Object Storage Service (OSS) アクセラレータは、データセットの読み込み速度を大幅に向上させ、モデルトレーニング全体の速度を改善できます。このトピックでは、広範なテストに基づいて OSS アクセラレータを使用した場合と使用しない場合のパフォーマンスを比較します。結果は、GPU 使用率がボトルネックでない場合、データ読み込み効率が重要であることを示しています。このトピックでは、ImageNet ILSVRC データセットで事前トレーニング済みの ResNet-18 モデルをファインチューニングするタスクを例として、GPU 高速化 ECS インスタンスで OSS アクセラレータを使用してモデルトレーニングを高速化する方法を示します。
高速化効果
標準の OSS バケットと比較して、OSS アクセラレータは大幅なパフォーマンス上の利点を示します。低レイテンシーにより、OSS アクセラレータはより少ないワーカーでより高いスループットを実現します。複数の実験で、OSS アクセラレータはトレーニング効率を 40% から 400% 向上させました。これにより、計算資源の消費とコストが大幅に削減され、より効率的なソリューションが提供されます。
ソリューション概要
次の図は、GPU 高速化 ECS インスタンスで OSS アクセラレータを使用してトレーニングデータの読み込みを高速化するプロセスを示しています。

この高速化効果は 3 つのステップで実現できます。
GPU 高速化 ECS インスタンスの作成: モデルトレーニングのニーズを満たす GPU 高速化 ECS インスタンスを作成します。
OSS バケットの作成と OSS アクセラレータの有効化: OSS バケットを作成し、その OSS アクセラレータを有効化します。トレーニングタスク用にバケットの内部エンドポイントと OSS アクセラレータのエンドポイントを取得します。
モデルのトレーニング: 環境が準備された後、生データセットを前処理して OSS にアップロードします。次に、トレーニング中に OSS アクセラレータを使用してデータセットをローカルマシンに読み込み、モデルをトレーニングします。
手順
ステップ 1: GPU 高速化 ECS インスタンスの作成
モデルトレーニング用に GPU 高速化 ECS インスタンスを作成して接続するには、次の手順に従います。インスタンスタイプは [ecs.gn6i-c4g1.xlarge]、オペレーティングシステムは Ubuntu 22.04、CUDA バージョンは 12.4.1 です。インスタンス構成をカスタマイズする際は、最新の CUDA バージョンを選択してください。
1. GPU 高速化 ECS インスタンスの作成
インスタンス作成ページに移動します。
[カスタム起動] タブをクリックします。
課金方法、リージョン、ネットワーク、ゾーン、インスタンスタイプ、イメージなどのパラメーターを必要に応じて設定します。作成を完了します。設定項目の詳細については、「設定項目」をご参照ください。
重要OSS アクセラレータ機能は、中国 (杭州)、中国 (上海)、中国 (北京)、中国 (ウランチャブ)、中国 (深圳)、およびシンガポールリージョンでパブリックプレビュー中です。作成する GPU 高速化 ECS インスタンスがこれらのリージョンのいずれかにあることを確認してください。このトピックでは、中国 (杭州) リージョンを例として使用します。
この例で使用される ECS インスタンスタイプは [ecs.gn6i-c4g1.xlarge] です。これは参考用です。
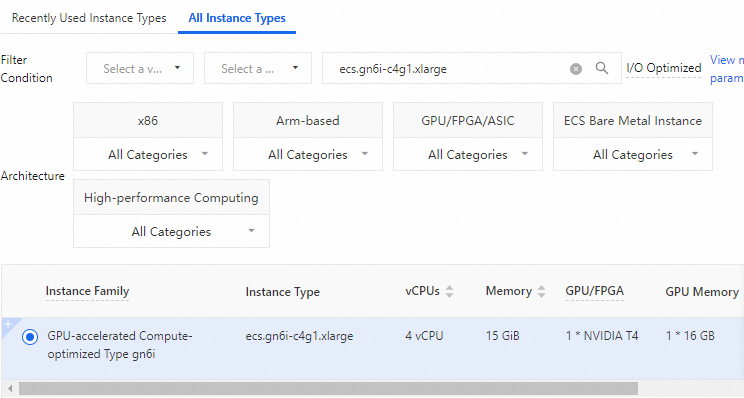
この例では、[Ubuntu 22.04] オペレーティングシステムイメージを使用します。[GPU ドライバーのインストール] を選択し、CUDA バージョンを [CUDA 12.4.1] に設定します。CUDA 環境はサーバー起動時に自動的にインストールされるため、手動での設定は不要です。

2. GPU 高速化 ECS インスタンスへの接続
[ECS コンソール] の インスタンス ページで、リージョンとインスタンス ID によって作成した ECS インスタンスを見つけます。[アクション] 列で、[接続] をクリックします。
[リモート接続] ダイアログボックスで、[Workbench 経由で接続] の [今すぐログイン] をクリックします。
[インスタンスにログイン] ダイアログボックスで、[認証方法] を GPU 高速化 ECS インスタンスの作成時に選択したログイン認証情報の方法に設定します。たとえば、[SSH キーペア認証] を選択します。ユーザー名を入力し、キーペアの作成時にダウンロードした秘密鍵ファイルを入力またはアップロードします。[ログイン] をクリックして ECS インスタンスにログインします。
説明秘密鍵ファイルは、キーペアを作成すると自動的にローカルマシンにダウンロードされます。ブラウザのダウンロード履歴を確認して、
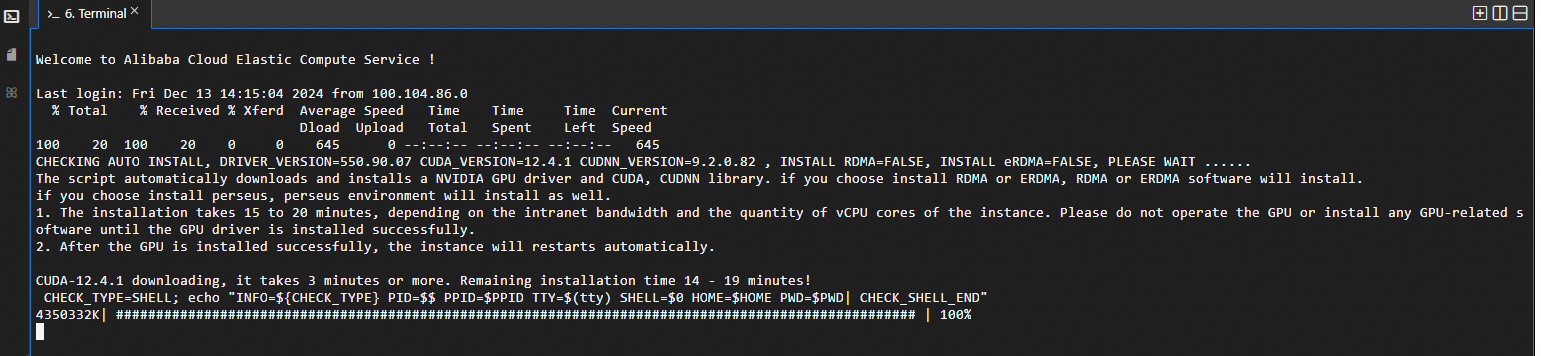
.pem形式の秘密鍵ファイルを見つけてください。次のページが表示されたら、ECS インスタンスへのログインに成功し、CUDA ドライバーの自動インストールが開始されています。インストールが完了するまでお待ちください。
ステップ 2: OSS バケットの作成と OSS アクセラレータの有効化
データセットを保存するためのバケットを作成し、GPU 高速化 ECS インスタンスと同じリージョンでバケットの OSS アクセラレータを有効にするには、次の手順に従います。これにより、データセットへのアクセス速度が向上します。ECS インスタンスとバケットが同じリージョンにあり、内部エンドポイント経由でバケットにアクセスする場合、トラフィック料金は発生しないことに注意してください。
バケットの作成と内部エンドポイントの取得
重要OSS アクセラレータ機能は、中国 (杭州)、中国 (上海)、中国 (北京)、中国 (ウランチャブ)、中国 (深圳)、およびシンガポールリージョンでパブリックプレビュー中です。作成するバケットがこれらのリージョンのいずれかにあり、GPU 高速化 ECS インスタンスと同じリージョンにあることを確認してください。このトピックでは、中国 (杭州) リージョンを例として使用します。
OSS コンソールの バケットリスト ページに移動し、[バケットの作成] をクリックします。
[バケットの作成] パネルで、画面の指示に従ってバケットを作成します。
宛先バケットの [概要] ページで、ポートセクションに移動します。[ECS からの VPC 経由のアクセス (内部ネットワーク)] の [エンドポイント] をコピーし、後で使用するために保存します。このエンドポイントを使用して、トレーニング中にデータセットとチェックポイントを宛先バケットにアップロードします。

OSS アクセラレータの有効化とアクセラレータエンドポイントの取得
OSS コンソールの バケットリスト ページに移動します。宛先バケットを選択します。左側のナビゲーションウィンドウで、 を選択して [OSS アクセラレータ] ページに移動します。
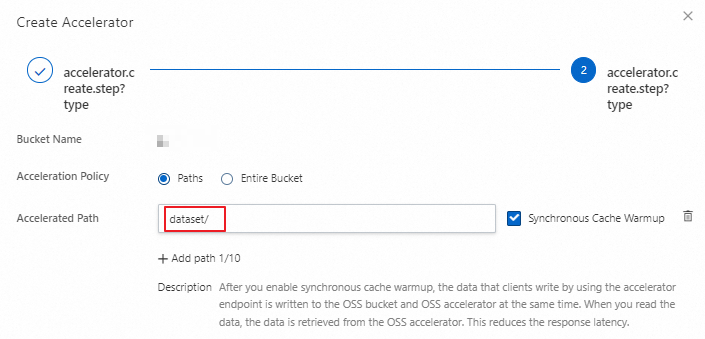
[OSS アクセラレータの作成] をクリックします。**[OSS アクセラレータの作成]** パネルで、アクセラレータの容量を設定します。この例では、500 GB が使用されます。[次へ] をクリックします。
[指定パスの高速化] を選択し、データセットが保存されているディレクトリへの高速化パスを設定してから、[OK] をクリックします。その後、画面の指示に従ってアクセラレータを作成します。
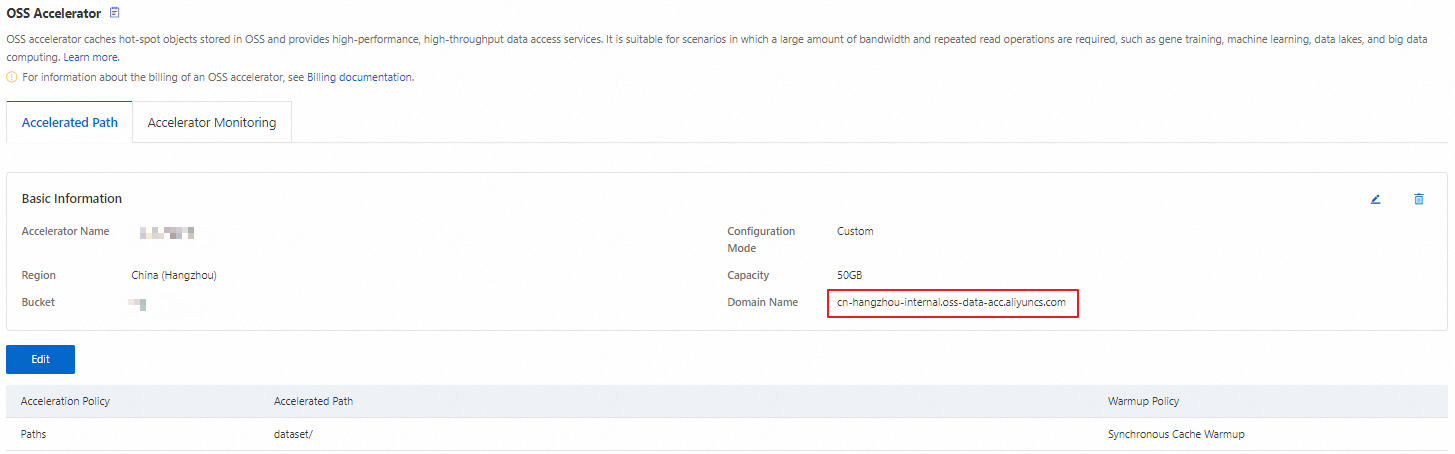
**[OSS アクセラレータ]** ページで、アクセラレータのエンドポイントをコピーし、後で使用するために保存します。このエンドポイントを使用して、トレーニング中に宛先バケットからデータセットをダウンロードします。
ステップ 3: モデルのトレーニング
GPU 高速化 ECS インスタンスで次の手順に従い、モデルトレーニング環境を設定し、データセットをアップロードし、OSS アクセラレータのエンドポイントを使用してモデルトレーニングを高速化します。
完全なコードベースプロジェクトについては、「demo.tar.gz」をご参照ください。
以下のすべての手順には root 権限が必要です。トレーニングを開始する前に root ユーザーに切り替えてください。
トレーニング環境の設定
conda 環境を準備し、依存関係を構成します。
次のコマンドを実行して conda をダウンロードしてインストールします。
curl -L https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -o /tmp/miniconda.sh && bash /tmp/miniconda.sh -b -p /opt/conda/ && rm /tmp/miniconda.sh && /opt/conda/bin/conda clean -tipy && export PATH=/opt/conda/bin:$PATH && conda init bash && source ~/.bashrc && conda update condavim environment.yamlコマンドを実行して、environment.yamlという名前の conda 環境ファイルを作成して開きます。次の構成を追加してファイルを保存します。name: py312 channels: - defaults - conda-forge - pytorch dependencies: - python=3.12 - pytorch>=2.5.0 - torchvision - torchaudio - transformers - torchdata - oss2次のコマンドを実行して、環境ファイルから py312 という名前の conda 環境を作成します。
conda env create -f environment.yamlconda activate py312コマンドを実行して、py312 という名前の conda 環境をアクティブ化します。次の図は、環境がアクティブ化されたことを示しています。 重要
重要後続の手順は、アクティブ化された conda 環境で実行してください。
環境変数を構成します。
次のコマンドを実行して、データセットのアップロードに必要なアクセス認証情報を設定します。
<ACCESS_KEY_ID>と<ACCESS_KEY_SECRET>を RAM ユーザーの AccessKey ID と AccessKey シークレットに置き換えます。AccessKey ID と AccessKey シークレットの作成方法の詳細については、「AccessKey ペアの作成」をご参照ください。export OSS_ACCESS_KEY_ID=<ACCESS_KEY_ID> export OSS_ACCESS_KEY_SECRET=<ACCESS_KEY_SECRET>OSS コネクタを設定します。
次のコマンドを実行して OSS コネクタをインストールします。
pip install osstorchconnector次のコマンドを実行して、アクセス認証情報設定ファイルを作成します。
mkdir -p /root/.alibabacloud && touch /root/.alibabacloud/credentialsvim /root/.alibabacloud/credentialsコマンドを実行して設定ファイルを開きます。次の構成を追加してファイルを保存します。OSS コネクタの設定方法の詳細については、「AI/ML 用 OSS コネクタの設定」をご参照ください。以下は、アクセス認証情報として AccessKey ID と AccessKey シークレットを使用する設定例です。
<AccessKeyId>と<AccessKeySecret>を RAM ユーザーの AccessKey ID と AccessKey シークレットに置き換えます。AccessKey ID と AccessKey シークレットの作成方法の詳細については、「AccessKey ペアの作成」をご参照ください。{ "AccessKeyId": "LTAI************************", "AccessKeySecret": "At32************************" }次のコマンドを実行して、認証情報ファイルに読み取り専用権限を設定し、AccessKey ID と AccessKey シークレットを保護します。
chmod 400 /root/.alibabacloud/credentials次のコマンドを実行して、OSS コネクタの設定ファイルを作成します。
mkdir -p /etc/oss-connector/ && touch /etc/oss-connector/config.jsonvim /etc/oss-connector/config.jsonコマンドを実行して設定ファイルを開きます。次の構成を追加してファイルを保存します。ほとんどの場合、デフォルトの構成を使用できます。{ "logLevel": 1, "logPath": "/var/log/oss-connector/connector.log", "auditPath": "/var/log/oss-connector/audit.log", "datasetConfig": { "prefetchConcurrency": 24, "prefetchWorker": 2 }, "checkpointConfig": { "prefetchConcurrency": 24, "prefetchWorker": 4, "uploadConcurrency": 64 } }
データの準備
トレーニングデータセットと検証データセットを宛先バケットにアップロードします。
次のコマンドを実行して、トレーニングデータセットと検証データセットを ECS インスタンスにダウンロードします。このデータセットは実際の実験で使用されたデータセットではなく、テスト目的のみであることに注意してください。
wget https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241216/jsnenr/n04487081.tar wget https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241218/dxrciv/n10148035.tar wget https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241216/senwji/val.tar次のコマンドを実行して、ダウンロードしたデータセットを解凍し、現在のパスに作成された `dataset` ディレクトリに配置します。
tar -zxvf n10148035.tar && tar -zxvf n04487081.tar && tar -zxvf val.tar mkdir dataset && mkdir ./dataset/train && mkdir ./dataset/val mv n04487081 ./dataset/train/ && mv n10148035 ./dataset/train/ && mv IL*.JPEG ./dataset/val/python3 upload_dataset.pyコマンドを実行してスクリプトを実行します。これにより、解凍されたデータセットが指定されたバケットにアップロードされます。# upload_dataset.py from torchvision import transforms from PIL import Image import oss2 import os from oss2.credentials import EnvironmentVariableCredentialsProvider # 中国 (杭州) リージョンの内部エンドポイントを例として使用します。 OSS_ENDPOINT = "oss-cn-hangzhou-internal.aliyuncs.com" # OSS の内部エンドポイント。 OSS_BUCKET_NAME = "<YourBucketName>" # 宛先バケットの名前。 BUCKET_REGION = "cn-hangzhou" # 宛先バケットのリージョン。 # OSS_URI_BASE: OSS バケット内のカスタムストレージプレフィックス。 OSS_URI_BASE = "dataset/imagenet/ILSVRC/Data" def to_tensor(img_path): IMG_DIM_224 = 224 compose = transforms.Compose([ transforms.RandomResizedCrop(IMG_DIM_224), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]) img = Image.open(img_path).convert('RGB') img_tensor = compose(img) numpy_data = img_tensor.numpy() binary_data = numpy_data.tobytes() return binary_data def list_dir(directory): for root, _, files in os.walk(directory): rel_root = os.path.relpath(root, start=directory) for file in files: rel_filepath = os.path.join(rel_root, file) if rel_root != '.' else file yield rel_filepath IMG_DIR_BASE = "./dataset" """ IMG_DIR_BASE は、イメージが保存されているローカルパスです。絶対パスまたは相対パスを使用できます。 ディレクトリ構造は、以下に示すように、実際のデータセット構造と一致している必要があります。 {IMG_DIR_BASE}/ train/ n10148035/ n10148035_10034.JPEG n10148035_10217.JPEG ... n11879895/ n11879895_10016.JPEG n11879895_10019.JPEG ... ... val/ ILSVRC2012_val_00000001.JPEG ILSVRC2012_val_00000002.JPEG ... """ bucket_api = oss2.Bucket(oss2.ProviderAuthV4(EnvironmentVariableCredentialsProvider()), OSS_ENDPOINT, OSS_BUCKET_NAME, region=BUCKET_REGION) for phase in [ "val", "train"]: IMG_DIR = "%s/%s" % (IMG_DIR_BASE, phase) for _, img_relative_path in enumerate(list_dir(IMG_DIR)): img_bin_name = img_relative_path.replace(".JPEG", ".pt") object_key = "%s/%s/%s" % (OSS_URI_BASE, phase, img_bin_name) bucket_api.put_object(object_key, to_tensor("%s/%s" % (IMG_DIR,img_relative_path)))
イメージデータセットのラベルファイルをダウンロードして、データセットの分類マッピングを構築します。
wget https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241220/izpskr/imagenet_class_index.json wget https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241220/lfilrp/ILSVRC2012_val_labels.json
トレーニングプロセス
ImageNet データセットを処理するためのユーティリティモジュールを構築します。このモジュールは、OSS アクセラレータのエンドポイントを使用して OSS アクセラレータからデータセットをダウンロードし、データローダーを構築します。
事前トレーニング済みの ResNet18 モデルを初期化するためのユーティリティモジュールを構築します。
ResNet モデルをトレーニングするためのユーティリティモジュールを構築します。このモジュールは、指定されたモデル、データローダー、およびエポック数 (epoch_num) に基づいてモデルをトレーニングします。
モデルトレーニングプロセスを統合するためのメインスクリプトファイルを構築します。このファイルは、先行するユーティリティモジュールを統合してモデルトレーニングを開始します。
python3 main.pyコマンドを実行してモデルトレーニングを開始します。次の図は、トレーニングプロセスが正常に開始されたことを示しています。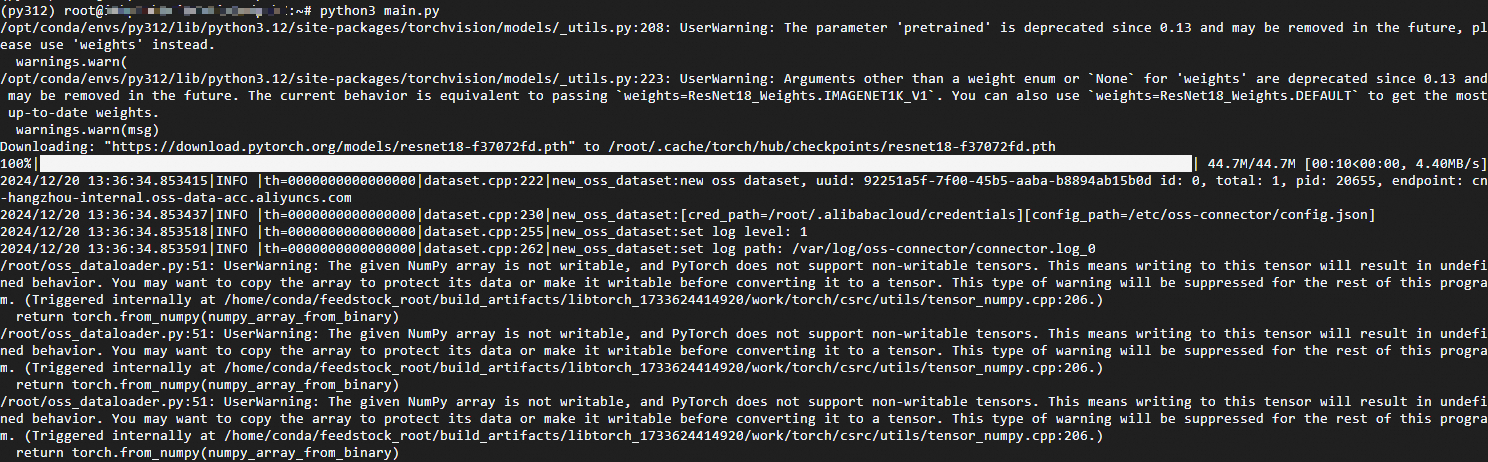
結果の確認
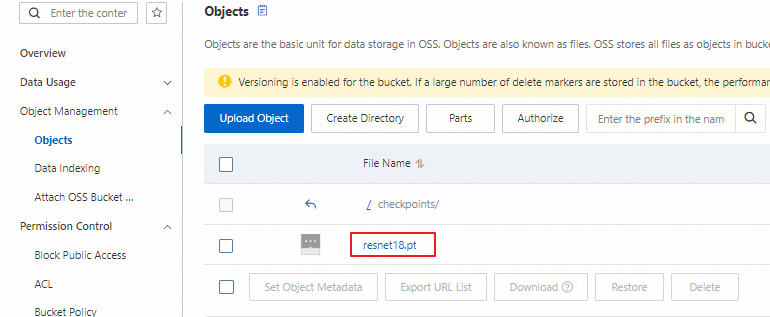
バケットリスト ページに移動し、宛先バケットを選択して をクリックします。`checkpoints` ディレクトリに `resnet18.pt` ファイルがあるか確認します。次の図に示すように、トレーニング完了後、チェックポイントファイルは正常に OSS にアップロードされます。