタスクの数が、プロジェクトの MaxCompute における同時実行数制限を超えました。
ソリューション: 「Merge タスクによる MaxCompute リソースの枯渇」をご参照ください。
パーティションデータが生成されない
原因:これは、現在のサイクルのインスタンスが失敗したか、まだ実行中の場合に発生します。 に移動し、Merge インスタンスのステータスを確認します:
インスタンスのステータスが「実行中」の場合は、日次の Merge インスタンスが完了するまでお待ちください。
インスタンスのステータスが「失敗」の場合は、Merge タスクの実行ログを確認して失敗の原因を分析します。問題を解決した後、インスタンスを右クリックして [再実行] を選択します。
インスタンスのステータスが「未実行」の場合:
上流の `stream_check` ノードが完了したかどうかを確認します。まだ実行中の場合は、リアルタイム同期タスクに遅延が発生しているかどうかを確認します。遅延がある場合は、まずそれを解決してください。遅延が解決されると、Merge タスクがトリガーされます。ログの内容で、次の例のようなメッセージを確認してください:
2023-01-06 00:15:04,692 INFO [DwcheckStreamXDoneNode.java:168] - Data current point time: 1672921729000 2023-01-06 00:15:04,692 WARN [DwcheckStreamXDoneNode.java:183] - Retrying... 2023-01-06 00:20:04,873 INFO [DwcheckStreamXDoneNode.java:168] - Data current point time: 1672921729000 2023-01-06 00:20:04,873 WARN [DwcheckStreamXDoneNode.java:183] - Retrying...このインスタンスが依存する上流の Merge インスタンスが完了していないか、失敗しています。オペレーションセンターで、当日の Merge インスタンスの上流依存関係を確認し、完了していないか失敗している最新のインスタンスを見つけます:
上流の Merge インスタンスが失敗した場合:実行ログを分析して原因を特定します。問題を解決した後、インスタンスを右クリックして [再実行] を選択し、通常のスケジューリングをトリガーします。
上流の Merge インスタンスが「未実行」状態の場合:その上流の `stream_check` インスタンスを確認し、それが完了しており、リアルタイム同期タスクに遅延がないことを確認します。
これは、以前のワークフローの問題の後にデータベースの完全同期タスクを再実行した場合に発生します。ただし、Merge ノードインスタンスには自己依存があるため、新しい Merge インスタンスは実行できません。ワークフローが再実行された後に生成された最初の Merge インスタンスを見つけ、それを右クリックして [依存関係の削除] を選択します。これにより、上流の Merge ノードへの依存関係が解除され、新しい Merge インスタンスが実行できるようになります。
Merge タスクの実行が遅い、または長時間実行される
オペレーションセンターで、タスクの実行ログを表示して、現在実行中の SQL タスクを確認します。ログには次のようなエントリが含まれます:
2022-08-07 18:10:58,919 INFO [LogUtils.java:20] - Wait instance 20220807101058817gbb6ghx5 to finish...
2022-08-07 18:10:58,938 INFO [LogUtils.java:20] - Wait instance 20220807101058818g46v43wa to finish...ログ内のインスタンス ID を検索して、SQL タスクの Logview へのリンクを見つけます (例:instance20220807101058817gbb6ghx5: Logview Portal)。Logview を開いて、SQL タスクの実行ステータスを確認します。SQL の実行が遅い原因は多数考えられます:
ベーステーブルのデータ量が膨大で、起動されるマッパーとリデューサーが多すぎることが原因です。これは、プロジェクトレベルで対応する MaxCompute パラメーターを調整することで解決できます。
一度に多くの SQL タスクがサブミットされ、リソース不足が発生しました。Logview を開くと、SQL インスタンスが「待機中」状態になっていることがあります。これを解決するには、MaxCompute のリソース割り当てを最適化する必要があります。必要に応じて、MaxCompute チームの担当エンジニアにサポートを依頼してください。
上記のログが見つからない場合は、MaxCompute SQL タスクのサブミットに問題がある可能性があります。最後に成功した MaxCompute タスクの Logview を見つけてそのログを確認するか、MaxCompute チームの担当エンジニアに Logview の分析を依頼してください。
Merge タスクによる MaxCompute リソースの枯渇
リソース消費を制御したり、タスクのパフォーマンスを最適化したりするために、次の手順で Merge タスクの同時実行数を調整できます:
タスク編集ページに移動し、右側のパネルで [詳細設定] を展開します。
[実行設定] で、[Merge タスクの同時実行数] パラメーターを見つけ、要件に基づいてその値を変更します。
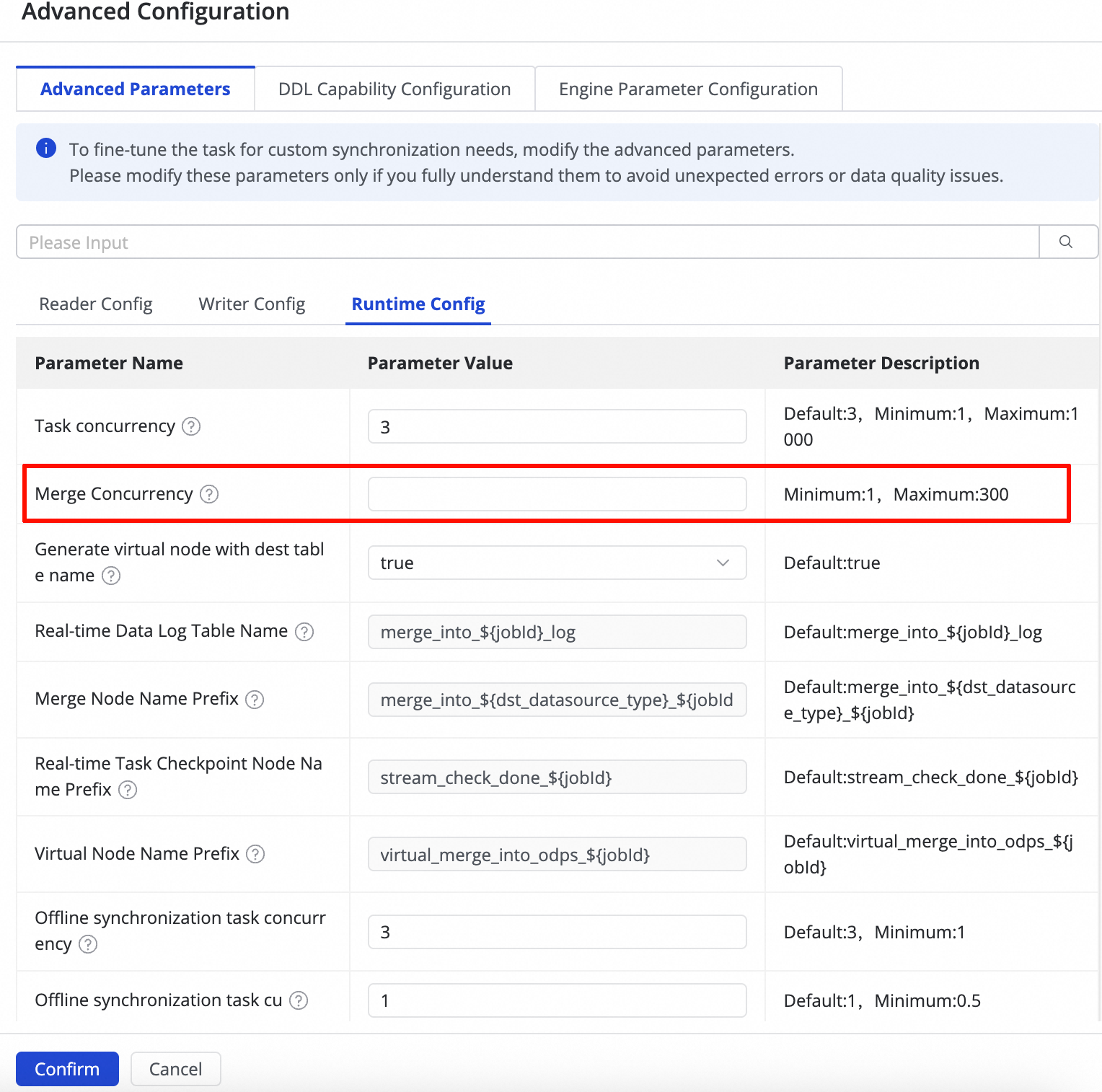
パラメーターの説明:
デフォルト値:
300推奨事項:リソース不足でタスクが失敗する場合や、全体的なリソース消費を削減する場合は、この値を下げてください。
有効化:変更はタスクの再起動後に適用されます。
Merge タスクのスケジュール時間を変更して、オフピーク時間に実行します。