低ストレージコスト、便利な O&M、および柔軟なスケーリングを実現するために、Lindorm を ApsaraDB for RDS と共に使用するソリューションを使用できます。このトピックでは、ソリューションのアーキテクチャと利点について説明します。
このソリューションでは、2023 年 3 月 10 日より前に購入された Lindorm Tunnel Service(LTS)インスタンスのみを使用できます。
背景情報
モバイルインターネットのシナリオでは、毎日大量のビジネスデータが生成されます。ビジネスの成長に伴い、生成されるデータ量は大幅に増加します。同時に、履歴データが照会される頻度は時間の経過とともに減少します。すべてのデータをリレーショナルデータベースに保存すると、さまざまな問題が発生する可能性があります。
課題
ストレージコストの増加: ストレージコストはデータ量に比例します。データ量の指数関数的な増加は、ストレージコストの指数関数的な増加を引き起こします。
クエリパフォーマンスの低下: 単一インスタンスに 1 TB を超えるデータが保存されている場合、インスタンスのクエリパフォーマンスが低下します。
複雑な O&M: データ量の増加によって引き起こされるパフォーマンスの低下を軽減するためにデータベースとテーブルをシャーディングすると、O&M コストと開発コストが増加します。
要件
低ストレージコスト: 履歴データのストレージコストは、オンラインデータのストレージコストの 10 分の 1 です。
自動スケーリング: データベースのコンピューティング機能とストレージ機能は自動的にスケールアウトできるため、シャーディングされたデータベースとテーブルでの O&M の難しさが解消されます。
スキーマ変更の低コスト: データベースのスキーマを迅速に変更できるか、データベースが動的スキーマをサポートしています。これにより、アーカイブデータベースのスキーマの変更に必要な期間が短縮されます。
コード変更の低コスト: SQL ステートメントを使用してデータのクエリを実行できます。
リアルタイムクエリ: 請求書やチャットレコードが照会されるシナリオでは、履歴データの照会の応答時間(RT)は、リアルタイムデータの照会の RT と同様です。
データ分析: 履歴データは低い頻度で照会されます。シナリオによっては、完全なデータをマイニングおよび分析する必要があります。たとえば、Alipay の年間請求書は完全なデータに基づいて生成されます。
Lindorm は、低ストレージコスト、便利な O&M、柔軟なスケーリング、安定したパフォーマンスなどのさまざまな要件を満たすことができます。 Lindorm をリレーショナルデータベースと共に使用して、低コストで最適なリアルタイムアーカイブデータベースサービスを提供できます。
アーキテクチャ
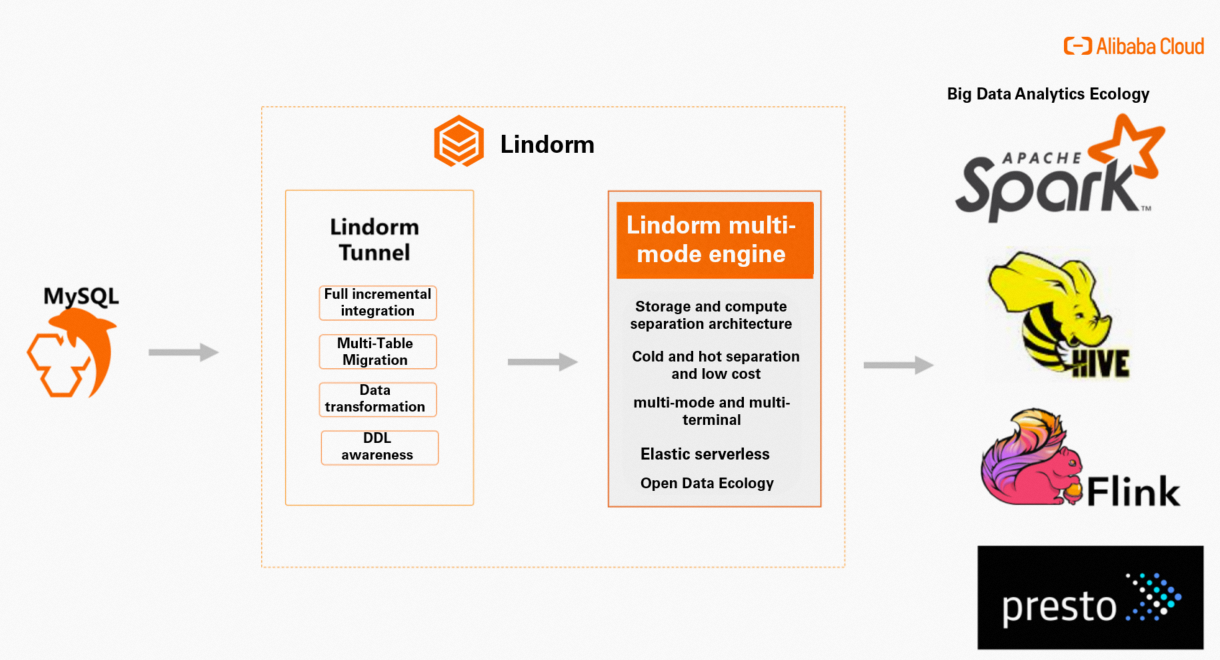
LTS を使用すると、ApsaraDB RDS for MySQL データベースなどのリレーショナルデータベースから完全データと増分データをインポートできます。 LTS はまた、企業がデータ移行を実行するための機能も提供します。たとえば、テーブル間でデータを移行したり、移行中にデータを変更したり、DDL ステートメントを実行したりできます。 LTS は、効率的な方法でデータを移行するのに役立ちます。
Lindorm は、0.019 米ドル/GB/月という低価格で大量のデータを保存できます。また、自動スケーリング機能を提供し、従量課金制をサポートしています。 Lindorm を使用すると、さまざまなエンジンを使用してマルチモデルデータを処理できます。これは、さまざまなシナリオでのデータストレージ要件を満たします。 Lindorm はまた、Apache Spark、Apache Hive、Apache Flink、Presto などのオープンソースの分析サービスにもシームレスに接続できるため、複雑なデータ分析の要件を満たし、データの価値を探ることができます。
利点
使いやすさ
Lindorm を使用すると、数分でデータ移行タスクを視覚的に構成できます。
Lindorm は、完全データと増分データの移行のための統合ソリューションを提供します。これにより、データ移行コストを最小限に抑えることができます。
Lindorm は、データ移行のためのさまざまな機能を提供します。たとえば、テーブル間でデータを移行したり、移行中にデータを変更したりできます。また、テーブルをマージしたり、列の組み合わせを効率的に変更したりすることもできます。
Lindorm は、包括的な監視およびアラート機能を提供し、データ移行タスクの安定性を確保するのに役立ちます。
費用対効果
Lindorm は、0.12 人民元/GB/月という低価格でストレージ用の容量最適化ディスクを提供します。組み込みのバッファレイヤーはクエリを高速化し、リアルタイムクエリの パフォーマンス を確保できます。このように、Lindorm はアーカイブデータベースに最適なソリューションを提供します。
Lindorm ワイドテーブルエンジン(LindormTable)は、さまざまなディメンションに基づいてスループットとレイテンシを最適化し、パフォーマンスを向上させます。 LindormTable のベンチマーク パフォーマンス は、オープンソースの HBase サービスのベンチマーク パフォーマンス の 7 倍です。 詳細については、「テスト結果」をご参照ください。 Lindorm 時系列エンジン(LindormTSDB)は、さまざまな革新的なアーキテクチャ設計を統合して、高 パフォーマンス を提供します。 LimdormTSDB のベンチマーク パフォーマンス は、中国情報通信研究院が発表したリストで 1 位にランクされています。
Lindorm はホットデータとコールドデータの分離をサポートしています。監視データ、履歴チャットデータ、取引請求書のデータなど、ホットデータが時間の経過とともにコールドデータに変換されるシナリオでは、Lindorm はコールドデータを自動的に識別し、コールドデータをホットデータから分離してから、コールドデータをコールドストレージにアーカイブします。これにより、ホットデータは高 パフォーマンス ストレージメディアに保存され、コールドデータは低コストストレージメディアに保存されます。 2 種類のストレージメディアの価格差は最大 10:1 になる可能性があります。コールドデータがホットデータから分離されているテーブルで読み取り操作または書き込み操作を実行するために、ビジネスアプリケーションのコードを変更する必要はありません。さらに、ホットデータに対して実行されるクエリが高速化され、クエリ パフォーマンス が向上します。
Lindorm は適応圧縮をサポートしています。システムは、データのタイプと特性に基づいて圧縮アルゴリズムを自動的に選択します。サポートされている圧縮アルゴリズムには、辞書エンコーディング、プレフィックスエンコーディング、デルタエンコーディング、エントロピーエンコーディングが含まれます。業界の一般的なアルゴリズムと比較して、Lindorm によって提供される適応圧縮機能は、圧縮率を 10 ~ 30% 向上させます。
自動スケーリングをサポートするクラウドネイティブアーキテクチャ
Lindorm はコンピューティングリソースとストレージリソースを分離します。これにより、コンピューティングリソースとストレージリソースを個別にスケーリングできます。これは、リソース使用率を最大化するのに役立ちます。
Lindorm Serverless はインスタントスケーリングを可能にし、従量課金制を使用します。 Lindorm Serverless は、マルチテナントデータ分離、インテリジェントスケジューリング、およびスケーリング可能なサービスとしてのインフラストラクチャ(IaaS)アーキテクチャに基づいて構築されています。 Lindorm Serverless は、ほとんどの企業の可用性要件を満たすサービスレベル契約(SLA)を提供します。 Lindorm Serverless はまた、容量管理のための O&M ワークロードを削減し、トラフィックの変動によって発生する安定性のリスクを排除します。
マルチモデル機能とデータ検索
Lindorm は、Apache HBase API、SQL 用 Apache Phoenix API、Cassandra Query Language(CQL)用 Cassandra API など、主要なオープンソース標準 API と互換性があります。これにより、人件費とリソースコストを削減できます。 Lindorm は、グローバルセカンダリインデックス、多次元クエリ、動的列、データの有効期限(TTL)機能など、さまざまな機能を提供します。 Lindorm はさまざまなシナリオに適しています。たとえば、Lindorm を使用して、メタデータ、注文データ、請求書、画像、チャットレコード、フィードストリーム、ログを保存できます。
Lindorm は、LindormSearch と呼ばれる検索エンジンサービスを提供します。これは、オープンソース標準 Solr API と互換性があります。 Lindorm インスタンスの LindormSearch をアクティブ化してから、LindormSearch を使用して全文検索、値の集計、複雑な多次元クエリを実行できます。 LindormSearch はデータクエリを高速化し、複雑なリアルタイムデータ分析のデータを取得するために使用できます。
ビッグデータエコシステムとの互換性
Lindorm は、ビッグデータ分析用のオープンソースエンジンと共に使用できます。サポートされているエンジンには、Apache Spark、Apache Hive、Apache Flink、Presto が含まれます。 Lindorm は、ビッグデータに対する複数タイプの操作をサポートしています。たとえば、API を呼び出して操作を実行したり、ファイルシステムからデータを照会したりできます。 Lindorm はまた、大量のデータを効率的に分析するのにも役立ちます。
一般的なシナリオ
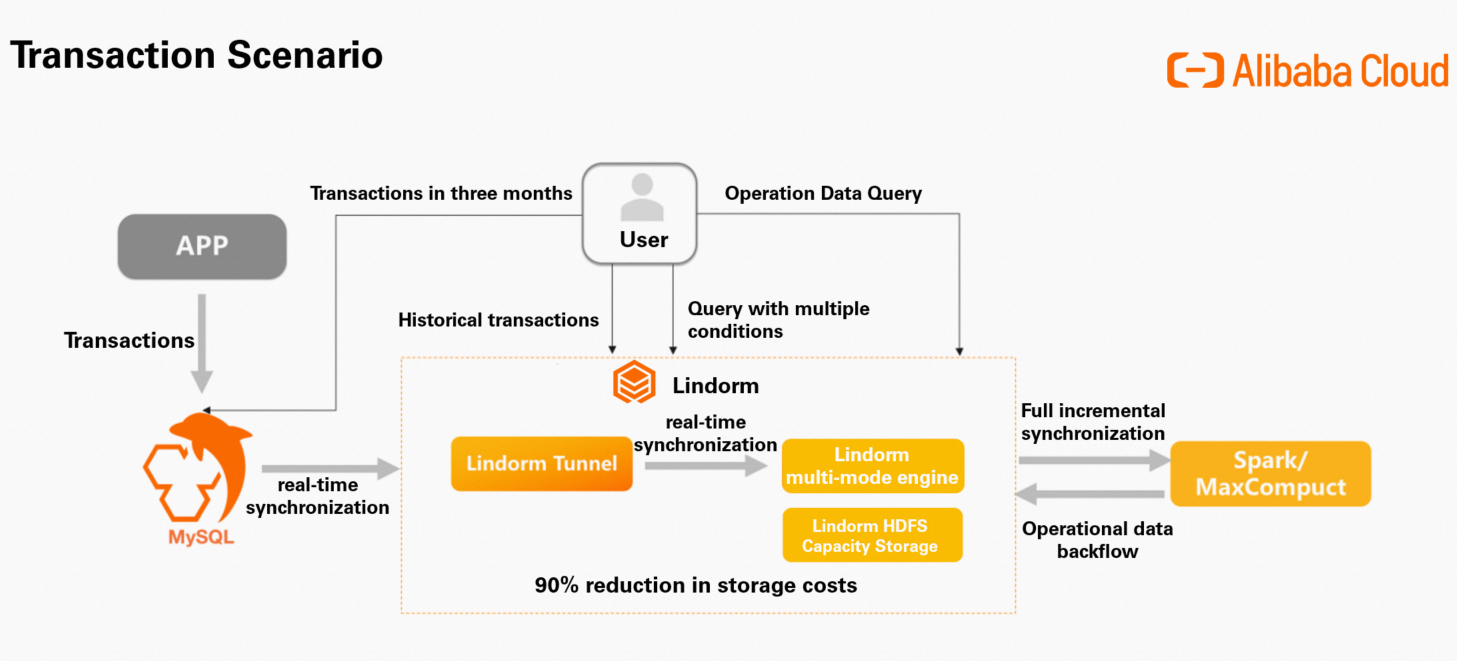
ビジネスアプリケーションは、トランザクションレコードのデータを MySQL データベースに書き込みます。 LTS は、MySQL データベースから Lindorm インスタンスにトランザクションデータをリアルタイムで同期します。 MySQL データベースは過去 3 か月間に生成されたトランザクションレコードのデータを保存し、容量最適化ディスクを使用する Lindorm インスタンスは 3 か月より前に生成された履歴トランザクションデータを保存します。これにより、ストレージコストが 90% 以上削減されます。
特定のシナリオでは、クエリを実行するときに複雑な条件を指定できます。たとえば、トランザクションに関する情報を照会する場合、トランザクションが生成された時点、顧客の場所、トランザクション価格、トランザクションに関する備考などのクエリ条件を組み合わせることができます。 LindormSearch を使用して、全文検索、値の集計、複雑な多次元クエリを実行できます。ビジネスアプリケーションのコードを変更することなく、ビジネス要件に基づいてこれらの操作を実行できます。
LTS は、請求書のデータを Lindorm から Apache Spark や MaxCompute などのオフラインコンピューティングプラットフォームに同期して計算できます。生成された運用レポートは、ビジネス要件に基づいて分析されます。その後、データはリアルタイムクエリのために Lindorm に返されます。