DataWorks データマップでは、テーブルと DataService Studio API の詳細ページで詳細なリネージ情報を表示できます。この情報は、データのトレーサビリティと管理に役立ちます。コンソールでは、コンピューティングとメタデータが EMR Hive、Data Lake Formation (DLF)、Data Lake Formation (DLF-Legacy) などのタイプ別に分類されます。このトピックでは、データマップと Data Studio と同じ分類を使用して、各タイプのリネージを表示する方法について説明します。
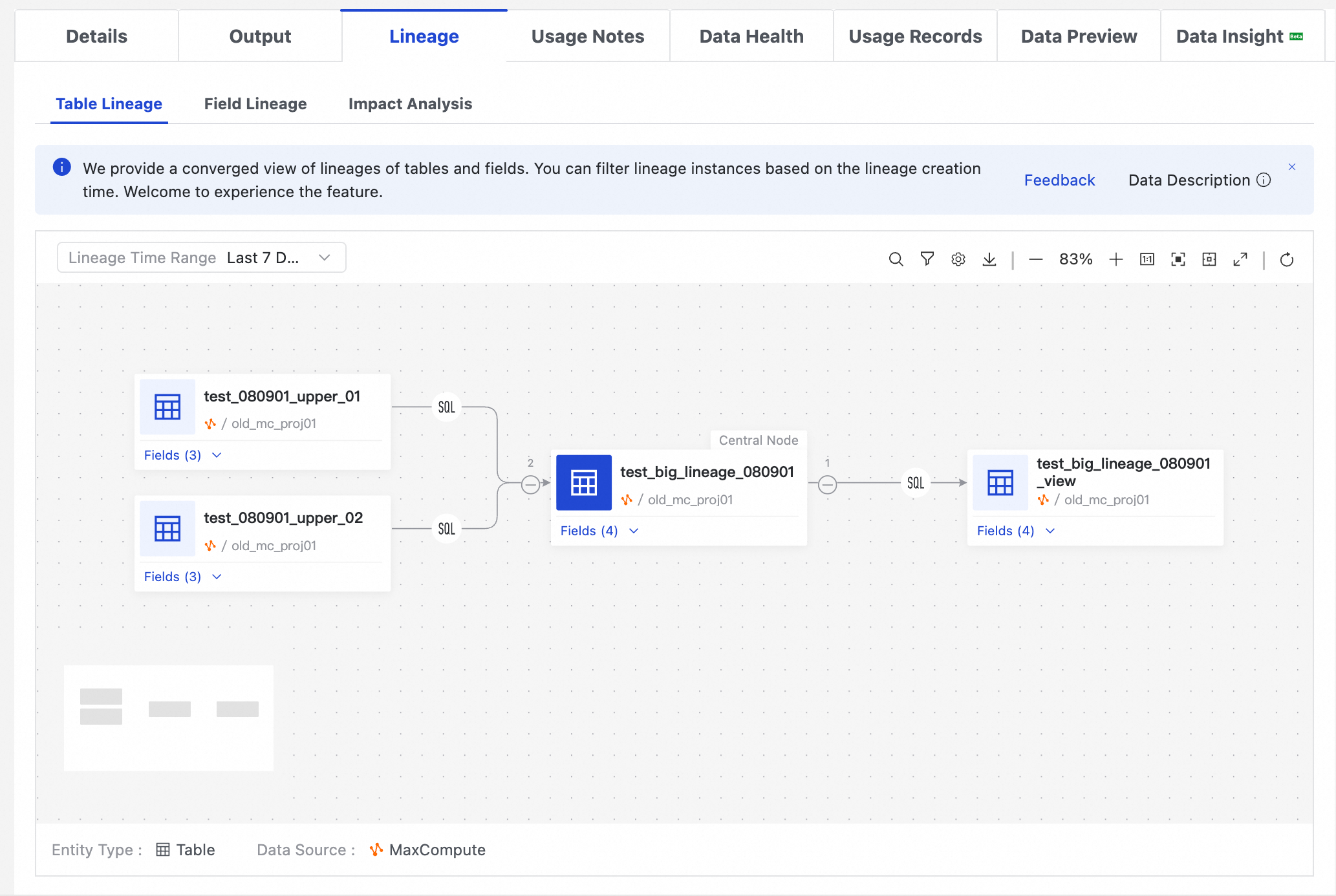
Table Lineage
表示のエントリポイント
データマップでテーブルを検索し、その詳細ページに移動します。次に、Lineage Information タブをクリックして、テーブルレベルとフィールドレベルのリネージ詳細を表示します。また、影響分析を実行して、テーブルの子孫テーブルのリストを取得することもできます。このリストをローカルファイルとしてダウンロードしたり、変更通知をメールで送信したりできます。
データマップには、スケジューリングジョブとデータ転送情報から解析されたテーブルとフィールド間のリネージが表示されます。一時的なクエリなどの手動操作によるリネージは含まれません。オフラインデータのリネージは T+1 ベースで更新されます。
複雑なマルチレベルのリネージをより広いエリアで表示するには、リネージグラフの右上隅にあるツールバーの [新しいページで開く] ボタン (フルスクリーンアイコン) をクリックします。これにより、別のページでリネージを閲覧できます。このボタンは、テーブル、データセット、DataService Studio API、および AI アセットのリネージタブで利用できます。
ご利用のワークスペースまたはテナントでデータリネージ機能が有効になっていない場合、リネージタブに移動するとサブスクリプションページが表示されます。画面の指示に従って、機能を購入または有効にすることができます。
各データソースの制限事項
EMR Hive、DLF、および DLF-Legacy
-
EMR Hive: DataWorks で EMR クラスターのメタデータを管理するには、まずクラスターで EMR-HOOK を設定する必要があります。EMR-HOOK が設定されていない場合、DataWorks にリネージは表示されません。詳細については、「Hive の EMR-HOOK の設定」をご参照ください。
-
DLF および DLF-Legacy: Data Lake Formation (DLF) および Data Lake Formation (DLF-Legacy) のテーブルの場合、メタデータが収集された後、データマップにリネージを表示できます。これは、コンピューティングジョブが Serverless Spark、Serverless StarRocks、または Serverless Flink エンジンで対応する DLF メタデータを使用する場合にサポートされます。他のエンジンやシナリオの場合、リネージの表示はメタデータ取得と解析の機能に依存します。詳細については、「メタデータ取得」をご参照ください。
重要Serverless Spark、Serverless StarRocks、および Serverless Flink エンジンは、DataWorks ワークスペースにアタッチする必要があります。そうでない場合、対応するリネージは DataWorks と無関係と見なされ、無視されます。
-
EMR Hive 計算クラスターの場合: リネージの表示は、EMR on ACK Spark クラスターではサポートされていませんが、EMR Serverless Spark クラスターではサポートされています。
-
EMR Hive 計算クラスターの場合: EMR Presto ノードで実行されるタスクのリネージは利用できません。
-
EMR Impala エンジン: EMR Impala ジョブのリネージ取得は、Impala 独自のリネージログに依存します。EMR クラスターコンソールで、[クラスターサービス] > [Impala] > [設定] に移動します。
lineage_event_log_dirパラメーターを/mnt/disk1/log/impala/lineage_logに設定し、Impala サービスを再起動します。これらの手順を実行すると、DataWorks データマップで EMR Impala ジョブのテーブルレベルおよびフィールドレベルのリネージを表示できます。説明-
EMR DataLake クラスター上の Impala ジョブのみがサポートされます。Hive Metastore (HMS) (EMR Hive データソースタイプに対応) と DLF (DLF データソースタイプに対応) の両方のメタデータがサポートされます。
-
クラスターに Impala がデプロイされていれば、EMR クラスターのバージョンや Impala のバージョンに要件はありません。
-
この機能は現在、段階的にリリースされています。これを使用するには、するか、チケットを送信するか、Alibaba Cloud テクニカルサポートに連絡して有効にする必要があります。
-
AnalyticDB for MySQL
-
エンジンで SQL コマンド
set adb_config RC_LINEAGE_INFO_LOG_ENABLE=trueを実行して、AnalyticDB for MySQL インスタンスのデータリネージ機能を有効にできます。 -
メタデータソースが AnalyticDB for Spark の場合、自動取得がサポートされます。
-
メタデータソースが AnalyticDB for Spark の場合、リアルタイムリネージをサポートするには、Spark パラメーター
spark.sql.queryExecutionListeners = com.aliyun.dataworks.meta.lineage.LineageListenerを設定する必要があります。
AnalyticDB for MySQL テーブルでは、一部の SQL コマンドはデータマップでのリネージ生成をサポートしていません。制限事項は次のとおりです。
-
サポートされていない SQL コマンド:
サポートされていない SQL
例
JOIN、UNION、および*などのキーワードはサポートされていません。たとえば、次の SQL コマンドは
*を使用しています。データマップではそのリネージを表示できません。INSERT INTO test SELECT * FROM test1, test2 WHERE test1.id = test2.idサブクエリはサポートされていません。
たとえば、次の SQL コマンドにはサブクエリが含まれています。データマップではそのリネージを表示できません。
SELECT column1, column2 FROM table1 WHERE column3 IN (SELECT column4 FROM table2 WHERE column5 = 'value') -
リネージをサポートする SQL コマンドの例:
-
例 1: 列情報を指定せずに A という名前のテーブルを作成し、テーブル B から * を除く特定の列を選択してテーブル A にデータを入力します。例:
CREATE TABLE test AS SELECT id,name FROM test1; -
例 2: 条件 `column1 = value1` を満たすテーブル A の * を除く特定の列から、列情報を指定せずにテーブル B にデータを挿入します。例:
INSERT INTO test SELECT id,name FROM test1 WHERE name='test'; -
例 3: データベース内のテーブル B を、テーブル A の * を除く特定の列のデータで上書きします。例:
INSERT OVERWRITE INTO db_name.test SELECT id,name FROM test1;
-
CDH
データマップで CDH Spark SQL および CDH Spark ノードのデータ変換プロセスのテーブルリネージを表示するには、 で特定のデータ変換モジュールの Spark パラメーターを設定する必要があります。
DataWorks コンソールにログインします。対象リージョンで、左側のナビゲーションウィンドウの をクリックします。ドロップダウンリストからワークスペースを選択し、入力 管理センター をクリックします。
-
左側のナビゲーションウィンドウで クラスター管理 をクリックし、作成した対象の CDH クラスターを見つけます。
-
Sparkパラメーターの編集 をクリックします。

-
特定のデータ変換モジュールに基づいて Spark パラメーターを追加します。
たとえば、データマップの [オペレーションセンター - 定期実行インスタンス] モジュールで CDH Spark SQL および CDH Spark ノードのデータ変換プロセスのテーブルリネージを表示するには、そのモジュールに次のパラメーターを追加します。
-
Sparkプロパティ名:
spark.sql.queryExecutionListeners。 -
Spark属性値:
com.aliyun.dataworks.meta.lineage.LineageListener。
-
-
Confirm をクリックして編集を完了します。
Lindorm
リネージ情報はインスタンスモードでのみ収集できます。接続文字列モードでは収集できません。
データマップで Lindorm Spark および Lindorm Spark SQL ノードのデータ変換プロセスのテーブルリネージを表示するには、 で特定のデータ変換モジュールの Spark パラメーターを設定する必要があります。
DataWorks コンソールにログインします。対象リージョンで、左側のナビゲーションウィンドウの をクリックします。ドロップダウンリストからワークスペースを選択し、入力 管理センター をクリックします。
-
左側のナビゲーションウィンドウで Computing Resources をクリックし、作成した Lindorm 計算リソースを見つけます。
-
Sparkパラメーターの編集 をクリックします。
-
特定のデータ変換モジュールに基づいて Spark パラメーターを追加します。
たとえば、データマップの [オペレーションセンター - 定期実行インスタンス] モジュールで Lindorm Spark および Lindorm Spark SQL ノードのデータ変換プロセスのテーブルリネージを表示するには、そのモジュールに次のパラメーターを追加します。
-
Sparkプロパティ名:
spark.sql.queryExecutionListeners。 -
Spark属性値:
com.aliyun.dataworks.meta.lineage.LineageListener。
-
-
Confirm をクリックして Spark パラメーター設定を保存します。
データソースのリネージサポートの概要
元の E-MapReduce データソースは、メタデータソースに基づいて、データマップで EMR Hive、DLF、および DLF-Legacy に分割されました。次の表に、現在のコンソールに表示される各データソースカテゴリのリネージサポートを示します。
|
データソース |
データ統合 |
データ開発 |
||
|
テーブルレベルのリネージ |
フィールドレベルのリネージ |
テーブルレベルのリネージ |
フィールドレベルのリネージ |
|
|
AnalyticDB for MySQL
|
|
|
|
|
|
AnalyticDB for PostgreSQL
|
|
|
|
|
|
ClickHouse
|
|
|
|
|
|
CDH/CDP
|
|
|
Hive、Impala、Spark、Spark SQL
|
Hive、Impala、Spark、Spark SQL
|
|
EMR Hive
|
(OSS, Hive)
|
(OSS, Hive)
|
EMR、Serverless Spark、Serverless StarRocks、Serverless Flink エンジン、および EMR Impala エンジン (EMR DataLake クラスターのみ。この機能は段階的リリースであり、有効化するには Alibaba Cloud テクニカルサポートへの連絡が必要です) をサポートします。
|
EMR、Serverless Spark、Serverless StarRocks、Serverless Flink エンジン、および EMR Impala エンジン (EMR DataLake クラスターのみ。この機能は段階的リリースであり、有効化するには Alibaba Cloud テクニカルサポートへの連絡が必要です) をサポートします。
|
|
DLF-Legacy
|
(OSS, Hive)
|
(OSS, Hive)
|
EMR、Serverless Spark、Serverless StarRocks、Serverless Flink エンジン、および EMR Impala エンジン (EMR DataLake クラスターのみ。この機能は段階的リリースであり、有効化するには Alibaba Cloud テクニカルサポートへの連絡が必要です) をサポートします。
|
EMR、Serverless Spark、Serverless StarRocks、Serverless Flink エンジン、および EMR Impala エンジン (EMR DataLake クラスターのみ。この機能は段階的リリースであり、有効化するには Alibaba Cloud テクニカルサポートへの連絡が必要です) をサポートします。
|
|
DLF
|
(OSS, Hive)
|
(OSS, Hive)
|
Serverless Spark、Serverless StarRocks、Serverless Flink エンジン、および EMR Impala エンジン (EMR DataLake クラスターのみ。この機能は段階的リリースであり、有効化するには Alibaba Cloud テクニカルサポートへの連絡が必要です) をサポートします。
|
Serverless Spark、Serverless StarRocks、Serverless Flink エンジン、および EMR Impala エンジン (EMR DataLake クラスターのみ。この機能は段階的リリースであり、有効化するには Alibaba Cloud テクニカルサポートへの連絡が必要です) をサポートします。
|
|
Hologres
|
|
|
|
|
|
Kafka
|
(Kafka から MaxCompute または Hologres へ) |
|
|
|
|
Lindorm
|
|
|
|
|
|
MaxCompute
|
|
|
|
|
|
MySQL
|
(MySQL から MaxCompute または Hologres へ) |
|
|
|
|
Oracle
|
|
|
|
|
|
OceanBase
|
|
|
|
|
|
OSS
|
|
|
|
|
|
PolarDB for MySQL
|
|
|
|
|
|
PolarDB for PostgreSQL
|
|
|
|
|
|
PostgreSQL
|
|
|
|
|
|
StarRocks
|
|
|
|
|
|
SQL Server
|
|
|
|
|
|
Tablestore (OTS)
|
|
|
|
|
 製品ページ
製品ページ リアルタイム同期
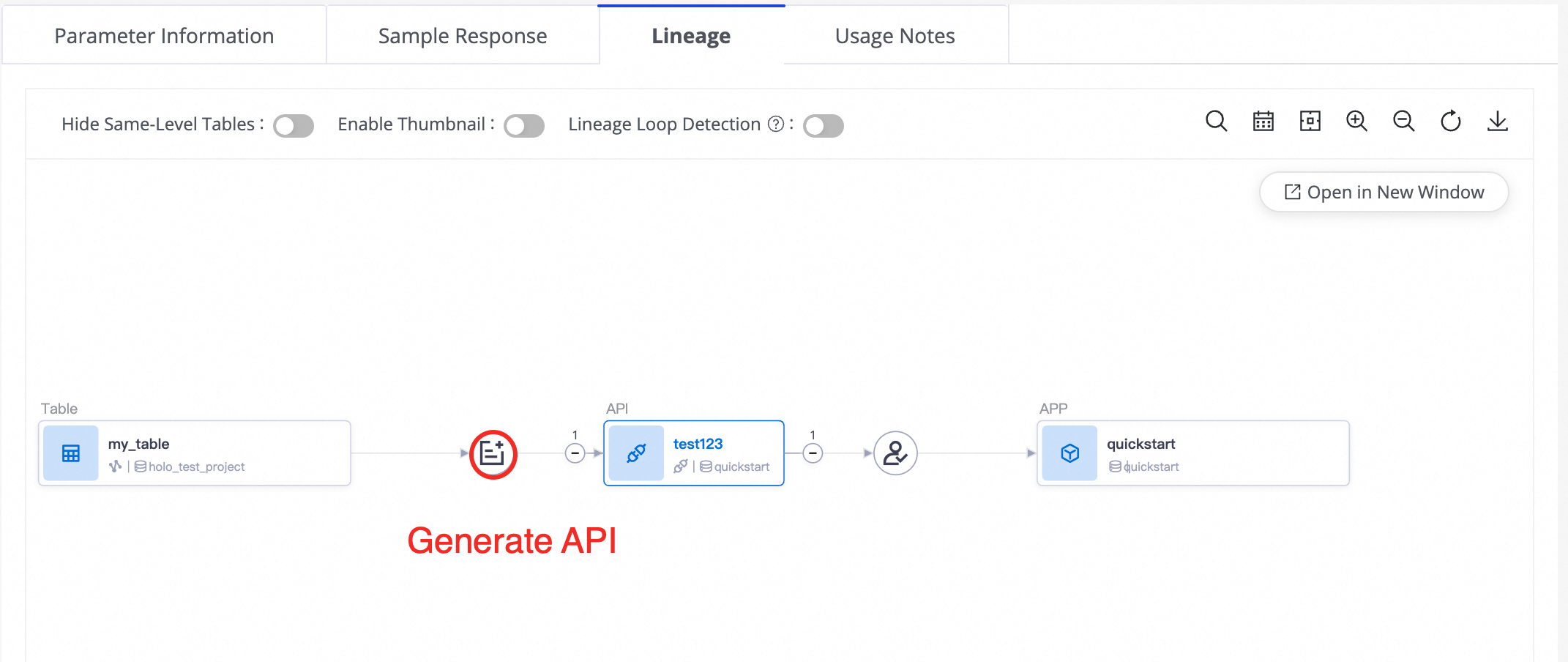
リアルタイム同期DataService Studio API のリネージ
DataService Studio API を検索し、その詳細ページに移動します。次に、Lineage Information タブをクリックして、API のリネージ詳細を表示します。
AI アセットのリネージ
AI アセットリネージサービスを使用すると、モデルトレーニングで使用される入力データセット、出力結果セット、およびモデル間のリネージをトレースできます。AI アセットリネージの詳細については、「AI アセットの表示」をご参照ください。