このトピックでは、Wan2.1 モデルの特徴と主要な指標、エッジクラウドへのモデルデプロイのベストプラクティス、およびテスト環境のセットアップ方法について説明します。 これにより、モデルの機能、デプロイ要件、およびパフォーマンス最適化手法をすばやく理解し、さまざまなシナリオでのビデオ生成要件を満たすために、エッジクラウドでモデルを効率的にデプロイおよび使用できます。
Wan2.1 モデルの概要
Wan2.1 モデルは、Alibaba Cloud によって開発されたオープンソースのビデオ生成モデルです。 Wan2.1 モデルは、複雑な動きの処理、実際の物理法則の復元、映画品質の向上、および命令コンプライアンスの最適化において大きな利点があります。 クリエイター、開発者、または企業ユーザーのいずれであっても、ビジネス要件に基づいて適切なモデルと機能を見つけて、高品質のビデオ生成を実現できます。 また、Wan2.1 モデルは、業界をリードする中国語と英語のテキスト効果生成をサポートしており、広告、ショートビデオなどの分野での創造的なニーズを満たします。 VBench 権威ある評価システムによると、Wan2.1 モデルは合計スコア 86.22% で 1 位にランクされ、Sora、Minimax、Luma、Gen3、Pika などの国内および国際的なビデオ生成モデルを大幅に上回っています。
Wan2.1-T2V-14B: 非常に高いビデオ品質要件を持つシナリオに対応する、業界をリードするパフォーマンスを提供する高性能プロフェッショナル版。
Wan2.1-T2V-1.3B: 低い GPU メモリ要件で 480P ビデオを生成できます。
Wan2.1 モデルをデプロイするための推奨構成と推論パフォーマンス
エッジクラウドは、さまざまなシナリオの異種コンピューティング能力要件を満たすために、広く分散されたノード上で複数仕様の差別化された異種コンピューティングリソースを提供します。 GPU のメモリは 12 GB から 48 GB の範囲です。 エッジクラウドに Wan2.1-T2V-1.3B モデルをデプロイして推論する場合、推奨構成と推論パフォーマンスは次のとおりです。
BFloat16 精度で Wan2.1-T2V-1.3B を使用して 480P ビデオを生成するには、それぞれ 12 GB のメモリを搭載した 5 つの GPU を含むインスタンスを使用することをお勧めします。
それぞれ 12 GB のメモリを搭載した 5 つの GPU を含むインスタンスの場合、シングルパスモードで単一の GPU で実行すると、最高の費用対効果を実現できます。 単一の GPU 操作ではビデオ生成に時間がかかりますが、マルチパス推論タスクを同時に処理できます。 これにより、単位時間あたりのリターンが向上します。
ビデオ生成効率を優先する場合は、それぞれ 48 GB のメモリを搭載した 2 つの GPU を含むインスタンスを使用できます。 これにより、コストが 35% しか増加しない一方で、シングルパスビデオ生成時間が約 85% 短縮されます。
インスタンスタイプ
推論方法
ビデオの長さ (秒)
生成時間 (秒)
GPU メモリ使用量 (GB)
シングルパスコスト
それぞれ 12 GB のメモリを搭載した 5 GPU ベアメタルインスタンス
単一 GPU シングルパス
5
1459
9.6
100%
4 GPU シングルパス
5
865
35.3
296%
それぞれ 48 GB のメモリを搭載した単一 GPU インスタンス
単一 GPU シングルパス
5
456
18.6
144%
それぞれ 48 GB のメモリを搭載したデュアル GPU インスタンス
デュアル GPU シングルパス
5
214
20.9
135%
BFloat16 精度で Wan2.1-T2V-14B を使用して 720P ビデオを生成するには、それぞれ 48 GB のメモリを搭載した 2 つの GPU を含むインスタンスを使用することをお勧めします。
720P はより高品質なビデオ体験を提供しますが、ビデオ生成時間は長くなります。 ビジネスシナリオの要件とサンプルビデオの品質に基づいて、適切なリソースを選択できます。
インスタンスタイプ
推論方法
ビデオの長さ (秒)
生成時間 (秒)
GPU メモリ使用量 (GB)
それぞれ 48 GB のメモリを搭載したデュアル GPU インスタンス
デュアル GPU シングルパス
5
3503
41
次の表に、上記のインスタンスタイプの構成を示します。
環境パラメーター
それぞれ 12 GB のメモリを搭載した 5 GPU ベアメタルインスタンス
それぞれ 48 GB のメモリを搭載した単一 GPU インスタンス
それぞれ 48 GB のメモリを搭載したデュアル GPU インスタンス
CPU
2 つの 24 コア CPU、3.0 ~ 4.0 GHz
48 コア
96 コア
メモリ
256 GB
192 GB
384 GB
GPU
それぞれ 12 GB のメモリを搭載した 5 つの NVIDIA GPU
それぞれ 48 GB のメモリを搭載した 1 つの NVIDIA GPU
それぞれ 48 GB のメモリを搭載した 2 つの NVIDIA GPU
オペレーティングシステム
Ubuntu 20.04
GPU ドライバー
ドライバーバージョン: 570.124.06
CUDA バージョン: 12.4
ドライバーバージョン: 550.54.14
CUDA バージョン: 12.4
ドライバーバージョン: 550.54.14
CUDA バージョン: 12.4
推論フレームワーク
PyTorch
テスト環境をセットアップする
インスタンスを作成し、初期化を実行する
ENS コンソールでインスタンスを作成する
ENS コンソールにログインします。
左側のナビゲーションウィンドウで、 を選択します。
[インスタンス] ページで、[インスタンスの作成] をクリックします。 ENS インスタンスパラメーターの構成方法については、インスタンスを作成するをご参照ください。
ビジネス要件に基づいてパラメーターを構成できます。 次の表に、推奨構成を示します。
ステップ
パラメーター
推奨値
基本構成
請求方法
サブスクリプション
インスタンスタイプ
x86 コンピューティング
インスタンス仕様
NVIDIA 48GB * 2
詳細な仕様については、カスタマー マネージャーにお問い合わせください。
イメージ
Ubuntu
ubuntu_22_04_x64_20G_alibase_20240926
ネットワークとストレージ
ネットワーク
セルフビルドネットワーク
システムディスク
ウルトラディスク、80 GB 以上
データディスク
ウルトラディスク、1 TB 以上
システム設定
パスワードの設定
カスタムキーまたはキーペア
注文を確認します。
システム設定が完了したら、右下隅にある [注文の確認] をクリックします。 システムは構成に基づいてインスタンスを構成し、価格を表示します。 支払いが完了すると、ページは ENS コンソールにジャンプします。
作成されたインスタンスは、ENS コンソールで表示できます。 インスタンスが 実行中 状態の場合は、インスタンスを使用できます。
操作を呼び出してインスタンスを作成する
OpenAPI ポータル で操作を呼び出してインスタンスを作成することもできます。
次のセクションでは、操作パラメーターの参照コードについて説明します。
{
"InstanceType": "ens.gnxxxx", <インスタンスタイプ>
"InstanceChargeType": "PrePaid",
"ImageId": "ubuntu_22_04_x64_20G_alibase_20240926",
"ScheduleAreaLevel": "Region",
"EnsRegionId": "cn-your—ens-region", <エッジノード>
"Password": <YOURPASSWORD>, <パスワード>
"InternetChargeType": "95BandwidthByMonth",
"SystemDisk": {
"Size": 80,
"Category": "cloud_efficiency"
},
"DataDisk": [
{
"Category": "cloud_efficiency",
"Size": 1024
}
],
"InternetMaxBandwidthOut": 5000,
"Amount": 1,
"NetWorkId": "n-xxxxxxxxxxxxxxx",
"VSwitchId": "vsw-xxxxxxxxxxxxxxx",
"InstanceName": "test",
"HostName": "test",
"PublicIpIdentification": true,
"InstanceChargeStrategy": "instance", <インスタンスに基づく請求>
}インスタンスにログインしてディスクを初期化する
インスタンスにログインする
インスタンスへのログイン方法については、インスタンスに接続するをご参照ください。
ディスクを初期化する
ルートディレクトリを展開します。
インスタンスを作成またはサイズ変更した後、インスタンスを再起動せずにルートパーティションをオンラインで展開する必要があります。
# クラウド環境ツールキットをインストールします。 sudo apt-get update sudo apt-get install -y cloud-guest-utils # GPT パーティションツール sgdisk が存在することを確認します。 type sgdisk || sudo apt-get install -y gdisk # 物理パーティションを展開します。 sudo LC_ALL=en_US.UTF-8 growpart /dev/vda 3 # ファイルシステムのサイズを変更します。 sudo resize2fs /dev/vda3 # サイズ変更結果を確認します。 df -h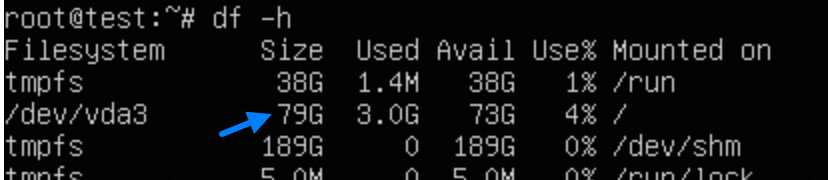
データディスクをマウントします。
データディスクをフォーマットしてマウントする必要があります。 次のセクションでは、サンプルコマンドを示します。 ビジネス要件に基づいてコマンドを実行します。
# 新しいディスクを識別します。 lsblk # ディスクをパーティション分割せずにフォーマットします。 sudo mkfs -t ext4 /dev/vdb # マウントを構成します。 sudo mkdir /data echo "UUID=$(sudo blkid -s UUID -o value /dev/vdb) /data ext4 defaults,nofail 0 0" | sudo tee -a /etc/fstab # マウントを確認します。 sudo mount -a df -hT /data # 権限を変更します。 sudo chown $USER:$USER $MOUNT_DIR 説明
説明インスタンスに基づいてイメージを作成する場合は、
/etc/fstabファイルからext4 defaults 0 0行を削除する必要があります。 そうしないと、イメージに基づいて作成されたインスタンスを起動できません。
依存関係をインストールする
CUDA のインストール方法については、CUDA Toolkit 12.4 ダウンロード | NVIDIA 開発者 をご参照ください。
wget https://developer.download.nvidia.com/compute/cuda/12.4.0/local_installers/cuda_12.4.0_550.54.14_linux.run
chmod +x cuda_12.4.0_550.54.14_linux.run
# このステップには時間がかかります。 グラフィカルなインタラクションが表示されます。
sudo sh cuda_12.4.0_550.54.14_linux.run
# 環境変数を追加します。
vim ~/.bashrc
export PATH="$PATH:/usr/local/cuda-12.4/bin"
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda-12.4/lib64"
source ~/.bashrc
# 操作が成功したかどうかを確認します。
nvcc -V
nvidia-smi(オプション) ツールをインストールする
uv は、Python 仮想環境と依存関係の管理ツールであり、複数のモデルを実行する必要があるインスタンスに適しています。 詳細については、インストール | uv (astral.sh) をご参照ください。
# uv をインストールします。 デフォルトでは、uv は ~/.local/bin/ にインストールされます。
curl -LsSf https://astral.sh/uv/install.sh | sh
# ~/.bashrc を編集します。
export PATH="$PATH:~/.local/bin"
source ~/.bashrc
# diff という名前の venv 環境を作成します。
uv venv diff --python 3.12 --seed
source diff/bin/activateuv をインストールした後に構成した CUDA 環境変数が無効になり、nvcc\nvidia-smi が見つからない場合は、次の操作を実行します。
vim myenv/bin/activate
# export PATH の最後に次のコンテンツを追加します。
export PATH="$PATH:/usr/local/cuda-12.4/bin"
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda-12.4/lib64"
(オプション) GPU モニタリングツールのインストール
# 以下の GPU モニタリングツールをインストールします。nvidia-smi を使用することもできます。
pip install nvitop推論フレームワークとモデルをダウンロードする
ModelScope によって開始された DiffSynth Studio モデル フレームワークを使用することをお勧めします。これにより、パフォーマンスと安定性が向上します。詳細については、「https://github.com/modelscope/DiffSynth-Studio/tree/main」をご参照ください。
# ModelScope ダウンロードツールのインストール
pip install modelscope
# DiffSynth Studio と依存関係のダウンロード
cd /root
git clone https://github.com/modelscope/DiffSynth-Studio.git
cd DiffSynth-Studio
pip install -e .
# xfuser のインストール
pip install xfuser>=0.4.3
# Wan2.1-T2V-14B モデルファイルを DiffSynth Studio の対応するディレクトリにダウンロードします。
modelscope download --model Wan-AI/Wan2.1-T2V-14B --local_dir /root/DiffSynth-Studio/models/Wan-AI/Wan2.1-T2V-14Bテストビデオの生成
DiffSynth Studio は、Unified Sequence Parallel(USP)と Tensor Parallel という 2 つの並列メソッドを提供します。この例では、Tensor Parallel を使用します。テストスクリプトを使用して、Wan2.1-T2V-14B に基づいて 720P ビデオを生成します。
(オプション)テストスクリプトの最適化
テストスクリプト examples/wanvideo/wan_14b_text_to_video_tensor_parallel.py 内のいくつかのコードとパラメーターを変更することで、次の効果を実現できます。
コードリポジトリは継続的に最適化されているため、コードファイルはいつでも更新される可能性があります。以下の変更は参考用です。
実行するたびにモデルを再度ダウンロードすることを回避します。
ビデオの圧縮品質を変更します。ビデオファイルが大きいほど、鮮明度が高くなります。
生成されるビデオを 480P(デフォルト)から 720P に変更します。
# テストコードファイルを修正します。 vim /root/DiffSynth-Studio/examples/wanvideo/wan_14b_text_to_video_tensor_parallel.py # 1. 約 125 行目のコードをコメントアウトして、実行するたびにモデルを再度ダウンロードすることを回避し、以前にダウンロードしたモデルを使用します。 # snapshot_download("Wan-AI/Wan2.1-T2V-14B", local_dir="models/Wan-AI/Wan2.1-T2V-14B") # 2. 約 121 行目のコードを修正し、test_step 関数の save_video 入力パラメーター、ビデオフレームレート、および圧縮品質を修正します。1 は最低品質を示します。10 は最高品質を示します。 save_video(video, output_path, fps=24, quality=10) # 3. 約 135 行目に次の入力パラメーターを追加して、解像度を変更します。デフォルト値は 480p です。 .... "output_path": "video1.mp4", # 次の 2 行は新しく追加されました。 "height": 720, "width": 1280, }, # 4. ファイルを保存してエディターを終了します。 :wq
テストスクリプトの実行
# テストスクリプトを実行します。
torchrun --standalone --nproc_per_node=2 /root/DiffSynth-Studio/examples/wanvideo/wan_14b_text_to_video_tensor_parallel.py
ビデオの生成
出力パスを変更するには、「(オプション)テストスクリプトの最適化」セクションの項目 3 のoutput_path の値を変更します。
テスト時間については、プログレスバーの残り時間プロンプトを参照できます。実行が完了すると、ビデオファイル video1.mp4 が生成されます。 ossutil を使用して生成されたビデオを Alibaba Cloud OSS にインポートする方法については、「オブジェクトのコピー」をご参照ください。