このトピックでは、Prometheus エージェントによって収集されるメトリクスの数とCPUおよびメモリリソースの関係について説明します。 また、リソースの割り当てに関する提案事項についても説明します。
Prometheus エージェントに対するストレステストレポート
単一のエージェントによって収集されるメトリクスの数 | CPU | メモリ |
100 万 | 0.95 コア | 1.09483 GB |
110 万 | 1.11 コア | 1.16045 GB |
120 万 | 1.36 コア | 1.09452 GB |
130 万 | 1.66 コア | 1.15971 GB |
140 万 | 1.29 コア | 1.09465 GB |
150 万 | 1.50 コア | 1.15977 GB |
160 万 | 1.39 コア | 1.15971 GB |
170 万 | 1.64 コア | 1.1599 GB |
180 万 | 1.63 コア | 1.42331 GB |
Grafanaダッシュボードで、名前に Prometheus が含まれる各エージェントによって収集されたメトリクスの数を表示できます。
たとえば、下図は、以下の PromQL 文で収集されたメトリクスの数を示しています。
sum (scrape_samples_scraped) by (_ARMS_AGENT_ID)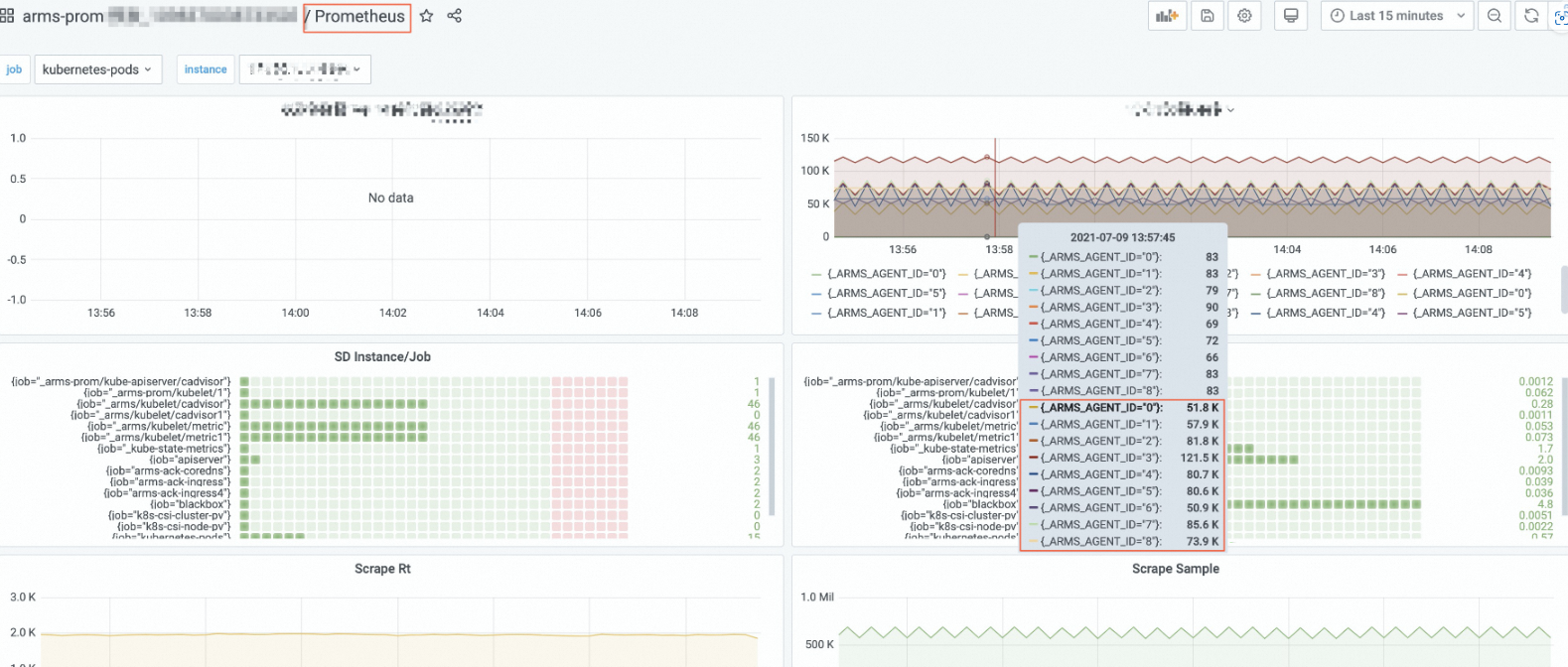
リソースの割り当てに関する提案事項
Prometheus エージェントに対するストレステストレポートに示されているように、100 万のメトリクスを収集するには、およそ 1 CPU コアと1 GB のメモリが必要です。 Prometheus エージェントが適切にデータを収集するための 推奨 CPU 使用率とメモリ使用率は、両方とも 50% です。
そのため、収集するメトリクスの数に基づいて、以下の方法で CPU およびメモリリソースを割り当てることを推奨します。
収集するメトリクスの数が 50 万 (Grafana ダッシュボードに500Kとして表示される) の場合、1 CPU コア、1 GB メモリを割り当てることを推奨します。
収集するメトリクスの数が 100 万の場合、2 CPU コア、2 GB メモリを割り当てることを推奨します。
収集するメトリクスの数が 200 万の場合、4 CPU コア、4 GB メモリを割り当てることを推奨します。
他の収集スケールの場合でも、同様の方法で CPU およびメモリリソースを割り当てます。
例:Grafana ダッシュボードでエージェントによって収集されたメトリクスの数が 100 万に達した場合、エージェントに対する CPU とメモリのリソースを2コア、2 GB にスケールアップすることを推奨します。