PolarDB for MySQL における書き込み負荷が高く、高い同時実行性を要するワークロードでは、InnoDB の B ツリーインデックスに対するロック動作によりスループットの上限に達することがあります。B ツリー同時実行制御最適化は、インデックスレベルでのシリアル化ボトルネックを解消し、すべての操作をページレベルでのロック競合に限定したまま並列実行可能にします。
仕組み
InnoDB では、テーブルデータがクラスター化インデックスで管理され、主キーインデックスおよびセカンダリインデックスの両方に B ツリーインデックス構造が使用されます。各物理ページ(B ツリーノード)には読み書きロックが設定されています。スレッドが構造変更操作(SMO:ノード分割やマージなど、複数の物理ページを一度に変更する操作)を実行する場合、InnoDB は一貫性を保つため、影響を受けるすべてのノードに対してロックを保持する必要があります。
このロック動作は、高い同時実行性において以下の 2 つのボトルネックを引き起こします:
同時実行可能な SMO が 1 つだけ: 同時に実行できる SMO は 1 つだけです。インデックスロックによりすべての構造変更操作がシリアル化されるため、スループットが制限されます。
ロック範囲が広い: デッドロックを回避するため、楽観的処理では走査パス上のすべてのノードに対して共有ロック(S ロック)を保持し、悲観的処理では変更が発生する可能性のあるすべてのノードに対して排他ロック(X ロック)を保持します。並行スレッド数が増えると、より多くのロック競合が発生し、最も高負荷なノードに集中します。
PolarDB for MySQL では、これらのボトルネックの両方に対応しています:
並列 SMO: すべての操作が B ツリーインデックスに同時にアクセス可能です。スレッド間の競合は、インデックスレベルではなくページレベルに限定されます。
ラッチ結合(Latch Coupling): すべての操作がラッチ結合を使用して、同時に保持するページロックを 1 つだけに制限することで、保持中のロック数および競合の持続時間を削減します。
前提条件
この最適化を有効化する前に、クラスターが以下のすべての条件を満たしていることを確認してください:
エディション: Enterprise Edition または Standard Edition
エンジンバージョン: MySQL 8.0.1(リビジョン 8.0.1.1.28 以降)または MySQL 8.0.2(リビジョン 8.0.2.2.17 以降)
アダプティブハッシュインデックス:
innodb_adaptive_hash_indexを OFF に設定する必要がありますインデックスタイプ: B ツリー形式の主キーインデックスおよびセカンダリインデックスのみがサポートされます。全文検索インデックスおよび空間インデックスはサポートされていません。
エンジンバージョンの確認方法については、「エンジンバージョンの照会」をご参照ください。
B ツリー同時実行制御最適化の有効化
この最適化の有効化または無効化を行うと、クラスターが自動的に再起動します。サービス中断時間が最大 1 分間発生する場合があります。回復時間はデータ量およびテーブル数に応じて異なります。ピーク時を避けた時間帯に実施し、アプリケーションがデータベースへ自動的に再接続するよう事前に設定してください。
PolarDB コンソール にログインします。
loose_innodb_polar_blink_treeを ON に設定します。パラメーター値の設定手順については、「クラスターおよびノードのパラメーターの指定」をご参照ください。
以下の表に、該当パラメーターの詳細を示します:
| パラメーター | 適用レベル | 説明 |
|---|---|---|
loose_innodb_polar_blink_tree | グローバル | B ツリー同時実行制御最適化を有効化または無効化します。有効な値: OFF(デフォルト)および ON。 |
パフォーマンスに関する考慮事項
得られる効果は、同時実行数およびワークロードのパターンによって異なります:
書き込み負荷が高く、高い同時実行性を要するワークロード(多数のスレッドが同一インデックス上で競合する場合)では、最も大きな改善が見られます。
中程度の同時実行性または読み取り負荷が中心のワークロードでは、インデックスレベルのロックがボトルネックとなることが稀であるため、効果は小さくなります。
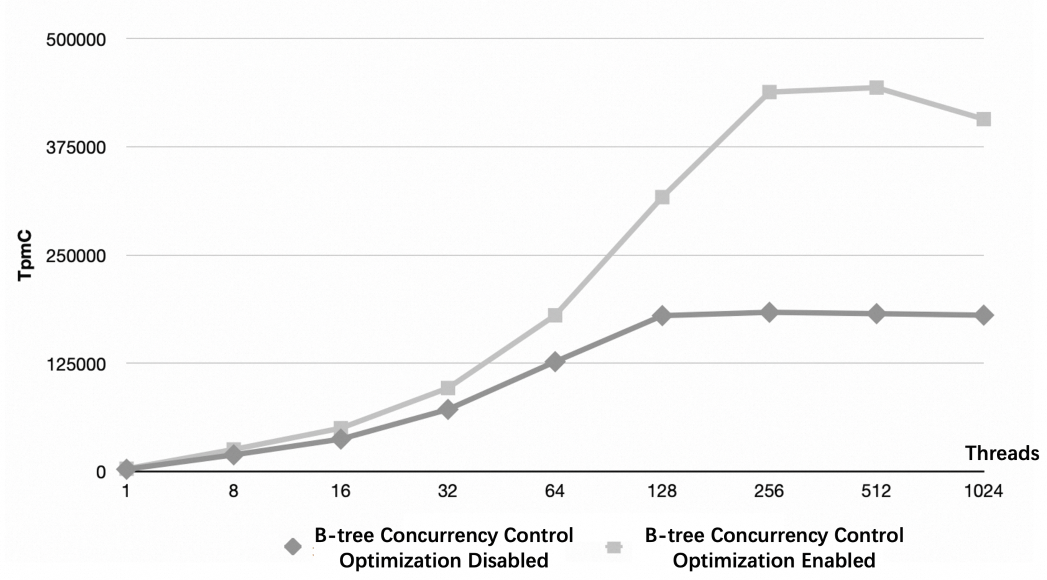
TPC-C ベンチマーク(1,000 ウェアハウス)に基づく評価結果は以下のとおりです:
最適化なしの場合: 128 スレッドの同時実行でピークパフォーマンスに達します。
最適化ありの場合: 256 スレッドの同時実行でピークパフォーマンスに達し、最適化なしのベースラインと比較して、読み取りおよび書き込みのスループットが 140 % 向上します。