このトピックでは、TPC-H ベンチマークを使用して、PolarDB for MySQL 8.0.1 および 8.0.2 クラスタ版 クラスタのオンライン分析処理 (OLAP) パフォーマンスをテストする方法について説明します。このトピックの手順に従って、データベースのパフォーマンスをテストできます。
パラレルクエリ
PolarDB for MySQL 8.0 クラスタ版 は、クエリの応答時間を短縮するためのパラレルクエリ機能を提供します。この機能は、クエリ対象のデータ量が指定されたしきい値を超えると自動的に有効になります。詳細については、「概要」をご参照ください。
PolarDB for MySQL 8.0.1 クラスタのストレージレイヤーでは、データシャードは異なるスレッドに分散されます。複数のスレッドが並列計算を実行し、結果をリーダー スレッドに順番に返します。次に、リーダー スレッドが結果をマージし、最終結果をユーザーに返します。これにより、クエリ効率が向上します。
PolarDB for MySQL 8.0.2 では、パラレルクエリの線形加速機能が新たなレベルに引き上げられ、多段階並列計算機能が提供されます。コストベースの最適化により、より柔軟な並列実行プランが可能になり、PolarDB for MySQL 8.0.1 のパラレルクエリで発生する可能性のある単一リーダー スレッドのパフォーマンス ボトルネックとワーカーの負荷の不均衡が解消されます。具体的には、データシャードは引き続きストレージレイヤーで異なるスレッドに分散されます。複数のスレッドが並列計算を実行し、データシャードを次のフェーズの並列ワーカー グループに分散します。次に、リーダー スレッドが計算結果をマージし、最終結果をユーザーに返します。これにより、並列実行機能が大幅に向上します。
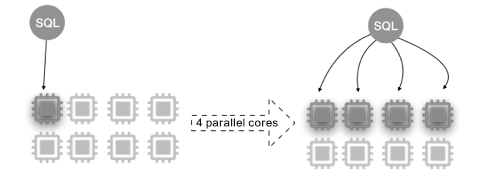
パラレルクエリは、マルチコア CPU の並列処理機能に基づいて実現されます。次の図は、8 コア 32 GB メモリのクラスタでの並列処理を示しています。
次の表は、PolarDB 8.0.1 および 8.0.2 クラスタの OLAP テスト用に設定されたパラレルクエリ パラメーターの値を示しています。パラレルクエリ パラメーターの構成方法の詳細については、「クラスタ パラメーターとノード パラメーターの構成」をご参照ください。テストツール、メソッド、および結果の詳細については、「パラレルクエリのパフォーマンステスト」および「テスト結果」をご参照ください。
8.0.1
パラメーター
デフォルト値
有効な値 (オプション 1)
loose_parallel_degree_policy
REPLICA_AUTO
TYPICAL
loose_max_parallel_degree
0
16
8.0.2
パラメーター
デフォルト値
有効な値 (オプション 1)
loose_parallel_degree_policy
REPLICA_AUTO
TYPICAL
loose_parallel_query_switch
''
'force_run_using_planning_dop=on'
loose_optimizer_switch
''
'hash_join_cost_based=off'
loose_max_parallel_degree
0
16
loose_parallel_degree_policy が TYPICAL に設定されている場合、PolarDB はデータベースのリソース使用量 (CPU 使用率など) を無視し、並列処理の次数 (DOP) を loose_max_parallel_degree パラメーターの値に設定します。
テスト結果
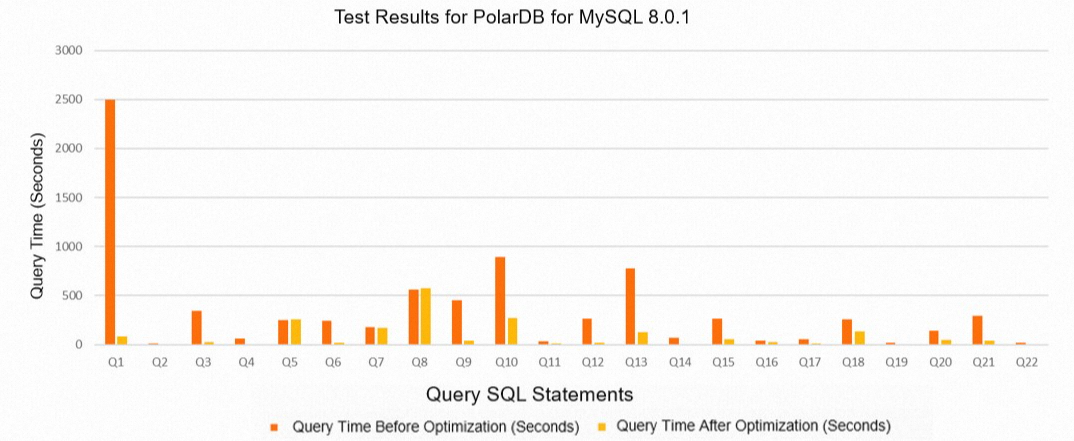
次の表に、PolarDB 8.0.1 のテスト結果を示します。
クエリ
デフォルト値の期間 (単位: 秒)
有効な値 (オプション 1) の期間 (単位: 秒)
Q1
2495.05
86.63
Q2
13.18
1.46
Q3
345.56
28.67
Q4
63.78
6.26
Q5
251.48
258.55
Q6
241.7
16.4
Q7
174.91
171.85
Q8
560.82
572.63
Q9
450.68
42.17
Q10
895.75
270.29
Q11
30.03
11.6
Q12
266.14
17.65
Q13
780.74
127.1
Q14
72.04
7.57
Q15
261.77
56.55
Q16
40.69
24.29
Q17
57.75
13.04
Q18
257.66
136.79
Q19
19.17
1.52
Q20
143.97
49.72
Q21
293.99
37.79
Q22
18.81
2.15
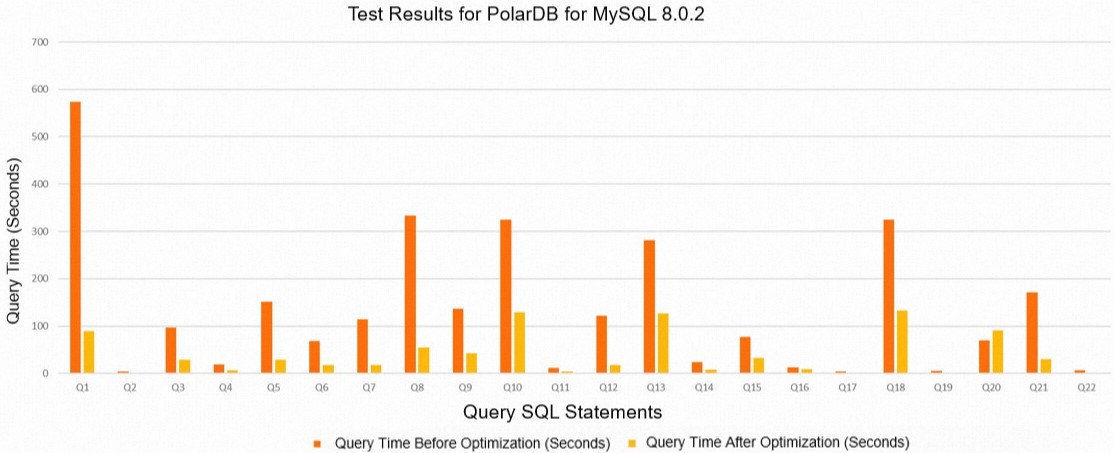
次の表に、PolarDB 8.0.2 のテスト結果を示します。
クエリ
デフォルト値の期間 (単位: 秒)
有効な値 (オプション 1) の期間 (単位: 秒)
Q1
573.34
89.65
Q2
3.62
0.66
Q3
96.89
28.52
Q4
18.66
6.41
Q5
150.93
28.93
Q6
68.13
17.13
Q7
114.56
17.39
Q8
333.36
54.32
Q9
136.26
42.15
Q10
325.19
128.55
Q11
11.49
4.53
Q12
121.68
17.54
Q13
281.1
126.2
Q14
23.34
7.59
Q15
77.22
33.02
Q16
12.15
8.96
Q17
4.51
1.13
Q18
325.05
133.07
Q19
5.37
1.5
Q20
70.31
90.75
Q21
171.81
29.87
Q22
6.05
2.16