このトピックでは、EasyRecアルゴリズムライブラリを使用してモデルをトレーニングし 、ルーチンパイプラインを構築する方法の例を示します。
前提条件
- データサイエンスクラスタが作成されており、クラスタの作成時にオプションサービスからKubeflowが選択されています。 詳細については、クラスタの作成をご参照ください。
- オンプレミスマシンにPuTTYと SSH Secure File Transfer Client がインストールされています。
- dsdemoコードがダウンロードされています。 データサイエンスクラスタを作成した場合は、32497587 番のDingTalkグループに参加してdsdemoコードを入手できます。
手順
手順 1:準備を行う
- オプション:SDKをインストールします。
- SSHモードでクラスタにログオンします。 詳細については、クラスタへのログオンをご参照ください。
- マスターノードで次のコマンドを実行して、seldon_core SDKと kfp SDKをインストールします。
pip3.7 install seldon_core kfp configobj説明 seldon_core SDKと kfp SDKが既にインストールされている場合は、この手順をスキップしてください。
- コンテナレジストリコンソール にログオンします。 Container Registry 個人版を有効化し、名前空間を作成します。名前空間の作成方法の詳細については、名前空間の管理をご参照ください。説明 Container Registry 企業版は、Container Registry 個人版よりも高いセキュリティを提供します。 そのため、Container Registry 企業版を使用することをお勧めします。 Container Registry 企業版を使用する場合は、名前空間の作成時に [デフォルトのリポジトリタイプ] を [パブリック] に設定する必要があります。
- config ファイルでレジストリのアドレスと実験名前空間の名前を変更します。 その後、レジストリにログオンします。
- 次のコマンドを実行して、ml_on_ds ディレクトリにアクセスします。
sudo cd /root/dsdemo/ml_on_ds - 次のコマンドを実行して、config ファイルのレジストリアドレスを表示します。
# !!! Extremely Important !!! # !!! You must use A NEW EXP different from others !!! EXP=exp1 #!!! ACR, Make sure NAMESPACE is public !!! REGISTRY=registry-vpc.cn-beijing.aliyuncs.com NAMESPACE=dsexperiment #k8s namespace, must be same with username when you are using sub-account. KUBERNETES_NAMESPACE=default #kubernetes dashboard host, header1's public ip or inner ip. KUBERNETES_DASHBOARD_HOST=39.104.**.**:32699 #PREFIX, could be a magic code. PREFIX=prefix #sc NFSPATH=/mnt/disk1/k8s_pv/default_storage_class/ #NFSPATH=/mnt/disk1/nfs/ifs/kubernetes/ # region REGIONID=cn-default # emr-datascience clusterid CLUSTERID="C-DEFAULT" #HDFSADDR, train/test dir should be exist under $HDFSADDR, like #user #└── easy_rec # ├── 20210917 # │ ├── test # │ │ ├── test0.csv # │ │ └── _SUCCESS # │ └── train # │ ├── train0.csv # │ └── _SUCCESS # └── 20210918 # ├── test # │ ├── test0.csv # │ └── _SUCCESS # └── train # ├── train0.csv # └── _SUCCESS HDFSADDR=hdfs://192.168.**.**:9000/user/easy_rec/metric_learning_i2i MODELDIR=hdfs://192.168.**.**:9000/user/easy_rec/metric_learning_i2i REGEX="*.csv" SUCCESSFILE="train/_SUCCESS,test/_SUCCESS,hdfs://192.168.**.**:9000/flag" EVALRESULTFILE=experiment/eval_result.txt # for allinone.sh development based on supposed DATE & WHEN & PREDATE DATE=20220405 WHEN=20220405190001 PREDATE=20220404 # for daytoday.sh & multidays training, use HDFSADDR, MODELDIR START_DATE=20220627 END_DATE=20220628 #HIVEINPUT DATABASE=testdb TRAIN_TABLE_NAME=tb_train EVAL_TABLE_NAME=tb_eval PREDICT_TABLE_NAME=tb_predict PREDICT_OUTPUT_TABLE_NAME=tb_predict_out PARTITION_NAME=ds #DSSM: inference user/item model with user&item feature #metric_learning_i2i: infernece model with item feature #SEP: user&item feature file use same seperator USERFEATURE=taobao_user_feature_data.csv ITEMFEATURE=taobao_item_feature_data.csv SEP="," # faiss_mysql: mysql as user_embedding storage, faiss as itemembedding index. # holo_holo: holo as user & item embedding , along with indexing. VEC_ENGINE=faiss_mysql MYSQL_HOST=mysql.bitnami MYSQL_PORT=3306 MYSQL_USER=root MYSQL_PASSWORD=emr-datascience #wait before pod finished after easyrec's python process end. #example: 30s 10m 1h WAITBEFOREFINISHED=10s #tf train #PS_NUMBER take effect only on training. #WORKER_NUMBER take effect on training and predict. TRAINING_REPOSITORY=tf-easyrec-training TRAINING_VERSION=latest PS_NUMBER=2 WORKER_NUMBER=3 SELECTED_COLS="" EDIT_CONFIG_JSON="" #tf export ASSET_FILES="" CHECKPOINT_DIR= #pytorch train PYTORCH_TRAINING_REPOSITORY=pytorch-training PYTORCH_TRAINING_VERSION=latest PYTORCH_MASTER_NUMBER=1 PYTORCH_WORKER_NUMBER=3 #jax train JAX_TRAINING_REPOSITORY=jax-training JAX_TRAINING_VERSION=latest JAX_MASTER_NUMBER=2 JAX_WORKER_NUMBER=3 #easyrec customize action CUSTOMIZE_ACTION=easy_rec.python.tools.modify_config_test USERDEFINEPARAMETERS="--template_config_path hdfs://192.168.**.**:9000/user/easy_rec/rec_sln_test_dbmtl_v3281_template.config --output_config_path hdfs://192.168.**.**:9000/user/easy_rec/output.config" #hivecli HIVE_REPOSITORY=ds_hivecli HIVE_VERSION=latest #ds-controller DSCONTROLLER_REPOSITORY=ds_controller DSCONTROLLER_VERSION=latest #notebook NOTEBOOK_REPOSITORY=ds_notebook NOTEBOOK_VERSION=latest #hue HUE_REPOSITORY=ds_hue HUE_VERSION=latest #httpd HTTPD_REPOSITORY=ds_httpd HTTPD_VERSION=latest #postgist POSTGIS_REPOSITORY=ds_postgis POSTGIS_VERSION=latest #customize CUSTOMIZE_REPOSITORY=ds_customize CUSTOMIZE_VERSION=latest #faissserver FAISSSERVER_REPOSITORY=ds_faissserver FAISSSERVER_VERSION=latest #vscode VSCODE_REPOSITORY=ds_vscode VSCODE_VERSION=latest # ak/sk for cluster resize, only support resize TASK now!!! EMR_AKID=AAAAAAAA EMR_AKSECRET=BBBBBBBB HOSTGROUPTYPE=TASK INSTANCETYPE=ecs.g6.8xlarge NODECOUNT=1 SYSDISKCAPACITY=120 SYSDISKTYPE=CLOUD_SSD DISKCAPACITY=480 DISKTYPE=CLOUD_SSD DISKCOUNT=4 # pvc_name, may not be changed, cause EXP will make sure that two or more experiment will not conflicts. PVC_NAME="easyrec-volume" SAVEDMODELS_RESERVE_DAYS=3 HIVEDB="jdbc:hive2://192.168.**.**:10000/zqkd" #eval threshold THRESHOLD=0.3 #eval result key, 'auc' 'auc_ctcvr' 'recall@5' EVALRESULTKEY="recall@1" #eval hit rate for vector recall ITEM_EMB_TABLE_NAME=item_emb_table GT_TABLE_NAME=gt_table EMBEDDING_DIM=32 RECALL_TYPE="u2i" TOPK=100 NUM_INTERESTS=1 KNN_METRIC=0 # sms or dingding ALERT_TYPE=sms # sms alert SMS_AKID=AAAAAAAA SMS_AKSECRET=BBBBBBBB SMS_TEMPLATEDCODE=SMS_220default SMS_PHONENUMBERS="186212XXXXX,186211YYYYY" SMS_SIGNATURE="mysignature" # dingtalk alert ACCESS_TOKEN=AAAAAAAA EAS_AKID=AAAAAAAA EAS_AKSECRET=BBBBBBBB EAS_ENDPOINT=pai-eas.cn-beijing.aliyuncs.com EAS_SERVICENAME=datascience_eastest # ak/sk for access oss OSS_AKID=AAAAAAAA OSS_AKSECRET=BBBBBBBB OSS_ENDPOINT=oss-cn-huhehaote-internal.aliyuncs.com OSS_BUCKETNAME=emrtest-huhehaote # !!! Do not change !!! OSS_OBJECTNAME=%%EXP%%_faissserver/item_embedding.faiss.svm # ak/sk for access holo HOLO_AKID=AAAAAAAA HOLO_AKSECRET=BBBBBBBB HOLO_ENDPOINT=hgprecn-cn-default-cn-beijing-vpc.hologres.aliyuncs.com #tensorboard TENSORBOARDPORT=6006 #nni port NNIPORT=38080 #jupyter password JUPYTER_PASSWORD=emr-datascience #enable_overwrite ENABLE_OVERWRITE=true #For some users who are running pyspark & meachine learning jobs in jupyter notebook. #ports for mapping when notebook enabled, multi-users will conflict on same node. HOSTNETWORK=true MAPPING_JUPYTER_NOTEBOOK_PORT=16200 MAPPING_NNI_PORT=16201 MAPPING_TENSORBOARD_PORT=16202 MAPPING_VSCODE_PORT=16203 - 次のコマンドを実行して、イメージを簡単にプッシュできるようにレジストリにログオンします。
docker login --username=<Username> <your_REGISTRY>-registry.cn-beijing.cr.aliyuncs.com説明 イメージを簡単にプルできるように、匿名アクセスを有効にし、[デフォルトのリポジトリタイプ] パラメータを [パブリック] に設定する必要があります。<Username>は、コンテナレジストリコンソールで設定したアクセス認証情報を示します。 アクセス認証情報の設定方法の詳細については、Container Registry 企業版インスタンスのアクセス認証情報を設定するをご参照ください。<your_REGISTRY>は、前の手順で取得したレジストリアドレスを示します。
- 次のコマンドを実行して、ml_on_ds ディレクトリにアクセスします。
- コンテナレジストリリソースにアクセスするために、ネットワークアドレス変換 (NAT) ゲートウェイを設定します。 詳細については、インターネットNATゲートウェイの作成と管理をご参照ください。
- テストデータを準備します。重要 ビジネス要件に基づいて、データサイエンスクラスタのHadoop Distributed File System (HDFS) サービス、またはセルフマネージドHDFSにテストデータを書き込むことができます。 書き込み操作では、通常のネットワーク接続が確保されている必要があります。
sh allinlone.shプロンプトが表示されたら、
ppd) Prepare dataを選択します。
手順 2:タスクを送信する
重要 config ファイルで、リポジトリアドレスをコンテナレジストリリポジトリのアドレスに置き換え、実験名前空間の名前とバージョンを変更します。
- allinone.sh ファイルを実行します。
sh allinone.sh -d次の出力が返されます。loading ./config You are now working on k8snamespace: default *** Welcome to DataScience *** 0) Exit k8s: default ppd) Prepare data ppk) Prepare DS/K8S config cacr) checking ACR 1|build) build training image bnt) build notebook image buildall) build all images(slow) dck) deletecheckpoint ser) showevalresult apc) applyprecheck dpc) deleteprecheck 2) applytraining 3) deletetraining 4) applyeval 5) deleteeval 4d) applyevaldist 5d) deleteevaldist 4hr) applyevalhitrate 5hr) deleteevalhitrate 6) applyexport 7) deleteexport 8) applyserving 9) deleteserving 10) applypredict 11) deletepredict 12) applyfeatureselection 13) deletefeatureselection 14) applycustomizeaction 15) deletecustomizeaction 16) applypytorchtraining 17) deletepytorchtraining mt) multidaystraining dmt) deletemultidaystraining me) multidayseval dme) deletemultidayseval cnt) createnotebook dnt) deletenotebook snt) shownotebooklink cft) createsftp dft) deletesftp sft) showsftplink che) createhue dhe) deletehue she) showhuelink chd) createhttpd dhd) deletehttpd shd) showhttpdlink cvs) createvscode dvs) deletevscode svs) showvscodelink a) kubectl get tfjobs b) kubectl get sdep c) kubectl get pytorchjobs mp|mpl) compile mlpipeline bp|bpl) compile bdpipeline bu) bdupload tb) tensorboard vc) verifyconfigfile spl) showpaireclink tp) kubectl top pods tn) kubectl top nodes util) show nodes utils logs) show pod logs setnl) set k8s node label e|clean) make clean cleanall) make cleanall sml) showmilvuslink sall) show KubeFlow/Grafana/K8SOverview/Spark/HDFS/Yarn/EMR link 99) kubectl get pods 99l) kubectl get pods along with log url > - オプションを入力し、各オプションを入力した後、Enterキーを押します。TensorBoardを使用して、トレーニング中のAUC曲線を表示できます。
- 次のコマンドを実行して、ml_on_ds ディレクトリにアクセスします。
sudo cd /root/dsdemo/ml_on_ds - 次のコマンドを実行して、TensorBoardを実行します。
sh run_tensorboard.shtbを選択して、現在の実験のチェックポイントでTensorBoard情報を表示します。 または、sh run_tensorboard.sh 20211209コマンドを実行して、2021年 12月 9日に実行されたトレーニングタスクのチェックポイントでTensorBoard情報を表示します。説明- デフォルトでは、configファイルのTODAY_MODELDIRパラメータで指定されたモデルディレクトリが使用されます。
sh run_tensorboard.sh hdfs://192.168.**.**:9000/user/easy_rec/20210923/などのコマンドを実行して、日付固有のモデルディレクトリを指定することもできます。 - ビジネス要件に基づいて、run_tensorboard.sh スクリプトのパラメータを変更できます。
- デフォルトでは、configファイルのTODAY_MODELDIRパラメータで指定されたモデルディレクトリが使用されます。
- ブラウザを開き、アドレスバーに http://<yourPublicIPAddress>:6006 と入力し、Enterキーを押して、表示されるページでAUC曲線を表示します。
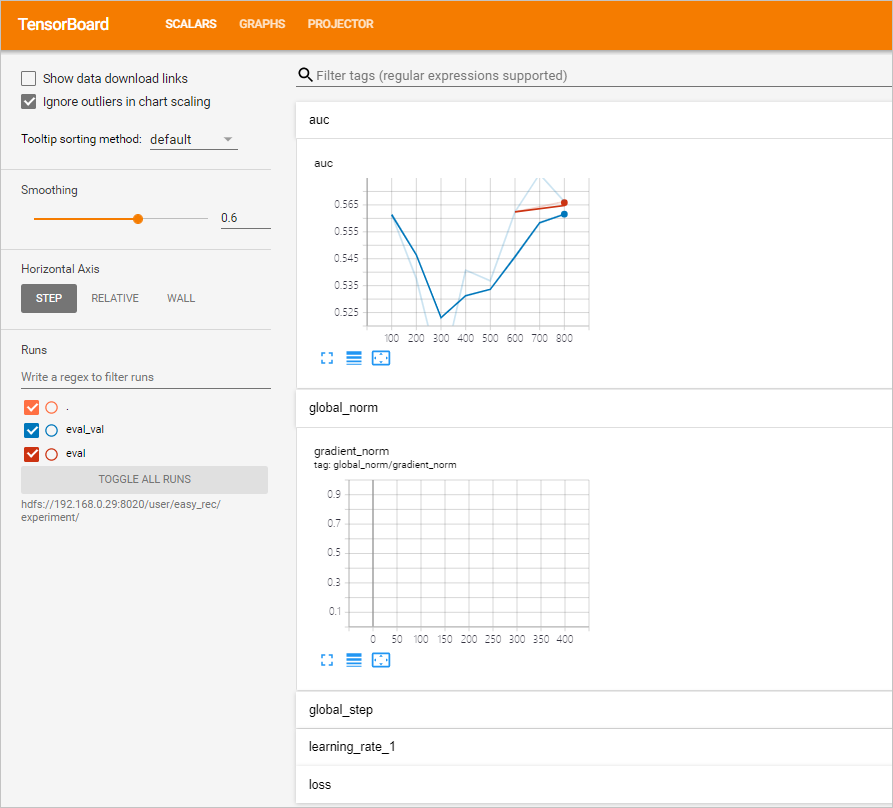
- 次のコマンドを実行して、ml_on_ds ディレクトリにアクセスします。
(オプション) 手順 3:Hive CLI、Spark CLI、ds-controller、Hue、notebookサーバー、またはHTTPdのイメージを作成する
説明
- Hive CLIまたはSpark CLIのイメージを作成する目的は、ビッグデータ処理用のHiveタスクまたはSparkタスクを送信し、トレーニングするデータを生成することです。 関連データを既に準備している場合は、この手順をスキップできます。 Sparkタスクの場合は、データサイエンスクラスタのSparkサービスが使用されます。 Hiveタスクの場合は、個別のHadoopサービスまたはHiveサービスが必要です。
- ds-controller用に作成されたイメージは、動的スケーリングに使用されます。
- Hive CLIHive CLIがインストールされているディレクトリに移動し、イメージを作成します。
cd hivecli && make - Spark CLISpark CLIがインストールされているディレクトリに移動し、イメージを作成します。
cd sparkcli && make - dscontrollerds-controllerがインストールされているディレクトリに移動し、イメージを作成します。
cd dscontroller && make - HueHueがデプロイされているディレクトリに移動し、イメージを作成します。
cd hue && make - notebooknotebookサーバーがデプロイされているディレクトリに移動し、イメージを作成します。
cd notebook && make - httpdHTTPデーモン (HTTPd) がインストールされているディレクトリに移動し、イメージを作成します。
cd httpd && make
手順 4:パイプラインを構築する
パイプラインコードの詳細については、mlpipeline.py ファイルをご参照ください。
- 次のコマンドを実行して、/ml_on_ds ディレクトリにアクセスします。
sudo cd /root/dsdemo/ml_on_ds - 次のコマンドを実行して、パイプラインを構築します。
make mpl説明sh allinone.shコマンドを実行し、mplを選択してパイプラインを構築することもできます。パイプラインが構築されると、***_mlpipeline.tar.gz という名前のファイルが生成されます。 SSH Secure File Transfer Clientを使用して、***_mlpipeline.tar.gz ファイルをオンプレミスマシンにダウンロードします。
手順 5:***_mlpipeline.tar.gzファイルをアップロードする
- インスタンス情報[クラスタ概要] ページの セクションで、マスターノードのパブリックIPアドレスを確認します。
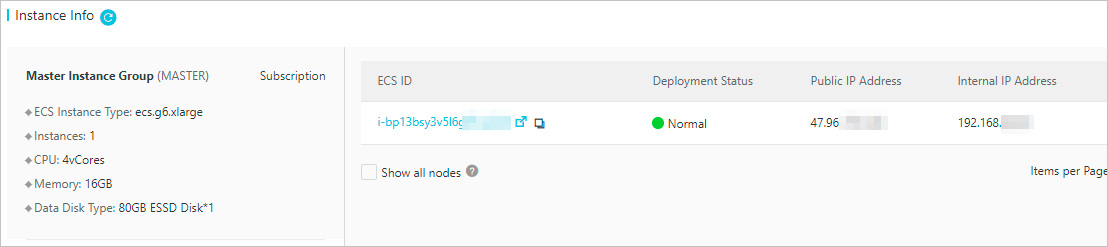
- ブラウザを開き、アドレスバーに http://<yourPublicIPAddress>:31380 と入力し、Enterキーを押します。次の図に示すように、Kubeflowのホームページが表示されます。 デフォルトの匿名名前空間を使用します。説明 <yourPublicIPAddress> は、前の手順で取得したパブリックIPアドレスに置き換えます。
- 左側のナビゲーションペインで、[パイプライン] をクリックします。
- [パイプライン] ページの右上隅にある [パイプラインのアップロード] をクリックします。
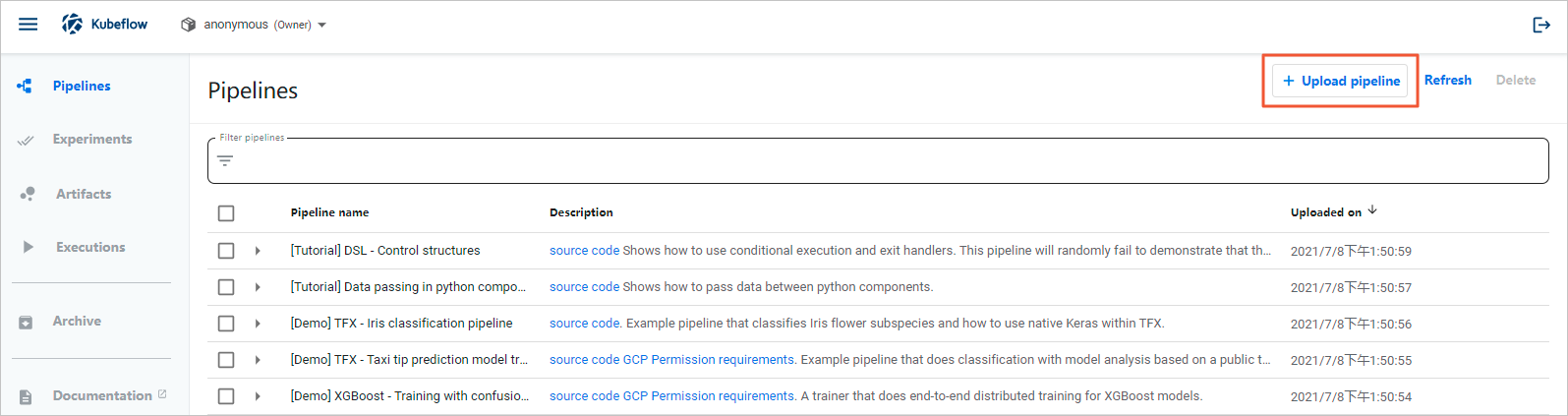
- [パイプラインまたはパイプラインバージョンのアップロード] ページで、[パイプライン名] パラメータと [パイプラインの説明] パラメータを設定し、[ファイルのアップロード] を選択して、***_mlpipeline.tar.gzファイルを選択します。
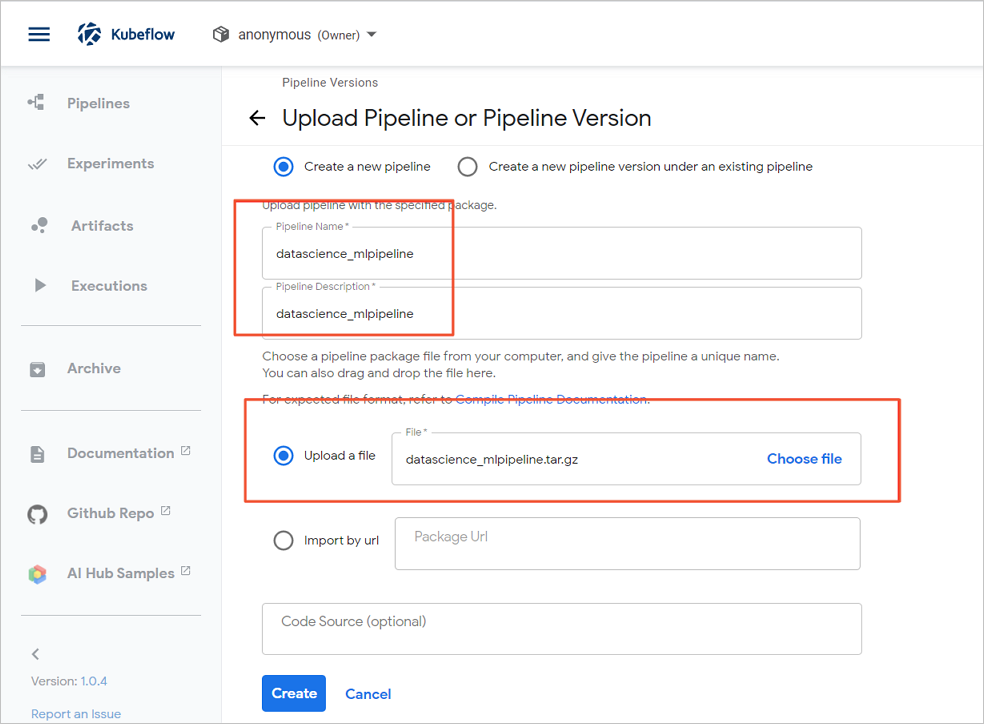
- [作成] をクリックします。
手順 6:実験を作成して実行する
- 左側のナビゲーションペインで、[実験] をクリックします。
- 表示されるページの右上隅にある [実験の作成] をクリックします。
- [新しい実験] ページで、[実験名] を指定します。
- [次へ] をクリックします。
- [実行の開始] ページで、パラメータを設定します。
- 手順 4:パイプラインを構築する でオンプレミスマシンにダウンロードした***_mlpipeline.tar.gzファイルを選択します。
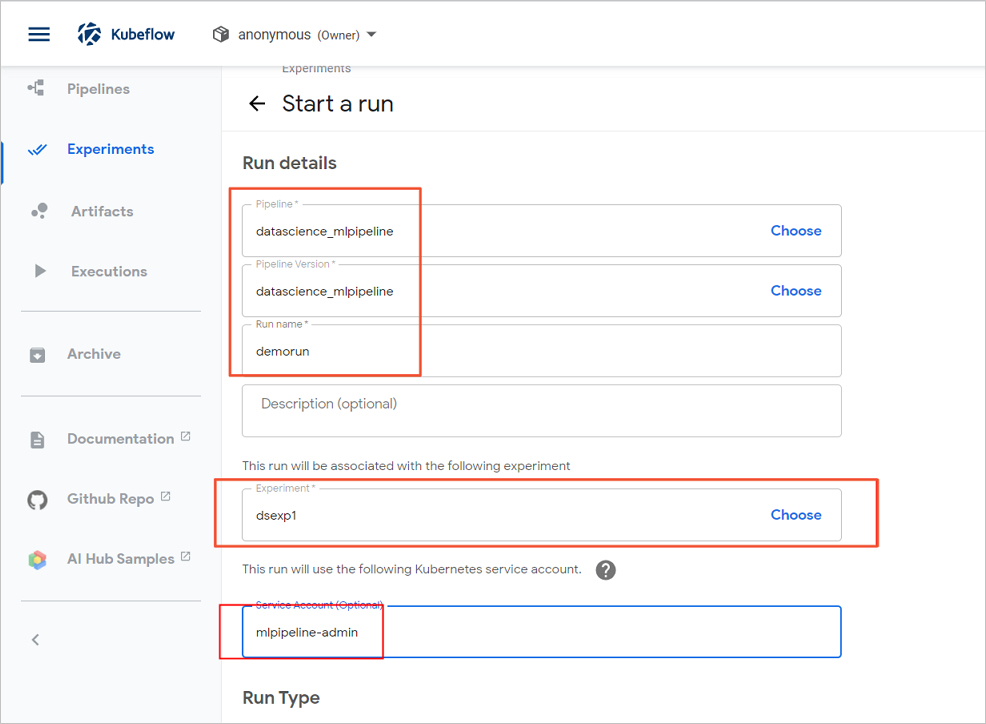
- [実行タイプ] で [定期] を選択します。
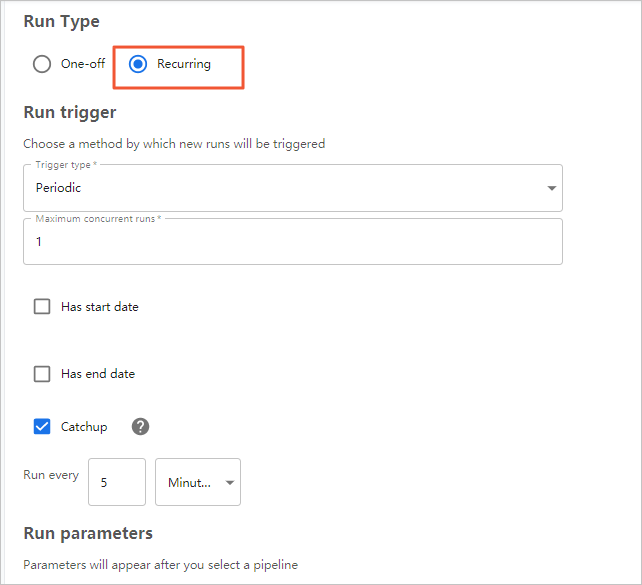
- 手順 4:パイプラインを構築する でオンプレミスマシンにダウンロードした***_mlpipeline.tar.gzファイルを選択します。
- [開始] をクリックします。
(オプション) 手順 7:パイプラインの状態を確認する
[実験] ページでパイプラインの状態を確認できます。 次の図は、モデルの例を示しています。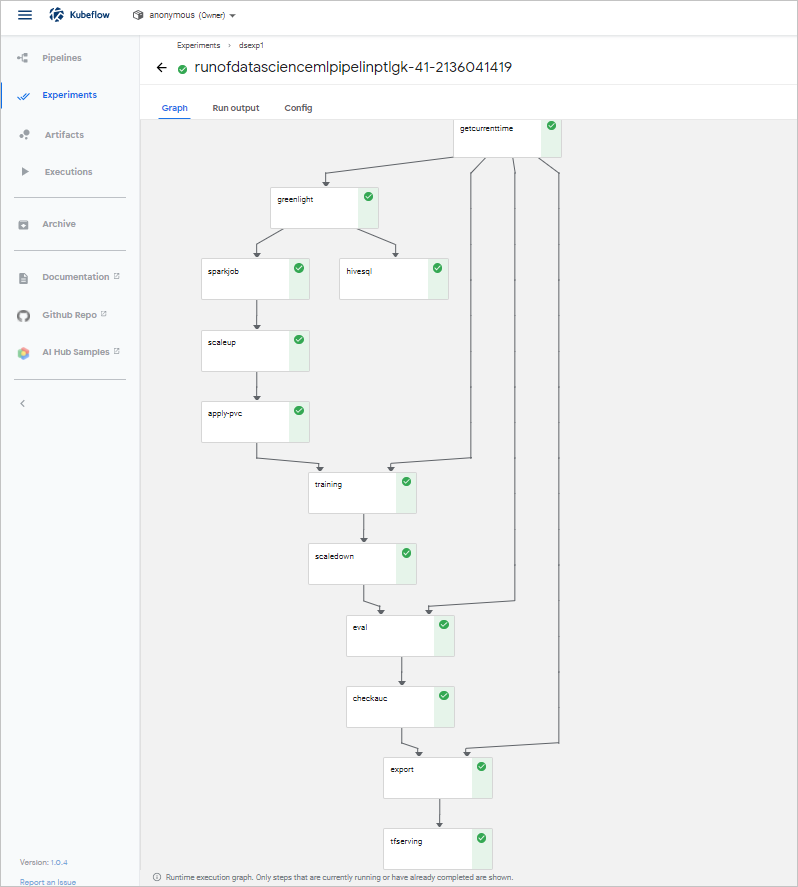
手順 8:モデル予測を実行する
- (推奨) HTTPリクエストメソッドを使用する
このメソッドでは、すべての開発言語がサポートされています。 predict_rest.sh ファイルには、予測コードが含まれています。
次のコマンドを実行して、モデル予測を実行します。重要 コマンドでは、defaultはデフォルトの名前空間を示します。easyrec-tfservingは、Servingサービスのデプロイに使用されるデフォルト名です。 ビジネス要件に基づいて設定を変更できます。!/bin/sh curl -X POST http://127.0.0.1:31380/seldon/default/easyrec-tfserving/api/v1.0/predictions -H 'Content-Type: application/json' -d ' { "jsonData": { "inputs": { "app_category":["10","10"], "app_domain":["1005","1005"], "app_id":["0","0"], "banner_pos":["85f751fd","4bf5bbe2"], "c1":["c4e18dd6","6b560cc1"], "c14":["50e219e0","28905ebd"], "c15":["0e8e4642","ecad2386"], "c16":["b408d42a","7801e8d9"], "c17":["09481d60","07d7df22"], "c18":["a99f214a","a99f214a"], "c19":["5deb445a","447d4613"], "c20":["f4fffcd0","cdf6ea96"], "c21":["1","1"], "device_conn_type":["0","0"], "device_id":["2098","2373"], "device_ip":["32","32"], "device_model":["5","5"], "device_type":["238","272"], "hour":["0","3"], "site_category":["56","5"], "site_domain":["0","0"], "site_id":["5","3"] } } }'次の出力が返されます。{"jsonData":{"outputs":{"logits":[-7.20718098,-4.15874624],"probs":[0.000740694755,0.0153866885]}},"meta":{}} - Seldon Coreを使用する次のコマンドを実行して、RESTプロトコルでモデル予測を実行します。
python3.7 predict_rest.py次の出力が返されます。Response: {'jsonData': {'outputs': {'logits': [-2.66068792, 0.691401482], 'probs': [0.0653333142, 0.66627866]}}, 'meta': {}}説明 予測コードの詳細については、predict_rest.py ファイルをご参照ください。
フィードバック
データサイエンスクラスタの使用中に質問がある場合は、テクニカルサポートにお問い合わせください。 また、32497587 番のDingTalkグループに参加して、フィードバックやコミュニケーションを行うこともできます。