Alibaba Cloud EMR Serverless Spark のノートブックは DuckDB を統合しており、クラウドデータソースとの連携を強化しています。これにより、OSS および OSS-HDFS へのパスワードレスアクセスが可能になり、さまざまなデータファイル形式を効率的に操作できます。また、Data Lake Formation (DLF) のメタデータテーブルに対して SQL を使用して直接クエリを実行できるため、データレイクの探索と分析のプロセスを合理化および軽量化できます。
背景情報
DuckDB は、オンライン分析処理 (OLAP) シナリオに最適化された、軽量でパフォーマンス専有型の組み込み分析データベースエンジンです。
特徴
組み込みアーキテクチャ: SQLite と同様に、別のサーバーを必要とせず、ライブラリとしてアプリケーションに直接埋め込みます。インメモリモードとオンディスクモードの両方をサポートしています。
カラムナストレージ: データを列ごとに保存して、集計クエリとスキャンのパフォーマンスを最適化します。
ベクトル化実行: SIMD 命令を使用してデータバッチを並列処理し、CPU オーバーヘッドを削減します。
標準の互換性: 共通テーブル式 (CTE)、ウィンドウ関数、JOIN (ASOF JOIN を含む)、およびサブクエリを含む、SQL-92 および SQL:2011 標準をサポートします。
複数フォーマットの直接読み取り: CSV、Parquet、JSON ファイルをインポートせずに直接クエリします。
ゼロコピー統合: Pandas や Arrow などのインメモリデータ構造とシームレスに統合し、データ移行のオーバーヘッドを回避します。
フェデレーションクエリ:
httpfs拡張機能を使用して、S3 上のファイルなどのリモートファイルにアクセスしたり、PostgreSQL などの外部データベースに接続してフェデレーションクエリを実行したりします。
シナリオ
対話型分析: ギガバイトからテラバイトまでのデータセットを処理します。ビッグデータを扱う際に、Pandas や Excel の代替として使用できます。
エッジコンピューティング: エッジデバイスにデプロイして、ローカルデータ分析を行うことができます。
データサイエンス: Python および R エコシステムとシームレスに統合し、機械学習 (ML) の前処理エンジンとして機能します。
リアルタイム OLAP: 頻繁な更新と複雑なクエリの両方を必要とする分析ニーズをサポートします。
制限事項
バージョン要件:
esr-4.x: esr-4.7.0 以降。
esr-3.x: esr-3.6.0 以降。
DuckDB を使用して Paimon テーブルを読み取る場合、次の制限が適用されます:
操作: Paimon の追加専用テーブルの読み取りのみ可能です。プライマリキーテーブルの読み取りやデータの書き込みはサポートされていません。
テーブルフォーマット:
file.format = 'parquet'の Paimon テーブルのみがサポートされています。
手順
EMR Serverless Spark のページで、左側のナビゲーションウィンドウにある Data Development をクリックします。
Notebook を作成します。
Development タブで、
 アイコンをクリックします。
アイコンをクリックします。表示されるダイアログボックスで名前を入力し、[タイプ] を に設定してから、OK をクリックします。
右上隅で、作成および開始された Notebook セッションインスタンスを選択します。
ドロップダウンリストから [Notebook セッションの作成] を選択して、新しい Notebook セッションインスタンスを作成することもできます。詳細については、「Notebook セッションを管理する」をご参照ください。
説明DuckDB は単一ノードの SQL エンジンであり、Notebook Spark ドライバーのリソースのみを使用します。したがって、Spark ドライバーの
spark.driver.coresおよびspark.driver.memoryパラメーターのリソース構成を増やす必要がある場合があります。Notebook の Python コードで DuckDB を使用するには、
import duckdbを実行します。次の例は、一般的な使用例を示しています。ファイルの読み取り
Parquet、CSV、および JSON ファイルの内容を表示します。
import duckdb # Parquet ファイルの内容を表示 duckdb.sql("SELECT * FROM 'oss://bucket/path/to/test.parquet'") # CSV ファイルの内容を表示 duckdb.sql("SELECT * FROM 'oss://bucket/path/to/test.csv'") # JSON ファイルの内容を表示 duckdb.sql("SELECT * FROM 'oss://bucket/path/to/test.json'")
Parquet ファイルのスキーマを表示します。
import duckdb # Parquet ファイルのスキーマを表示 duckdb.sql("SELECT * FROM parquet_schema('oss://bucket/path/to/test.parquet')")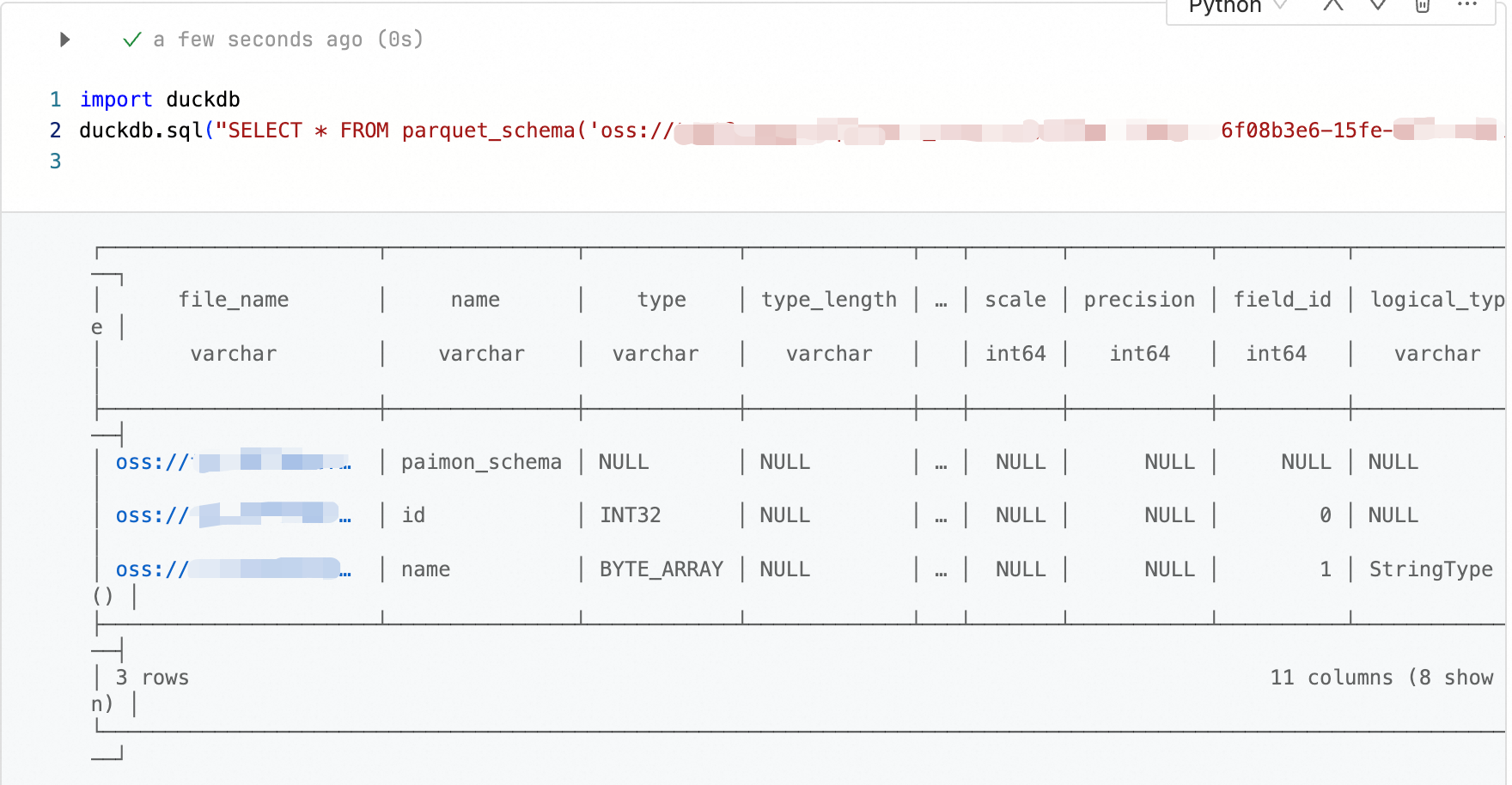
Parquet ファイルの内容を CSV ファイルにエクスポートします。
import duckdb # Parquet ファイルの内容を CSV ファイルにエクスポート duckdb.sql("COPY (SELECT * FROM 'oss://bucket/path/to/test.parquet') TO 'oss://bucket/path/to/output.csv' (HEADER, DELIMITER ',');")
説明OSS ファイルの読み取りまたは書き込みを行う前に、OSS をアクティブ化し、バケットを作成し、バケットに必要なアクセス権限があることを確認する必要があります。
DLF カタログへのアクセス
説明データ共有によって作成された DLF カタログはサポートされていません。
現在のワークスペースにマウントされている DLF カタログを表示します。DLF データカタログの詳細については、「データカタログの管理」をご参照ください。
import duckdb duckdb.sql("show databases")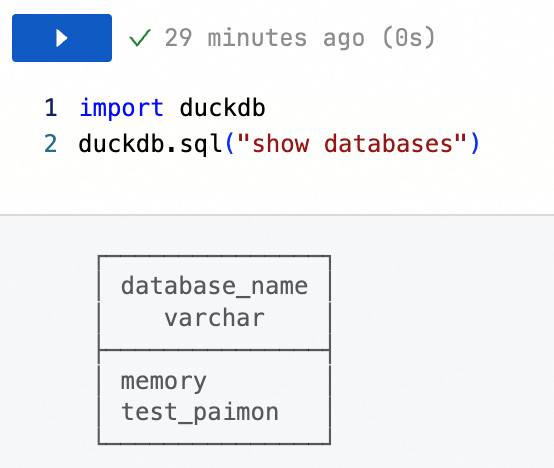
DLF カタログ内のテーブルデータをクエリします。
import duckdb duckdb.sql("use <catalogName>.<databaseName>") duckdb.sql("select * from <tableName> limit 10")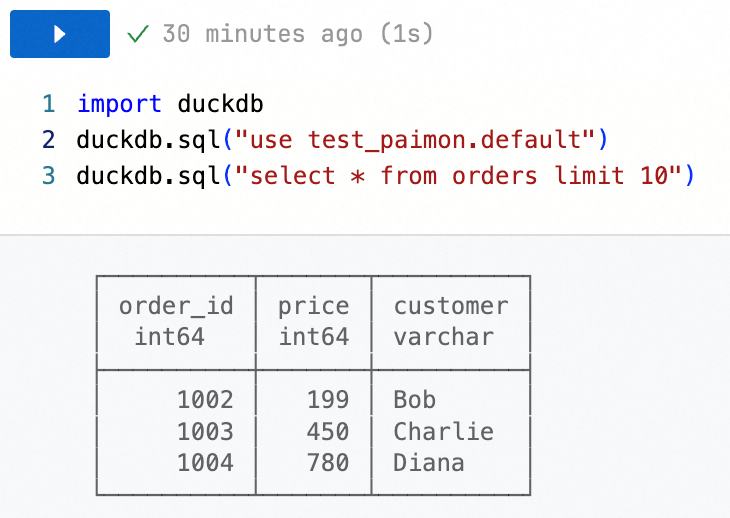
詳細については、公式の「DuckDB ドキュメント」をご参照ください。