大規模言語モデル (LLM) は、企業固有のデータやリアルタイムのデータが不足している場合があります。検索拡張生成 (RAG) 技術は、LLM に非公開ナレッジベースへのコンテキストアクセスを提供することで、モデルの応答の精度と関連性を向上させます。LangStudio を使用して、金融やヘルスケアなどの専門ドメイン向けの RAG アプリケーションを開発およびデプロイできます。
背景情報
現代の情報検索において、RAG モデルは情報検索と生成系人工知能の利点を組み合わせ、特定のシナリオでより正確で関連性の高い回答を提供します。たとえば、金融やヘルスケアなどの専門分野では、ユーザーは意思決定をサポートするために正確で関連性の高い情報を必要とすることがよくあります。従来の生成モデルは自然言語理解と生成に優れていますが、専門知識の精度に欠ける場合があります。RAG モデルは、検索と生成技術を統合することで、回答の精度とコンテキストの関連性を向上させます。Platform for AI (PAI) は、金融およびヘルスケアシナリオに合わせた RAG ソリューションを提供します。
前提条件
LangStudio は、ベクターデータベースとして Faiss または Milvus をサポートしています。Milvus を使用する場合は、まず Milvus データベースを作成する必要があります。
説明Faiss は通常、ステージング環境で使用され、データベースを作成する必要はありません。本番環境では、より大きなデータボリュームを処理できるため、Milvus を使用してください。
RAG ナレッジベースのコーパスは OSS にアップロード済みです。金融およびヘルスケアシナリオ向けに、以下のサンプルコーパスが提供されています。
1. (任意) LLM と埋め込みモデルのデプロイ
RAG アプリケーションフローには、LLM と埋め込みモデルサービスが必要です。モデルギャラリーを使用して、必要なモデルサービスを迅速にデプロイできます。OpenAI API をサポートする準拠したモデルサービスが既にある場合は、このステップをスキップして既存のサービスを使用できます。
[クイックスタート] > [モデルギャラリー] に移動し、次の 2 つのシナリオのモデルをデプロイします。デプロイメントの詳細については、「モデルのデプロイとトレーニング」をご参照ください。
インストラクションチューニングを使用する LLM を選択してください。ベースモデルは、ユーザーの命令に正しく従って質問に回答できません。
[シナリオ] を [AIGC] > [large-language-model] に設定し、例として [DeepSeek-R1-Distill-Qwen-7B] モデルをデプロイします。
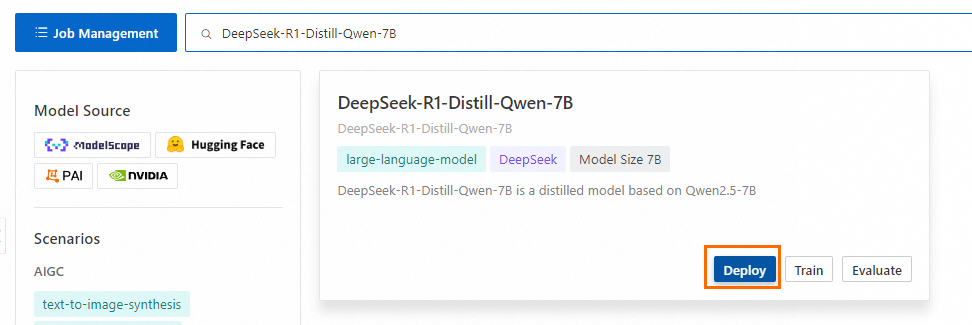
[シナリオ] を [NLP] > [embedding] に設定し、例として [bge-m3 embedding model] をデプロイします。

2. 接続の作成
このトピックで説明する LLM および埋め込みモデルのサービス接続は、[クイックスタート] > [モデルギャラリー] でデプロイされたモデルサービス (EAS サービス) に基づいています。他の接続タイプの詳細については、「接続の構成」をご参照ください。
2.1 LLM サービス接続の作成
LangStudio に移動し、ワークスペースを選択した後、[モデルサービス] タブの [サービス接続設定] ページで [新規接続] をクリックして、汎用の LLM モデルサービス接続を作成します。
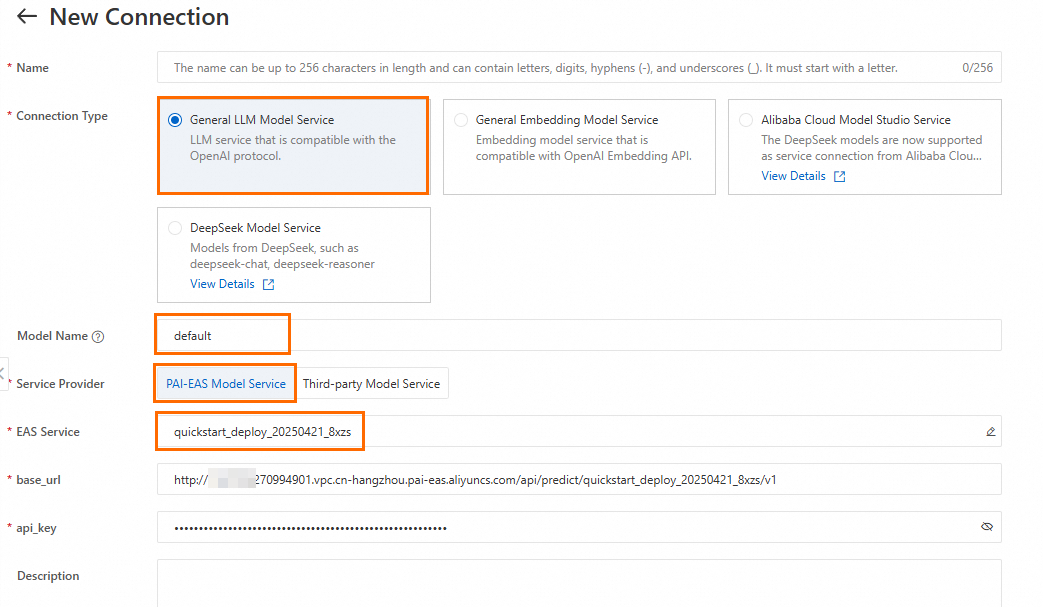
主要なパラメーター:
パラメーター | 説明 |
モデル名 | モデルギャラリーからモデルをデプロイする場合、モデル名の取得方法はモデルの製品ページで確認できます。製品ページに移動するには、[モデルギャラリー] ページのモデルカードをクリックします。詳細については、「モデルサービス接続の作成」をご参照ください。 |
サービスプロバイダー |
|
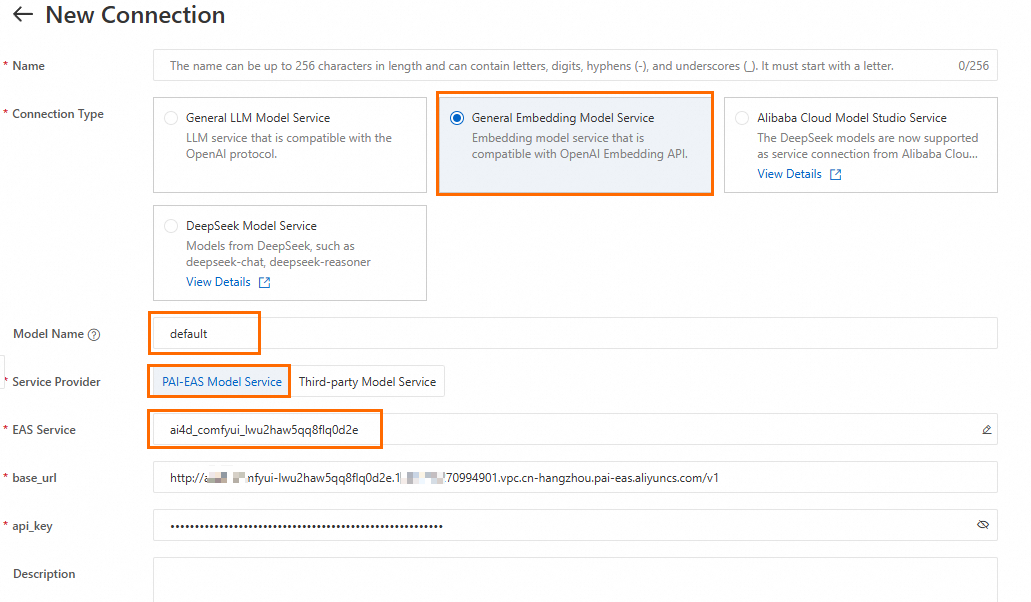
2.2 埋め込みモデルサービス接続の作成
ステップ 2.1 の LLM サービス接続の作成と同様に、汎用の埋め込みモデルサービス接続を作成できます。
2.3 ベクターデータベース接続の作成
[サービス接続設定] ページの [データベース] タブで、[新しい接続] をクリックして Milvus データベース接続を作成します。
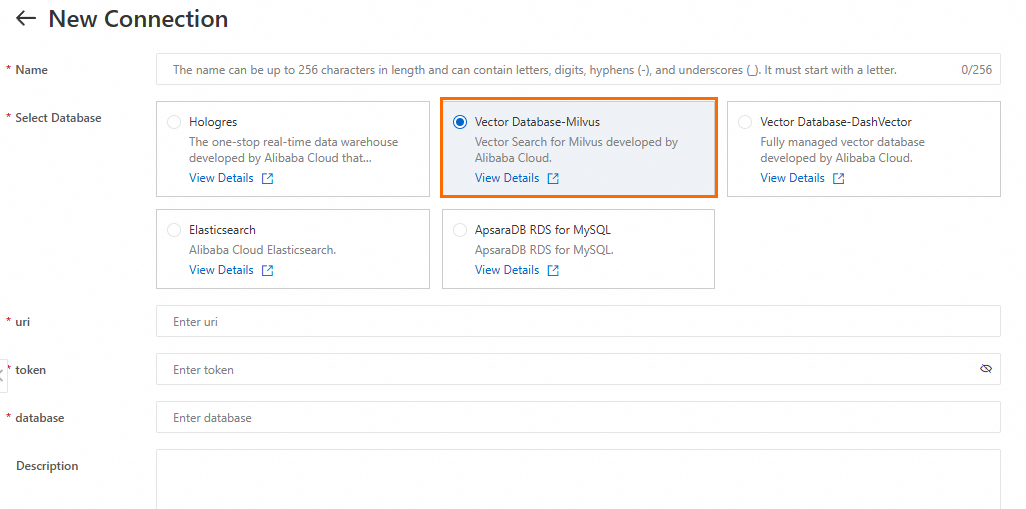
主要なパラメーター:
パラメーター | 説明 |
uri | Milvus インスタンスのエンドポイント。フォーマットは |
token | Milvus インスタンスにログインするためのユーザー名とパスワード。フォーマットは |
database | データベース名。次の例では、デフォルトのデータベース |
3. ナレッジベースインデックスの作成
ナレッジベースインデックスを作成して、コーパスを解析、チャンク化、ベクトル化できます。結果はベクターデータベースに保存され、ナレッジベースが構築されます。次の表に主要なパラメーターを示します。その他の設定については、「ナレッジベース管理」をご参照ください。
パラメーター | 説明 |
基本構成 | |
データソース OSS パス | 「前提条件」セクションの RAG ナレッジベースコーパスの OSS パス。 |
出力 OSS パス | ドキュメント解析から生成された中間結果とインデックス情報を保存するパス。 重要 FAISS をベクトルデータベースとして使用する場合、アプリケーションフローは生成されたマニフェストを OSS に保存します。デフォルトの PAI ロール (アプリケーションフロー開発のランタイムを開始するときに設定される [RAM ロール]) を使用する場合、アプリケーションフローは、デフォルトでワークスペースのデフォルトストレージバケットにアクセスできます。したがって、このパラメーターを、ワークスペースのデフォルトストレージパスがある OSS バケット内の任意のディレクトリに設定します。カスタムロールを使用する場合、カスタムロールに OSS へのアクセス権限を付与する必要があります。AliyunOSSFullAccess 権限を付与することを推奨します。詳細については、「RAM ロールの権限を管理する」をご参照ください。 |
埋め込みモデルとデータベース | |
埋め込みタイプ | [一般的な埋め込みモデル] を選択します。 |
埋め込み接続 | 「ステップ 2.2」で作成した埋め込みモデルサービス接続を選択します。 |
ベクトルデータベースタイプ | [ベクトルデータベース Milvus] を選択します。 |
ベクトルデータベース接続 | 「ステップ 2.3」で作成した Milvus データベース接続を選択します。 |
テーブル名 | 「前提条件」セクションで作成した Milvus データベースのコレクション。 |
VPC 構成 | |
VPC 設定 | 設定された VPC が Milvus インスタンスの VPC と同じであるか、選択された VPC が Milvus インスタンスが配置されている VPC に接続されていることを確認してください。 |
4. RAG アプリケーションフローの作成と実行
LangStudio に移動し、ワークスペースを選択してから、[アプリケーションフロー] タブで [新規アプリケーションフロー] をクリックして RAG アプリケーションフローを作成します。
ランタイムの開始: 右上隅で [ランタイムの作成] をクリックし、パラメーターを設定します。注意: Python ノードを解析したり、その他のツールを表示したりするには、ランタイムを開始する必要があります。
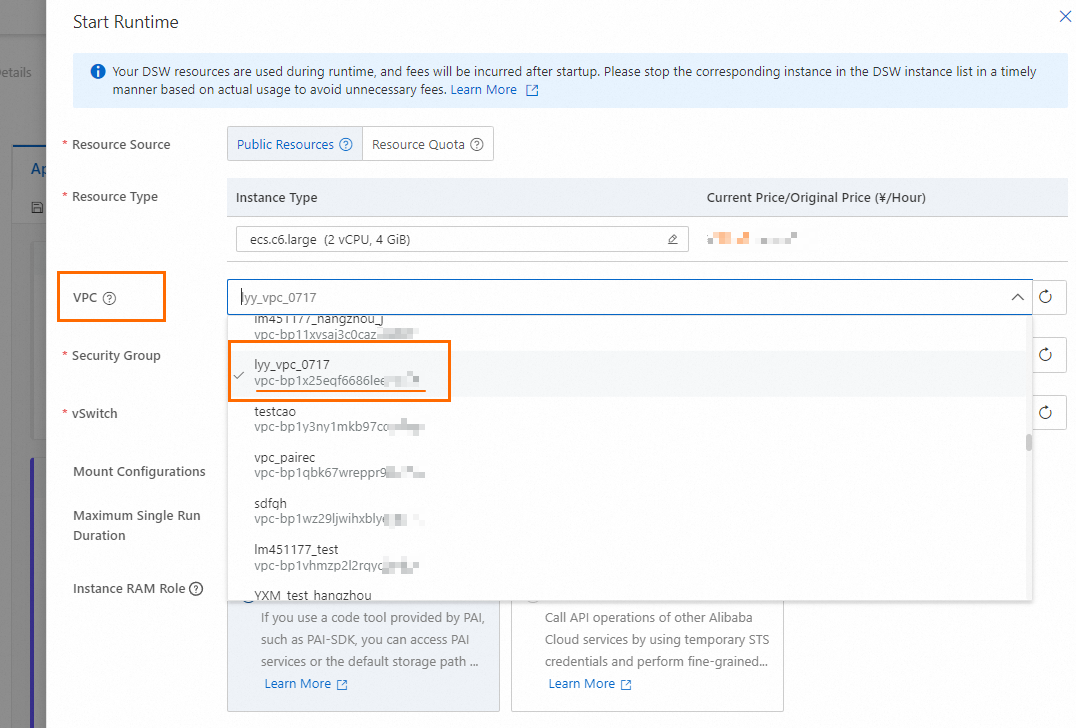
主要なパラメーター:
VPC 設定:「前提条件」セクションで Milvus インスタンスを作成したときに使用した VPC を選択するか、選択した VPC が Milvus インスタンスが配置されている VPC に接続されていることを確認してください。
アプリケーションフローを開発します。

アプリケーションフローの他の設定はデフォルトのままにするか、必要に応じて設定します。主要なノード設定は次のとおりです。
ナレッジベース検索:ユーザーの質問に関連するテキストをナレッジベースから取得します。
ナレッジベースインデックス名:「3. ナレッジベースインデックスの作成」で作成したナレッジベースインデックスを選択します。
Top K:返される上位 K 件の一致データエントリの数。
LLM ノード:取得したドキュメントをコンテキストとして使用し、ユーザーの質問とともに LLM に送信して応答を生成します。
モデル設定:「2.1 LLM サービス接続の作成」で作成した接続を選択します。
チャット履歴:チャット履歴を有効にし、過去の会話情報を入力変数として使用するかどうかを指定します。
各ノードコンポーネントの詳細については、「事前構築済みコンポーネントの説明」をご参照ください。
デバッグ/実行: 右上隅で[実行]をクリックすると、アプリケーションフローが実行されます。アプリケーションフローの実行時に発生する可能性のある一般的な問題については、「よくある質問」をご参照ください。
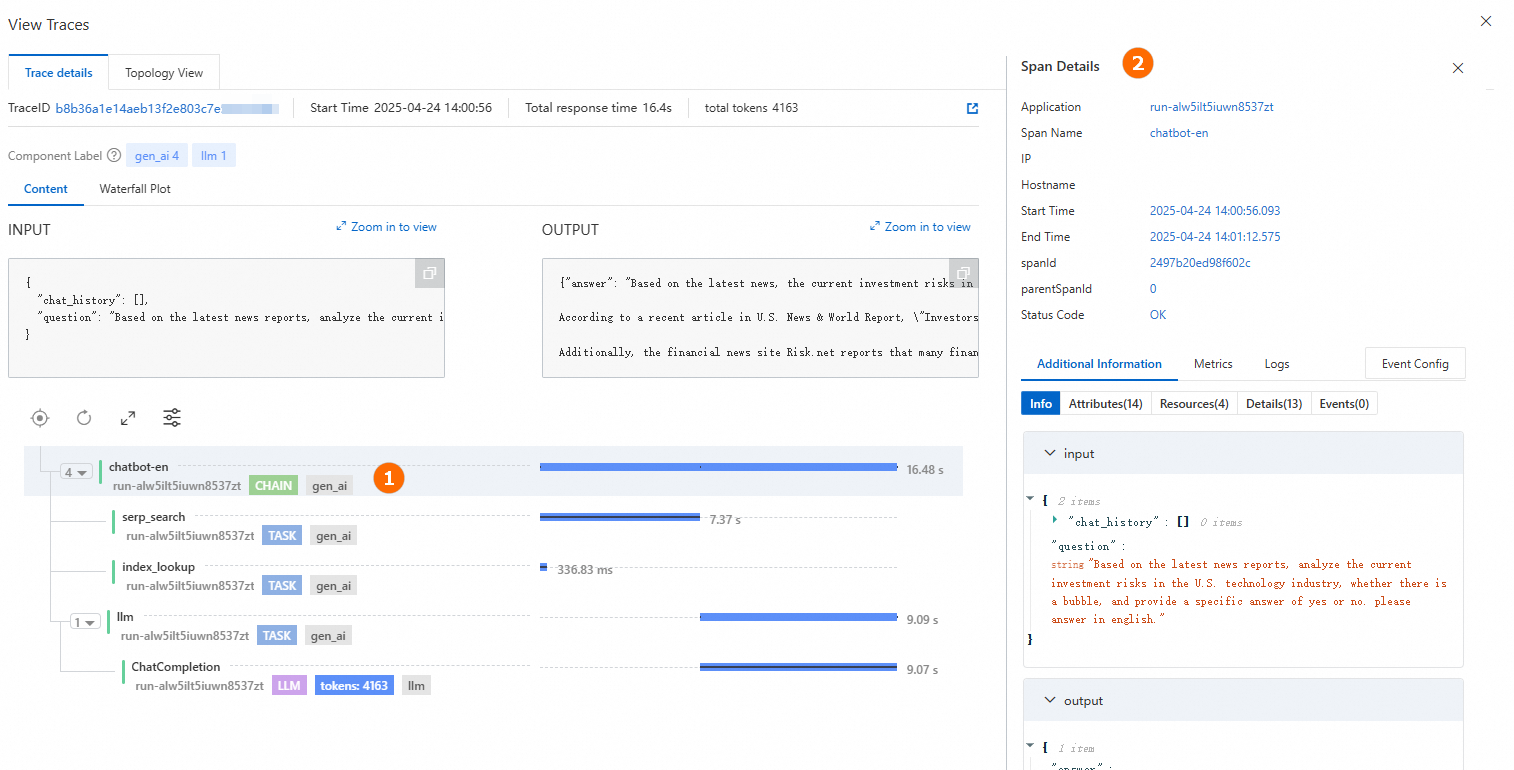
リンクの表示: 生成された回答の下で[リンクを表示]をクリックすると、トレース詳細またはトポロジーを表示できます。
5. アプリケーションフローのデプロイ
アプリケーションフロー開発ページで、右上隅の [デプロイ] をクリックして、アプリケーションフローを EAS サービスとしてデプロイします。その他のデプロイメントパラメーターはデフォルト設定のままにするか、必要に応じて設定します。主要なパラメーター設定は次のとおりです。
リソースデプロイメント > インスタンス数:サービスインスタンスの数を設定します。このデプロイメントはテスト専用であるため、インスタンス数を 1 に設定します。本番環境では、単一障害点のリスクを軽減するために、複数のサービスインスタンスを設定してください。
VPC > VPC:Milvus インスタンスが配置されている VPC を選択するか、選択した VPC が Milvus インスタンスが配置されている VPC に接続されていることを確認してください。
デプロイメントの詳細については、「アプリケーションフローをデプロイする」をご参照ください。
6. サービスの呼び出し
デプロイメントが成功すると、PAI-EAS ページにリダイレクトされます。[オンラインデバッグ] タブで、リクエストを設定して送信できます。リクエストボディのキーは、アプリケーションフローの「開始」ノードの「チャット入力」フィールドと同じである必要があります。次の例では、デフォルトのフィールド question を使用します。

API を使用するなど、他のサービス呼び出し方法の詳細については、「サービスの呼び出し」をご参照ください。