このトピックでは、データ管理 (DMS) が提供する Jupyter Notebook を使用してデータをクエリおよび分析する方法について説明します。Notebook は、コード、テキスト、およびチャートを統合したインタラクティブなページです。 Notebook を使用すると、他のユーザーと簡単に情報を共有できます。
Notebook UI

 : Notebook で編集したコンテンツを保存します。
: Notebook で編集したコンテンツを保存します。 : 現在のセルの上にセルを挿入します。
: 現在のセルの上にセルを挿入します。 : 選択したセルを削除します。
: 選択したセルを削除します。 : 選択したセルを切り取ります。
: 選択したセルを切り取ります。 : 選択したセルをコピーします。
: 選択したセルをコピーします。 : コピーしたコンテンツを選択したセルに貼り付けます。
: コピーしたコンテンツを選択したセルに貼り付けます。 : 選択したセルのコンテンツを実行します。
: 選択したセルのコンテンツを実行します。 : カーネルを停止します。
: カーネルを停止します。 : カーネルを再起動します。
: カーネルを再起動します。 : カーネルを再起動し、Notebook を再度実行します。
: カーネルを再起動し、Notebook を再度実行します。 : 選択したセルの属性を変更します。オプションの属性には、コード、SQL、Markdown、および Raw が含まれます。
: 選択したセルの属性を変更します。オプションの属性には、コード、SQL、Markdown、および Raw が含まれます。 : 会話型データクエリまたは分析用の Copilot ペインを開きます。
: 会話型データクエリまたは分析用の Copilot ペインを開きます。
DMS Jupyter Notebook でサポートされている機能
オープンソースの Jupyter Notebook と互換性のある DMS Jupyter Notebook は、SQL クエリと可視化のための拡張機能を提供します。このセクションでは、DMS Jupyter Notebook でサポートされている機能について説明します。
IPython カーネル
pip を使用して拡張パッケージをインストールします。インターネット経由でこのカーネルを使用する Notebook にアクセスし、基本的にオープンソースの Jupyter Notebook を使用するのと同じ方法で Notebook を使用できます。
Spark 構文を使用して、Notebook 内のテーブルデータをクエリできます。サンプルコード:
構文 1:
df = spark.sql("select * from customer limit 10").show();構文 2:
%%spark_sql select * from customer limit 10;構文 3:
セルで、 を選択し、SQL 文を入力します。

CREATE TABLE IF NOT EXISTS 'default'.'select_2' AS SELECT 2;説明デフォルトでは、Spark SQL セルはページに最大 3,000 行を表示します。表示される行数を調整するには、セルに次のコードを入力して、環境変数 DMS_SPARK_SQL_DEFAULT_LIMIT を変更します。
os.environ['DMS_SPARK_SQL_DEFAULT_LIMIT'] = '3000';
Notebook のツールバーで、セルの属性をコードから SQL に変更できます。
SQL セルは、論理データウェアハウスと同じ構文を使用します。 SQL セルでデータベースを横断してデータをクエリし、リアルタイムでデータを分析できます。必要な権限は、DMS の詳細な権限と同じです。
SQL セルと Python セルでは、
${変数名}の形式で変数を参照し、変数名をカスタマイズし、変数の型を表示できます。次のセクションでは、Notebook で変数を参照および生成する方法について説明します。変数を参照する
${IPython 変数名} 形式で SQL 文内の IPython 変数を参照できます。

変数を生成する
SQL セルの結果セットを IPython の変数として直接参照できます。変数名は結果セットの左下隅に表示され、変数の型は pandas.core.frame.DataFrame です。変数名をクリックして名前をカスタマイズできます。

アイコンをクリックすることで、SQL クエリの結果セットをテーブルまたはチャートで視覚化できます。
PySpark カーネル
デフォルトでは、DMS Jupyter Notebook は AnalyticDB Spark を使用します。 Notebook でオープンソースの Spark を使用することもできます。
Spark Magic を使用すると、マジックコマンド %%help を実行して、サポートされているコマンドを表示できます。
Spark Magic は Jupyter Notebook の拡張機能です。
AnalyticDB Spark を使用する
Data Lakehouse Edition の AnalyticDB クラスタを購入し、リソースグループを作成し、データベースアカウントを作成した後、次の表に示すコマンドを使用できます。
コマンド | 説明 |
| AnalyticDB Spark の構成を表示します。 |
| AnalyticDB Spark に SQL 文を送信します。 |
C-Store テーブルを作成、読み取り、および書き込みます。詳細については、「内部テーブルの読み取りと書き込み」をご参照ください。 | |
| Python コードを AnalyticDB Spark に送信します。 |
AnalyticDB Spark は新しいセッションを 20 分間保持し、有効期限が切れるとセッションを削除します。カーネルを再起動して別のセッションを作成できます。
ファイルのアップロードとダウンロード
ossutil を使用してデータセットをアップロードおよびダウンロードできます。詳細については、「ossutil の構成」をご参照ください。
手順
Notebook を作成します。
 タブで、
タブで、 をクリックし、[notebook] を選択します。
をクリックし、[notebook] を選択します。
テキストフィールドまたはコードエディタで、SQL、コード、Markdown、または Raw 構文を使用してコンテンツを入力します。
生成された SQL 文が正しいことを確認した後、SQL 文を実行し、生成された結果セットを表示します。
SQL 文セクションの右上隅にある [クエリを実行] をクリックします。
SQL 文は左側のドキュメントに自動的に挿入されます。生成された結果セットは SQL 文の下に表示されます。
結果セットをテーブルに表示します。
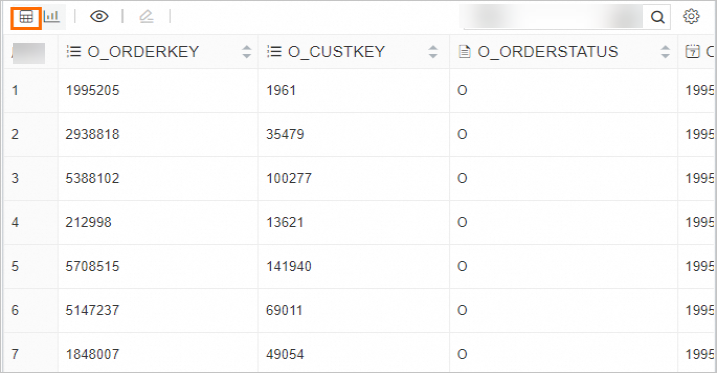
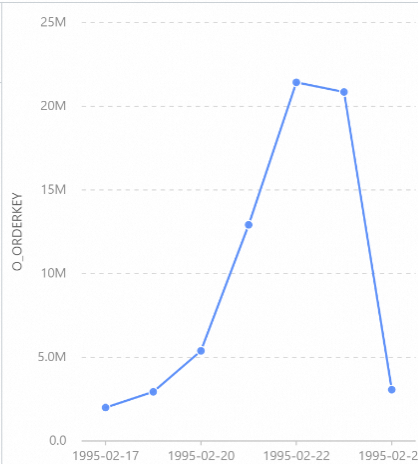
結果セットをチャートに表示します。
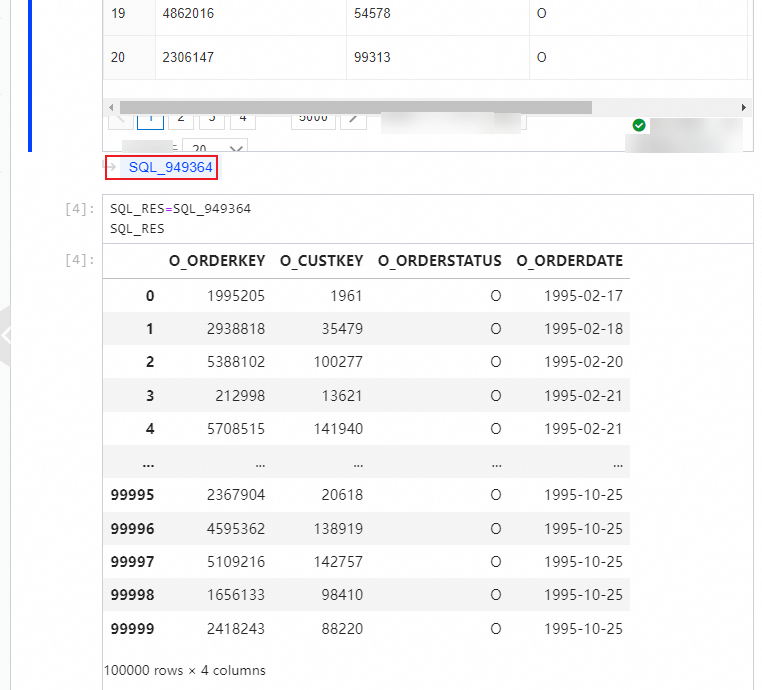
SQL 文が実行された後、変数の形式で他の SQL セル内の結果セットを参照します。変数の名前をカスタマイズできます。
データの変化トレンドを予測します。
機械学習用の Python パッケージをインストールするためのコマンドを入力し、[実行] アイコンをクリックしてパッケージをインストールします。次の図はサンプルコードを示しています。

パッケージがインストールされた後、Python コードを実行してデータの変化トレンドを予測し、変化を視覚的に表示します。
次のステップ
FAQ
Q: Notebook で生成されたドキュメントはどのユーザーが表示できますか?
A: ワークスペースのメンバーである同じテナントのユーザーのみが、Notebook で生成されたドキュメントを表示できます。ユーザーがワークスペースを所有するテナントに属していない場合は、ユーザーをテナントに追加し、ユーザーをワークスペースのメンバーとして追加します。