このトピックでは、DataCache を使用して Alpaca-LoRa アプリケーションの構築を高速化する方法について説明します。Alpaca-LoRa アプリケーションを構築する場合、llama-7b-hf モデルデータと alpaca-lora-7b 重みデータを事前に DataCache からプルできます。Alpaca-LoRa アプリケーションに対応するエラスティックコンテナインスタンスを作成するときに、モデルデータと重みデータをインスタンスにマウントできます。これにより、データをプルする必要がなくなり、Apache-LoRa アプリケーションの起動が高速化されます。
背景情報
Alpaca-LoRa は、Low-Rank Adaptation (LoRA) 技術を使用して LLaMA (Large Language Model Meta AI) モデルで微調整された軽量言語モデルです。Alpaca-LoRa は、自然言語をシミュレートして対話やインタラクションを行い、ユーザーが入力した指示に基づいて異なるテキストを生成し、ユーザーがライティング、翻訳、コーディングなどのタスクを完了するのに役立ちます。
Alibaba Cloud は、サードパーティモデルの合法性、セキュリティ、または正確性を保証しません。Alibaba Cloud は、それによって引き起こされた損害について責任を負いません。
サードパーティモデルのユーザー契約、使用仕様、および関連する法律および規制を遵守する必要があります。お客様は、サードパーティモデルの使用について、お客様自身の責任において行うことに同意するものとします。
前提条件
使用する仮想プライベートクラウド (VPC) は、インターネット NAT ゲートウェイに関連付けられています。VPC 内のリソースまたは VPC 内の vSwitch に接続されているリソースがインターネットにアクセスできるように、SNAT エントリが NAT ゲートウェイに構成されています。
VPC がインターネット NAT ゲートウェイに関連付けられていない場合は、DataCache を作成してアプリケーションをデプロイするときに、VPC にエラスティック IP アドレス (EIP) を関連付ける必要があります。これにより、インターネットからデータをプルできます。
手順
Alpaca-LoRa イメージの作成
ビジネス要件に基づいてイメージを作成します。
alpaca-lora にアクセスし、リポジトリをオンプレミスマシンにクローンします。
リポジトリ内の requirements.txt と Dockerfile を変更します。
Dockerfile を使用してイメージをビルドします。
イメージをイメージリポジトリにプッシュします。
DataCache の作成
Hugging Face にアクセスし、モデルの ID を取得します。
この例では、次のモデルを使用します。Hugging Face でモデルを見つけ、モデルの詳細ページの上部にあるモデルの ID をコピーします。
decapoda-research/llama-7b-hf
tloen/alpaca-lora-7b
DataCache を作成します。
llama-7b-hf の DataCache を作成します。
次の例は、CreateDataCache API オペレーションを呼び出して DataCache を作成する場合に使用されるパラメータを示しています。llama-7b-hf モデルデータは Hugging Face からプルされ、test という名前のバケットの
/model/llama-7b-hfディレクトリに保存されます。DataCache には llama-7b-hf という名前が付けられ、1 日間保持されます。重要SDK を使用して DataCache を作成する場合、DataSource.Options の各パラメータにパラメータ名の長さをプレフィックスする必要はありません。たとえば、
#10#repoSourceの代わりにrepoSourceと記述します。#6#repoIdの代わりにrepoIdと記述します。{ "RegionId": "cn-beijing", "SecurityGroupId": "sg-2ze63v3jtm8e6syi****", "VSwitchId": "vsw-2ze94pjtfuj9vaymf****", "Bucket": "test", "Path": "/model/llama-7b-hf", "Name": "llama-7b-hf", "DataSource": { "Type": "URL", "Options": { "#10#repoSource": "HuggingFace/Model", "#6#repoId": "decapoda-research/llama-7b-hf" } }, "RetentionDays": 1 }alpaca-lora-7b の DataCache を作成します。
次の例は、CreateDataCache API オペレーションを呼び出して DataCache を作成する場合に使用されるパラメータを示しています。alpaca-lora-7b モデルデータは Hugging Face からプルされ、test という名前のバケットの
/model/alpaca-lora-7bディレクトリに保存されます。DataCache には alpaca-lora-7b という名前が付けられ、1 日間保持されます。重要SDK を使用して DataCache を作成する場合、DataSource.Options の各パラメータにパラメータ名の長さをプレフィックスする必要はありません。たとえば、
#10#repoSourceの代わりにrepoSourceと記述します。#6#repoIdの代わりにrepoIdと記述します。{ "RegionId": "cn-beijing", "SecurityGroupId": "sg-2ze63v3jtm8e6syi****", "VSwitchId": "vsw-2ze94pjtfuj9vaymf****", "Bucket": "test", "Path": "/model/alpaca-lora-7b", "Name": "alpaca-lora-7b", "DataSource": { "Type": "URL", "Options": { "#10#repoSource": "HuggingFace/Model", "#6#repoId": "tloen/alpaca-lora-7b" } }, "RetentionDays": 1 }
DataCache のステータスをクエリします。
返された DataCache ID を使用して DescribeDataCaches API オペレーションを呼び出し、DataCache の情報をクエリします。DataCaches.Status で示される DataCache のステータスが Available の場合、DataCache は使用できる状態です。
Alpaca-lora アプリケーションのデプロイ
DataCache を使用してエラスティックコンテナインスタンスを作成し、インスタンスに Alpaca-lora アプリケーションをデプロイします。
次の例は、CreateContainerGroup API オペレーションを呼び出してエラスティックコンテナインスタンスを作成する場合に使用されるパラメータを示しています。インスタンスには、20 GiB の追加の一時ストレージスペースがあり、llama-7b-hf および alpaca-lora-7b モデルデータがマウントされています。インスタンス内のコンテナは、準備された Alpaca-lora イメージを使用します。コンテナ内のモデルデータのマウントパスは、それぞれ
/data/llama-7b-hfと/data/alpaca-lora-7bです。コンテナが起動した後、コンテナはpython3.10 generate.py --load_8bit --base_model /data/llama-7b-hf --lora_weights /data/alpaca-lora-7bコマンドを実行します。{ "RegionId": "cn-beijing", "SecurityGroupId": "sg-2ze63v3jtm8e6syi****", "VSwitchId": "vsw-2ze94pjtfuj9vaymf****", "ContainerGroupName": "alpacalora", "DataCacheBucket": "test", "EphemeralStorage": 20, "Container": [ { "Name": "alpacalora", "Image": "registry-vpc.cn-beijing.aliyuncs.com/******/***-registry:v1.0", "Command": [ "/bin/sh", "-c" ], "Arg": [ "python3.10 generate.py --load_8bit --base_model /data/llama-7b-hf --lora_weights /data/alpaca-lora-7b" ], "Cpu": 16, "Memory": 64, "Port": [ { "Port": 7860, "Protocol": "TCP" } ], "VolumeMount": [ { "Name": "llama-model", "MountPath": "/data/llama-7b-hf" }, { "MountPath": "/data/alpaca-lora-7b", "Name": "alpacalora-weight" } ] } ], "Volume": [ { "Type": "HostPathVolume", "HostPathVolume.Path": "/model/llama-7b-hf", "Name": "llama-model" }, { "Type": "HostPathVolume", "HostPathVolume.Path": "/model/alpaca-lora-7b", "Name": "alpacalora-weight" } ] }アプリケーションがデプロイされているかどうかを確認します。
返されたインスタンス ID を使用して DescribeContainerGroupStatus API オペレーションを呼び出し、インスタンスとコンテナのステータスをクエリします。Status で示されるインスタンスのステータスと ContainerStatuses.State で示されるコンテナのステータスが Running の場合、インスタンスは作成され、コンテナは実行中です。
アプリケーションへのインターネットアクセスを開きます。
エラスティックコンテナインスタンスが存在する VPC が NAT ゲートウェイに関連付けられている場合は、DNAT エントリを作成して、インスタンスへのインターネットアクセスを許可する必要があります。詳細については、DNAT エントリの作成と管理 を参照してください。
説明VPC が NAT ゲートウェイに関連付けられていない場合は、エラスティックコンテナインスタンスを作成するときに、VPC に EIP を関連付ける必要があります。この場合は、この手順をスキップします。
次の例は、DNAT エントリを作成するときにパラメータを構成する方法を示しています。
パブリック IP アドレスの選択: NAT ゲートウェイに関連付けられている EIP を選択します。
プライベート IP アドレスの選択: Alpaca-lora アプリケーションがデプロイされているエラスティックコンテナインスタンスの IP アドレスを選択します。
ポート設定: 特定のポートを選択します。次に、パブリックポートを 80、プライベートポートを 7860、プロトコルタイプを TCP に設定します。
モデルのテスト
エラスティックコンテナインスタンスが属するセキュリティグループにインバウンドルールを追加して、アプリケーションの外部ポートを開きます。
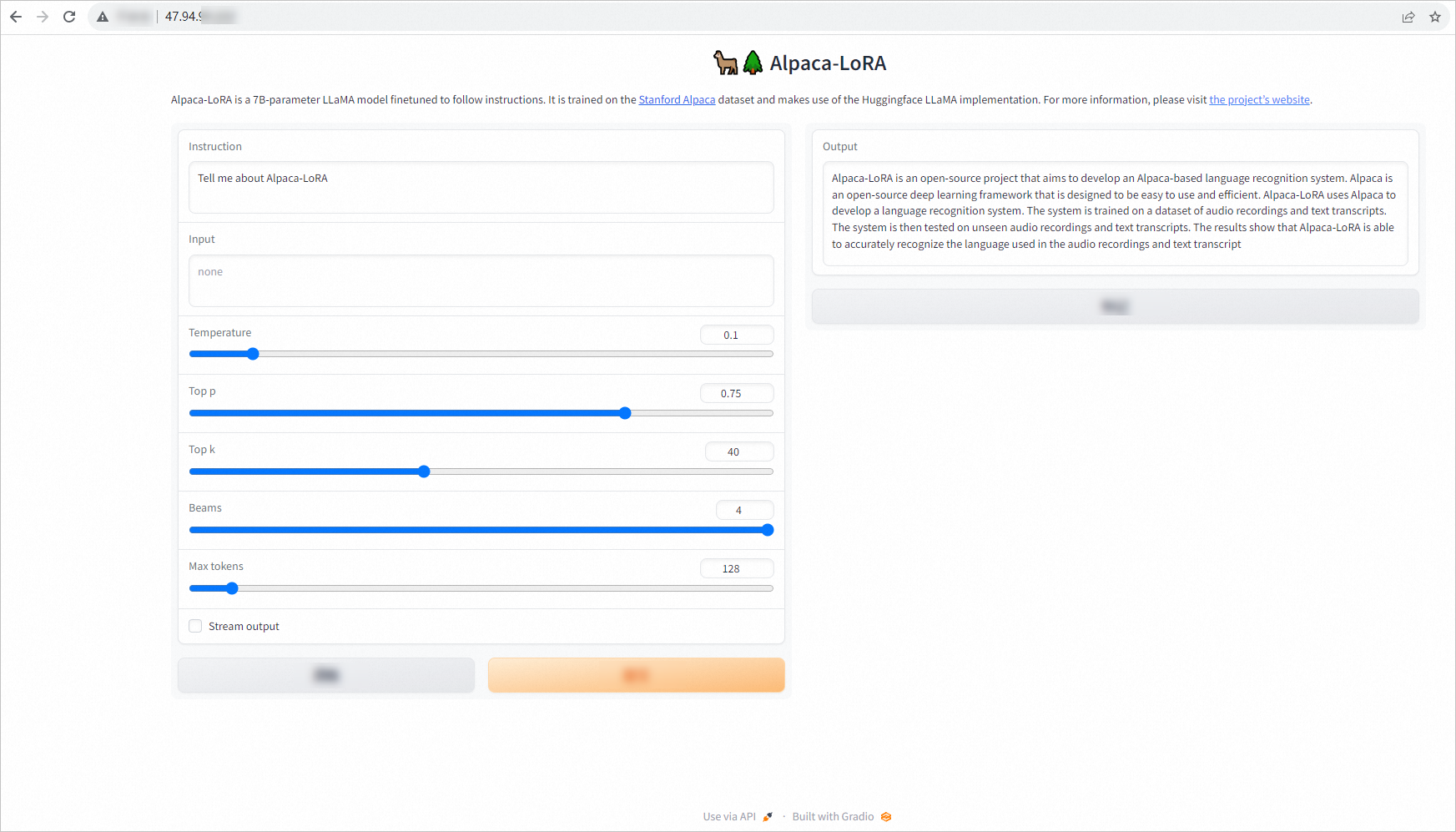
ブラウザを開いて Alpaca-LoRa アプリケーションにアクセスします。
DNAT を構成した場合は、DNAT エントリで構成したパブリック IP アドレスとパブリックポートを入力します。例:
47.94.XX.XX:80。説明エラスティックコンテナインスタンスに EIP が関連付けられている場合は、EIP とコンテナの外部ポートを入力します。例:
47.94.XX.XX:7860。テキストトランスクリプトを入力してモデルをテストします。
例: