概要
TCPヘルスチェックは、GTMがターゲットアドレスのヘルスチェックを実行するために使用するネットワークプロトコルです。主に、ネットワークの到達可能性、ポートの可用性、 IP アドレスのレイテンシなどのメトリックを監視します。 IP アドレスまたはポートが異常になると、システムは自動的に異常な IP アドレスをブロックします。 IP アドレスが正常に戻ると、システムは自動的にブロックを解除します。
構成方法
Cloud DNS - Global Traffic Manager にログオンします。
Global Traffic Manager のインスタンスリストページで、ターゲットインスタンスの [操作] 列をクリックし、[構成] ボタンをクリックします。
[基本構成] ページで、[アドレスプール構成] タブをクリックし、アドレスプールの前の「+」アイコンをクリックして、[ヘルスチェック] の横にある [追加] をクリックします。
[ヘルスチェックの変更] ダイアログボックスで、[ヘルスチェックプロトコル]、[ヘルスチェック間隔]、[ヘルスチェックポート]、[タイムアウト]、[連続エラー回数]、[エラー率]、[監視ノード] の構成を完了し、[確認] をクリックします。
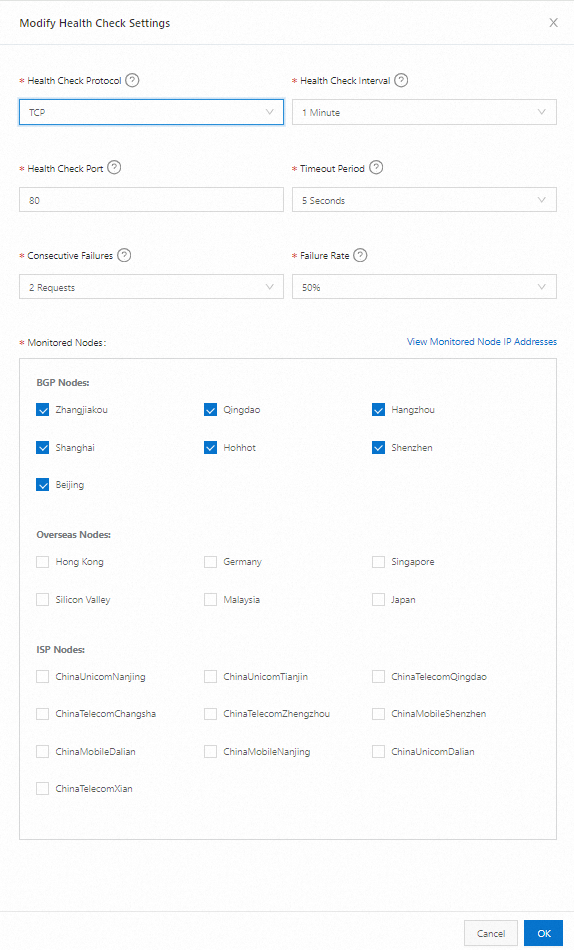
パラメータ
ヘルスチェックプロトコル
[TCP] を選択して、TCPプロトコルを使用してターゲット IP アドレスを監視します。これは主に、ネットワークの到達可能性、ポートの可用性、 IP アドレスのレイテンシなどのメトリックを監視します。
ヘルスチェック間隔
各TCP監視の時間間隔を選択します。デフォルトでは、1分ごとにチェックが実行されます。サポートされている最小ヘルスチェック間隔は 15 秒です(Ultimate Edition ユーザーが利用可能)。
ヘルスチェックポート
ターゲット IP アドレスのこのポートでTelnetを実行できるかどうかを確認します。ポートでTelnetが成功した場合、サービスは正常と見なされます。ポートでTelnetが失敗した場合、サービスは異常と見なされます。
タイムアウト
TCPヘルスチェックごとに、システムは送信されたTCPパケットの戻り時間を計算します。パケットがタイムアウト期間内に返されない場合、ヘルスチェックはタイムアウトしたと見なされます。使用可能なタイムアウト値は、2秒、3秒、5秒、10秒です。
連続エラー回数
TCPヘルスチェックを実行する場合、システムは複数回の連続した異常検出後にのみアプリケーションサービスが異常であると判断します。これは、瞬間的なネットワークジッターなどの要因による監視精度の影響を防ぎます。連続エラー回数の使用可能な値は、1回、2回、3回です。
1回:ヘルスチェックで1つのアラームが検出されると、アプリケーションサービスは異常と判断されます。
2回:ヘルスチェックで2つの連続したアラームが検出されると、アプリケーションサービスは異常と判断されます。
3回:ヘルスチェックで3つの連続したアラームが検出されると、アプリケーションサービスは異常と判断されます。
エラー率
TCPヘルスチェックを実行する場合、これは異常な監視ポイントの総監視ポイント数に対する比率です。エラー率が設定されたしきい値を超えると、アプリケーションサービスは異常と判断されます。使用可能なエラー率のしきい値は、20%、50%、80%、100%です。
監視ノード
TCPヘルスチェックを実行するノードの地理的な場所。システムが提供するデフォルトの監視ノードは次のとおりです。
ノードタイプ | 地理的な場所 |
BGPノード | 張家口、青島、杭州、上海、フフホト、深セン、北京 |
国際ノード | 中国(香港)、ドイツ、シンガポール、カリフォルニア、マレーシア、日本 |
キャリアノード | 武漢チャイナユニコム、大連チャイナユニコム、南京チャイナユニコム、天津チャイナユニコム、青島チャイナテレコム、長沙チャイナテレコム、西安チャイナテレコム、鄭州チャイナテレコム、深センチャイナモバイル、大連チャイナモバイル、南京チャイナモバイル |
アドレスプール内のすべてのアドレスがAlibaba Cloudアドレスであり、障害テストにブラックホールフィルタリングポリシーを使用する場合は、監視ノードとしてキャリアノードを選択してください。(理由:ブラックホールフィルタリングは、Alibaba Cloudネットワークとキャリアネットワーク間のインターネットで有効になる ACL ポリシーですが、Alibaba Cloud IP 間のトラフィックはほとんどクラウドネットワーク内で流れ、検出効率が低下します。)