GitHub でオープンソースプロジェクトに基づいて開発者がコードを開発すると、多数のイベントが生成されます。 GitHub は、イベントタイプ、イベントの詳細、開発者、コードリポジトリなど、各イベントに関する情報を記録します。 GitHub はパブリックイベントも公開しています。DataWorks は、「GitHub で人気の高いプログラミング言語トップ 10」という名前のテンプレートを提供しています。 このテンプレートを使用して、GitHub のパブリックデータセットを処理および分析し、分析結果をメールで特定のユーザーに送信できます。 このトピックで説明されているケースを実行すると、GitHub で 1 時間あたりに使用されている上位 10 のプログラミング言語と、1 時間あたりの各プログラミング言語の送信数を取得できます。
実際には、手動設定と ETL テンプレートのワークフローの詳細には多少の違いがありますが、両方のケースの効果は基本的に同じです。
ケースの説明
DataWorks は、GitHub からのリアルタイムのパブリックデータを格納するパブリック MySQL データソースを提供します。 このトピックでは、データの同期と分析、およびデータ分析結果を指定されたメールボックスに送信する方法について説明します。主なビジネスプロセス:
DataWorks のデータ統合サービスを使用して、リアルタイムの GitHub データを MySQL データソースから MaxCompute に同期します。
同期されたデータを分析および処理し、前の 1 時間で使用された上位 10 のプログラミング言語と、GitHub の前の 1 時間における各プログラミング言語の送信数を取得し、データ処理結果を Alibaba Cloud Object Storage Service(OSS)に保存します。
データ処理結果を指定されたメールボックスに送信する Python 関数を関数計算で開発します。
DataWorks が提供するタスクスケジューリング機能を使用して、GitHub の前の 1 時間における上位プログラミング言語の自動更新を実装し、データ処理結果を指定されたメールボックスに送信します。
手順
リソースの準備
このトピックで説明されている操作を実行する前に、関連する Alibaba Cloud サービスをアクティブ化し、必要な準備を行う必要があります。
関連する Alibaba Cloud サービスは同じリージョンでアクティブ化することをお勧めします。このトピックでは、サービスは中国(上海)リージョンでアクティブ化されています。
関連する Alibaba Cloud サービスを以前に使用したことがない場合は、無料トライアルに申し込むことができます。詳細については、「DataWorks の無料トライアル」、「MaxCompute の無料トライアル」、「関数計算の無料トライアル」、「OSS の無料トライアル」を参照してください。
DataWorks をアクティブ化し、ワークスペースを作成します。このトピックでは、標準モードのワークスペースが作成されます。基本モードのワークスペースでの操作は、標準モードのワークスペースでの操作と似ています。詳細については、「DataWorks をアクティブ化する」および「ワークスペースを作成する」を参照してください。
MaxCompute をアクティブ化し、MaxCompute プロジェクトを作成します。詳細については、「MaxCompute と DataWorks をアクティブ化する」を参照してください。
関数計算 をアクティブ化します。詳細については、「ステップ 1:関数計算サービスをアクティブ化する」を参照してください。
OSS をアクティブ化し、OSS バケットを作成します。詳細については、「OSS コンソールを使用して開始する」および「ステップ 1:バケットを作成する」を参照してください。
OSS コンソールでの操作:OSS バケットを作成する
OSS コンソール にログインします。左側のナビゲーションペインで、[バケット] をクリックします。 [バケット] ページで、[バケットを作成] をクリックします。 [バケットを作成] パネルで、[バケット名] と [リージョン] パラメーターを設定し、[OK] をクリックします。

関数計算コンソールでの操作:関数を作成し、関数のコードロジックを開発する
関数計算コンソール にログインします。サービスを作成し、OSS に対する権限をサービスに付与します。
関数コードロジックを開発するときは、目的の OSS バケット内のデータを読み取り、データ処理結果を指定されたメールボックスに送信する必要があります。この場合、目的の関数が属するサービスに OSS に対する必要な権限を付与する必要があります。
右上隅の [関数計算 2.0 に戻る] をクリックします。関数計算 2.0 コンソールに移動します。
左側のナビゲーションペインで、[サービスと関数] をクリックします。 [サービス] ページの左上隅で、サービスを作成するリージョンを選択します。次に、[サービスを作成] をクリックします。 [サービスを作成] パネルで、[名前] パラメーターを設定し、[OK] をクリックします。
作成したサービスの名前をクリックします。表示されるページの左側のナビゲーションペインで、[サービスの詳細] をクリックします。 [サービスの詳細] タブの [ロール設定] セクションで、[変更] をクリックします。表示されるページで、[サービスロール] ドロップダウンリストから [aliyunfcdefaultrole] を選択し、[保存] をクリックして、[サービスの詳細] タブに戻ります。 [ロール設定] セクションで、[aliyunfcdefaultrole] をクリックして、RAM コンソールの [ロール] ページに移動します。
[権限] タブの [権限を付与] をクリックします。 [権限を付与] パネルで、システムポリシーの AliyunOSSReadOnlyAccess を選択し、メッセージに従ってポリシーをアタッチします。その後、OSS からデータを読み取る権限がサービスに付与されます。
関数を作成し、関数のコードロジックを開発します。
関数を作成します。
作成したサービスの [サービスの詳細] タブに戻ります。左側のナビゲーションペインで [関数] をクリックします。次に、[関数を作成] をクリックします。 [関数を作成] ページで、[関数名] パラメーターを設定し、[python 3.9] を [ランタイム] ドロップダウンリストから選択し、その他のパラメーターにはデフォルト値を使用し、[作成] をクリックします。
関数環境に関連する依存関係パッケージをインストールします。
説明このトピックでは、Alibaba Cloud セカンドパーティパッケージ oss2 とオープンソースサードパーティパッケージ pandas が必要です。 Python 3.9 ランタイム環境は oss2 パッケージを提供します。 oss2 パッケージを手動でインストールする必要はありません。 pandas パッケージを手動でインストールするには、次の操作を実行する必要があります。
作成した関数の名前をクリックします。表示されるページで、[設定] タブをクリックします。 [設定] タブで、[レイヤー] セクションの [変更] をクリックします。表示されるパネルで、[レイヤーを追加] をクリックし、[パブリックレイヤーを追加] を選択します。次に、[公式共通レイヤー] ドロップダウンリストから [pandas1x] を選択し、[OK] をクリックします。

[コード] タブをクリックします。 WebIDE の Python 環境がロードされたら、次のコードを index.py ファイルにコピーし、OSS 内部エンドポイントとメールボックス関連のパラメーターを変更します。
# -*- coding: utf-8 -*- import logging import json import smtplib import oss2 import pandas as pd from email.mime.text import MIMEText from email.mime.multipart import MIMEMultipart from email.mime.base import MIMEBase from email.mime.text import MIMEText from email.utils import COMMASPACE from email import encoders def handler(event, context): evts = json.loads(event) bucket_name = evts["bucketName"] file_path = evts["filePath"] auth = oss2.StsAuth(context.credentials.access_key_id, context.credentials.access_key_secret, context.credentials.security_token) endpoint = 'https://oss-{}-internal.aliyuncs.com'.format(context.region) // OSS の内部エンドポイント bucket = oss2.Bucket(auth, endpoint, bucket_name) file_name = file_path for obj in oss2.ObjectIteratorV2(bucket, prefix=file_path): if not obj.key.endswith('/'): file_name = obj.key csv_file = bucket.get_object(file_name) logger = logging.getLogger() logger.info('event: %s', evts) mail_host = 'smtp.***.com' // メールサーバーのアドレス mail_port = '465'; // シンプルメール転送プロトコル(SMTP)のメールサーバーのポート mail_username = 'sender_****@163.com' // ID 認証のユーザー名。完全なメールアドレスを入力します。 mail_password = 'EWEL******KRU' // ID 認証のパスワード。メールボックスの SMTP 認証コードを入力します。 mail_sender = 'sender_****@163.com' // 送信者のメールアドレス mail_receivers = ['receiver_****@163.com'] // 受信者のメールアドレス message = MIMEMultipart('alternative') message['Subject'] = 'GitHub データ処理結果' message['From'] = mail_sender message['To'] = mail_receivers[0] html_message = generate_mail_content(evts, csv_file) message.attach(html_message) # メールを送信する smtpObj = smtplib.SMTP_SSL(mail_host + ':' + mail_port) smtpObj.login(mail_username,mail_password) smtpObj.sendmail(mail_sender,mail_receivers,message.as_string()) smtpObj.quit() return 'mail send success' def generate_mail_title(evt): mail_title='' if 'mailTitle' in evt.keys(): mail_content=evt['mailTitle'] else: logger = logging.getLogger() logger.error('msg not present in event') return mail_title def generate_mail_content(evts, csv_file): headerList = ['Github Repos', 'Stars'] # CSV ファイルの内容を読み取る dumped_file = pd.read_csv(csv_file, names=headerList) # DataFrame を HTML テーブルに変換する table_html = dumped_file.to_html(header=headerList,index=False) # DataFrame を HTML テーブルに変換する table_html = dumped_file.to_html(index=False) mail_title=generate_mail_title(evts) # メール本文 html = f""" <html> <body> <h2>{mail_title}</h2> <p>過去 1 時間の GitHub で上位 10 の言語は次のとおりです。</p> {table_html} </body> </html> """ # HTML メッセージを添付する html_message = MIMEText(html, 'html') return html_message説明上記のコードでは、変数 bucketName、filePath、mailTitle が使用されています。 DataWorks で作成した関数計算ノードから変数の値を取得できます。コード内の変数の値を変更する必要はありません。
変更するパラメーター
設定ガイド
OSS の内部エンドポイント
(コードの 20 行目)
関連操作を実行するリージョンに基づいて、
'https://oss-{}-internal.aliyuncs.com'を OSS の内部エンドポイントに置き換えます。たとえば、中国(上海)リージョンで操作を実行する場合、'https://oss-{}-internal.aliyuncs.com' を
'https://oss-cn-shanghai-internal.aliyuncs.com'に置き換える必要があります。さまざまなリージョンの OSS 内部エンドポイントの詳細については、「リージョンとエンドポイント」を参照してください。
メールボックス関連パラメーター
(コードの 31 ~ 36 行目)
ビジネス要件に基づいて次の操作を実行します。
コードの 31 ~ 35 行目のパラメーターの値を、メールサーバーのアドレス、SMTP ポート、ユーザー名、パスワード、送信者のメールアドレスに変更します。
コードの 36 行目のパラメーターの値を受信者のメールアドレスに変更します。
説明メールボックスのヘルプドキュメントを参照して、関連する設定を取得できます。
コードロジックの開発が完了したら、[デプロイ] をクリックします。
DataWorks コンソールでの操作:データソースを追加する
MySQL データソースを追加します。
このトピックで使用されるパブリック GitHub データは、パブリック MySQL データベースに保存されています。この場合、最初に MySQL データソースを追加して、MaxCompute にデータを同期するときに MySQL データベースに接続する必要があります。
データソースページに移動します。
DataWorks コンソール にログインします。上部のナビゲーションバーで目的のリージョンを選択します。左側のナビゲーションペインで、 を選択します。表示されるページで、ドロップダウンリストから目的のワークスペースを選択し、[管理センターに移動] をクリックします。
SettingCenter ページの左側のナビゲーションペインで、 を選択します。
[データソース] ページで、[データソースを追加] をクリックします。 [データソースを追加] ダイアログボックスで、[mysql] をクリックし、メッセージに従ってデータソース名などのパラメーターを設定します。次の表に主要なパラメーターを示します。
パラメーター
説明
設定モード
このパラメーターを [接続文字列モード] に設定します。
データソース名
カスタム名を指定できます。このトピックでは、このパラメーターを github_events_share に設定します。
接続アドレス
このパラメーターを jdbc:mysql://rm-bp1z69dodhh85z9qa.mysql.rds.aliyuncs.com:3306/github_events_share に設定します。
重要このタイプのデータソースは、データ同期シナリオでのデータの読み取りにのみ使用できます。
ユーザー名
このパラメーターを workshop に設定します。
パスワード
このパラメーターを workshop#2017 に設定します。
このパスワードは参照用です。実際のビジネスでは使用しないでください。
認証方法
このパラメーターを [認証なし] に設定します。
リソースグループの接続性
データ統合の共有リソースグループを見つけて、[接続ステータス(開発環境)] 列の [ネットワーク接続をテスト] をクリックします。ネットワーク接続テストが成功した場合、[接続ステータス(開発環境)] 列に [接続可能] と表示されます。
MaxCompute データソースを追加します。
GitHub データは MaxCompute に同期する必要があります。この場合、最初に MaxCompute データソースを追加する必要があります。
データソースページに移動します。
DataWorks コンソール にログインします。上部のナビゲーションバーで目的のリージョンを選択します。左側のナビゲーションペインで、 を選択します。表示されるページで、ドロップダウンリストから目的のワークスペースを選択し、[管理センターに移動] をクリックします。
SettingCenter ページの左側のナビゲーションペインで、 を選択します。
[データソース] ページで、[データソースを追加] をクリックします。 [データソースを追加] ダイアログボックスで、[maxcompute] をクリックし、メッセージに従ってデータソース名や MaxCompute プロジェクト名などのパラメーターを設定します。詳細については、「MaxCompute データソースを追加する」を参照してください。
MaxCompute データソースを DataStudio に関連付けます。
データ処理用の MaxCompute SQL タスクを作成する必要があります。この場合、SQL タスクの開発用に ODPS SQL ノードを作成できるように、MaxCompute データソースを DataStudio に関連付ける必要があります。詳細については、「データソースの追加またはクラスターのワークスペースへの登録」を参照してください。
説明データソース情報が変更されたが、[データソース] ページのデータがタイムリーに更新されない場合は、[データソース] ページを更新してキャッシュされたデータを更新してください。
DataWorks コンソールでの操作:ワークフローを作成し、データ処理タスクを開発する
DataStudio ページに移動します。
DataWorks コンソール にログインします。上部のナビゲーションバーで目的のリージョンを選択します。左側のナビゲーションペインで、 を選択します。表示されるページで、ドロップダウンリストから目的のワークスペースを選択し、[データ開発に移動] をクリックします。
ワークフローを作成します。
DataStudio ページの [スケジュールされたワークフロー] ペインで、 を選択します。 [ワークフローを作成] ダイアログボックスで、[ワークフロー名] パラメーターを設定し、[作成] をクリックします。
ノードを作成し、ノードのスケジューリング依存関係を設定します。

作成したワークフローの名前をダブルクリックして、ワークフローの設定タブに移動します。
上部ツールバーの [ノードを作成] をクリックします。次に、[オフライン同期] をキャンバスにドラッグします。 [ノードを作成] ダイアログボックスで、[名前] パラメーターを設定し、[確認] をクリックしてバッチ同期ノードを作成します。
同様の操作を実行して、[ODPS SQL] ノードと [関数計算] ノードを作成します。
バッチ同期ノードを設定します。
バッチ同期ノードの名前をダブルクリックして、バッチ同期ノードの設定タブに移動します。
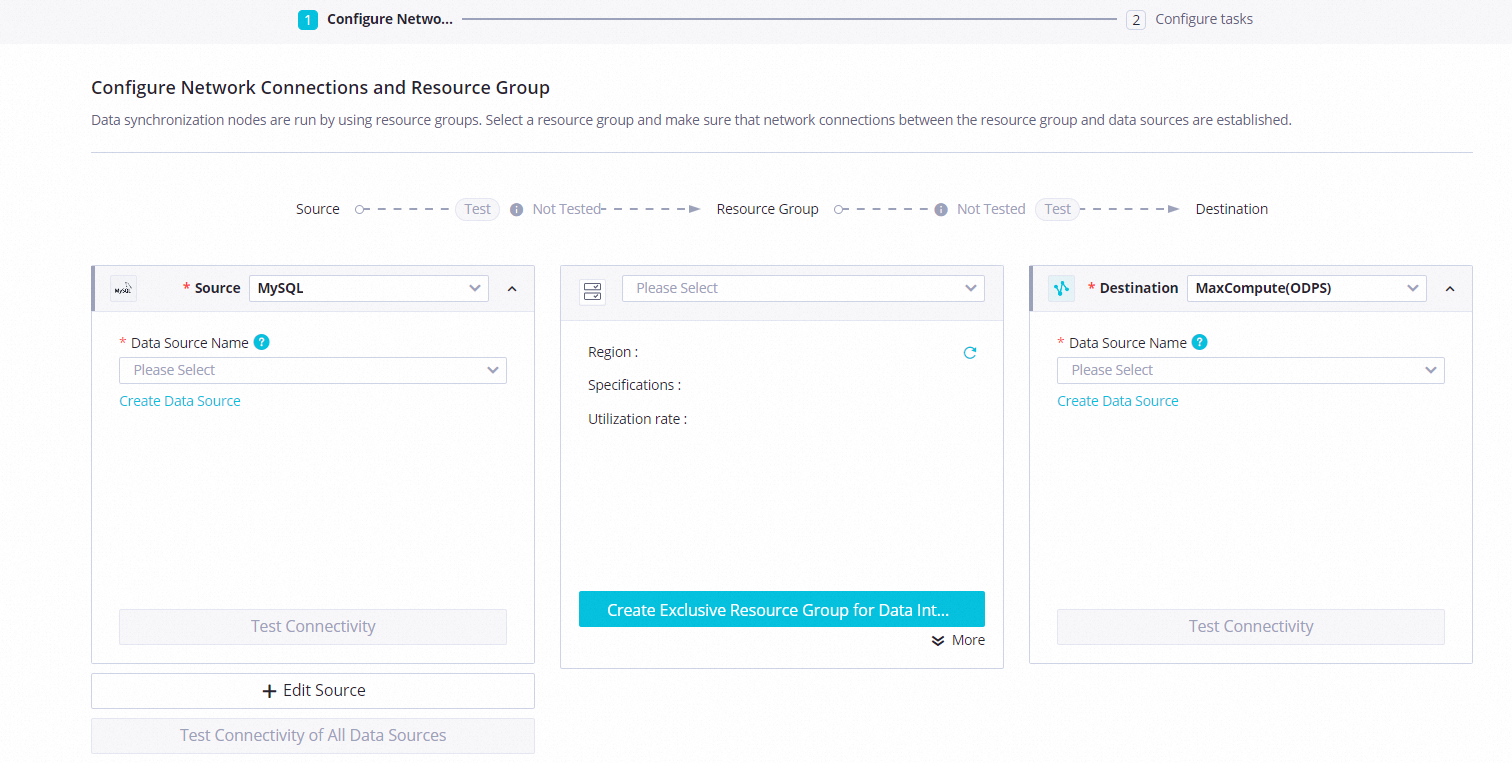
リソースグループとデータソース間のネットワーク接続を設定します。
パラメーター
説明
ソース
[ソース] ドロップダウンリストから [MySQL] を選択し、[データソース名] ドロップダウンリストから追加した MySQL データソースを選択します。
送信先
[送信先] ドロップダウンリストから [MaxCompute] を選択し、[データソース名] ドロップダウンリストから追加した MaxCompute データソースを選択します。
リソースグループ
右下隅の を選択します。
[次へ] をクリックして、メッセージに従ってネットワーク接続テストを完了します。
バッチ同期ノードを設定します。次の表に主要なパラメーターを示します。その他のパラメーターにはデフォルト値を保持します。
セクション
説明
ソース
テーブル:ドロップダウンリストから github_public_event を選択します。
データフィルタリング:次のコンテンツを使用します。
created_at >'${day1} ${hour1}' and created_at<'${day2} ${hour2}'
送信先
テーブル:[送信先テーブルスキーマを生成] をクリックします。 [テーブルを作成] ダイアログボックスで、[テーブルを作成] をクリックします。
パーティション情報:このパラメーターを
pt=${day_hour}に設定します。
右側のナビゲーションペインの [プロパティ] タブをクリックし、ノードのスケジューリングパラメーターを設定します。次の表に主要なパラメーターを示します。その他のパラメーターにはデフォルト値を保持します。
セクション
説明
スケジューリングパラメーター
[コード内のパラメーターをロード] をクリックします。値の割り当てロジックが設定された次のパラメーターが追加されます。
day1:$[yyyy-mm-dd-1/24]hour1:$[hh24-1/24]day2:$[yyyy-mm-dd]hour2:$[hh24]day_hour:$[yyyymmddhh24]
スケジュール
スケジューリング周期:このパラメーターを [時間] に設定します。
再実行:このパラメーターを [実行ステータスに関係なく許可] に設定します。
依存関係
[ルートノードを追加] チェックボックスをオンにします。
上部ツールバーの [保存] をクリックして、ノードの設定を保存します。
ODPS SQL ノードを設定します。
ODPS SQL ノードの名前をダブルクリックして、ODPS SQL ノードの設定タブに移動します。
次のサンプルコードをコードエディターにコピーして貼り付けます。
重要次のサンプルコードでは、処理済みデータを保存するために OSS 外部テーブルが作成されます。 OSS 外部テーブルを初めて使用する場合は、現在のアカウントに必要な権限を付与する必要があります。そうしないと、目的のワークフローを実行するとエラーが報告されます。認証の詳細については、「OSS の STS 認証」を参照してください。
-- 1. パブリック GitHub データセットのデータの処理結果を保存するために、MaxCompute 用の OSS 外部テーブルを作成します。 -- OSS 外部テーブルの名前は odps_external で、前に作成した OSS バケットに保存されます。 OSS バケットの名前は xc-bucket-demo2 です。ビジネス要件に基づいて名前を変更できます。 CREATE EXTERNAL TABLE IF NOT EXISTS odps_external( language STRING COMMENT 'owner/Repository_name 形式の完全なリポジトリ名。', num STRING COMMENT '送信回数。' ) partitioned by ( direction string ) STORED BY 'com.aliyun.odps.CsvStorageHandler' WITH SERDEPROPERTIES( 'odps.text.option.header.lines.count'='0', 'odps.text.option.encoding'='UTF-8', 'odps.text.option.ignore.empty.lines'='false', 'odps.text.option.null.indicator'='') LOCATION 'oss://oss-cn-shanghai-internal.aliyuncs.com/${YOUR_BUCKET_NAME}/odps_external/'; -- 2. MaxCompute に同期された GitHub データを処理し、処理結果を OSS 外部テーブルに書き込みます。 -- GitHub で前の 1 時間に使用された上位 10 のプログラミング言語と、前の 1 時間における各プログラミング言語の送信数を取得します。 SET odps.sql.unstructured.oss.commit.mode=true; INSERT INTO TABLE odps_external partition (direction='${day_hour}') SELECT language, COUNT(*) AS num FROM github_public_event WHERE language IS NOT NULL AND pt='${day_hour}' GROUP BY language ORDER BY num DESC limit 10;右側のナビゲーションペインの [プロパティ] タブをクリックし、ノードのスケジューリングパラメーターを設定します。次の表に主要なパラメーターを示します。その他のパラメーターにはデフォルト値を保持します。
セクション
説明
スケジューリングパラメーター
[コード内のパラメーターをロード] をクリックします。値の割り当てロジックが設定された次のパラメーターが追加されます。
YOUR_BUCKET_NAME:前に作成した OSS バケットの名前day_hour:$[yyyymmddhh24]
スケジュール
スケジューリング周期:このパラメーターを [時間] に設定します。
再実行:このパラメーターを [実行ステータスに関係なく許可] に設定します。
上部ツールバーの [保存] をクリックして、ノードの設定を保存します。
関数計算ノードを設定します。
関数計算ノードの名前をダブルクリックして、関数計算ノードの設定タブに移動します。
関数計算ノードを設定します。
パラメーター
説明
サービスを選択
関数計算コンソールで作成したサービスを選択します。
関数を選択
関数計算コンソールで作成した関数を選択します。
呼び出し方法
[同期呼び出し] を選択します。
変数
次のコンテンツを使用します。
{ "bucketName": "${YOUR_BUCKET_NAME}", "filePath": "odps_external/direction=${day_hour}/", "mailTitle":"GitHub で前の 1 時間に使用された上位 10 のプログラミング言語と、前の 1 時間における各プログラミング言語の送信回数" }右側のナビゲーションペインの [プロパティ] タブをクリックし、ノードのスケジューリングパラメーターを設定します。次の表に主要なパラメーターを示します。その他のパラメーターにはデフォルト値を保持します。
セクション
説明
スケジューリングパラメーター
[パラメーターを追加] をクリックして次のパラメーターを追加し、パラメーターの値の割り当てロジックを設定します。
YOUR_BUCKET_NAME:前に作成した OSS バケットの名前day_hour:$[yyyymmddhh24]
スケジュール
スケジューリング周期:このパラメーターを [時間] に設定します。
再実行:このパラメーターを [実行ステータスに関係なく許可] に設定します。
上部ツールバーの [保存] をクリックして、ノードの設定を保存します。
DataWorks コンソールでの操作:ワークフローを実行する
DataStudio ページの [スケジュールされたワークフロー] ペインで、作成したワークフローを見つけて、ワークフローの名前をダブルクリックして、ワークフローの設定タブに移動します。
上部ツールバーの [実行] アイコンをクリックして、ワークフロー全体を実行します。
ワークフローの実行が完了したことがシステムから通知された場合は、データ処理結果を受信するメールボックスにログインして、関連するメールを表示できます。
DataWorks コンソールでの操作:ワークフローをコミットしてデプロイする
オプション。データを MaxCompute に定期的に同期して処理し、データ処理結果を指定されたメールボックスに定期的に送信する場合は、目的のワークフローを DataWorks の運用センターにコミットしてデプロイする必要があります。
DataStudio ページで、目的のワークフローを見つけて、ワークフローの名前をダブルクリックして、ワークフローの設定タブに移動します。
上部ツールバーの [送信] アイコンをクリックしてワークフローをコミットし、メッセージに従ってワークフローを運用センターにデプロイします。詳細については、「ノードをデプロイする」を参照してください。
その後、ワークフローは、設定されたスケジューリングサイクルに基づいて定期的に実行されます。
次のステップ:リソースを解放する
無料トライアルでリソースを使用している場合、またはこのトピックで関連するクラウドサービスを使用する必要がなくなった場合は、追加料金が発生しないように、クラウドサービスのリソースを解放できます。
OSS のリソースを解放するには、OSS コンソール にログインし、このトピックで使用されているバケットを削除します。
関数計算のリソースを解放するには、関数計算コンソール にログインし、目的のサービスを削除します。
DataWorks のリソースを解放するには、DataWorks コンソール にログインし、目的のワークスペースを削除します。
MaxCompute のリソースを解放するには、MaxCompute コンソール にログインし、目的のプロジェクトを削除します。