毎日午前 1:00 のように事前定義されたスケジュールで実行されるスケジュールワークフローとは異なり、トリガーワークフローはオンデマンドでイベント駆動型のデータ処理モデルです。ファイルアップロード、メッセージ到着、API 呼び出し、手動クリックなどの外部シグナルによってリアルタイムでトリガーされると実行され、高いリアルタイム応答性と柔軟性を提供します。
特徴 | スケジュールワークフロー | トリガーワークフロー |
トリガーメカニズム | 固定スケジュール (cron 式) | 外部シグナル (イベント、API、または手動) |
実行モデル | スケジュール化され、予測可能 | リアクティブかつオンデマンド |
ユースケース | T+1 のバッチデータウェアハウジングおよび定期レポート | ファイル到着時の処理、業務システムとの連携、手動でのデータパッチ |
主な利点 | 安定性と予測可能な実行 | リアルタイム応答性と柔軟性 |
サポートされているトリガーメソッド
トリガーワークフローは、以下の 3 つのトリガーメソッドをサポートしています。ビジネスシナリオに基づいていずれかを選択してください。
トリガーメソッド | 起動元 | 主なシナリオ | 要点 |
イベントトリガー | 外部イベントソース (Object Storage Service (OSS) や ApsaraMQ for Kafka など) | イベント駆動 ETL:ファイル到着時の処理や、メッセージからのリアルタイム計算のトリガー。 | トリガーを作成し、ワークフローに関連付ける必要があります。本番環境でのみ有効です。 |
手動トリガー | ユーザー (開発者またはオペレーター) | アドホックタスク:1 回限りのデータ処理や分析を実行。 | 開発環境と本番環境の両方で手動実行できます。手動ビジネスプロセスの代替として推奨されます。 |
API トリガー | 外部システム (OpenAPI 経由) | システム連携:CRM や ERP などの業務システムからのコールバックを通じてデータ処理をトリガー。 | 必要な権限を持つ OpenAPI を呼び出す必要があります。 |
クイックスタート:手動トリガーワークフローの作成
このセクションでは、簡単なトリガーワークフローを作成し、手動で実行する方法を説明します。
ステップ 1:トリガーワークフローの作成
DataWorks コンソールの [ワークスペース] ページに移動します。上部のナビゲーションバーで、目的のリージョンを選択します。目的のワークスペースを見つけ、[操作] 列の を選択します。
左側のナビゲーションウィンドウで
 をクリックします。[ビジネスフロー] の横にある
をクリックします。[ビジネスフロー] の横にある  > [ワークフローの作成] をクリックして [ワークフローの作成] ページを開きます。
> [ワークフローの作成] をクリックして [ワークフローの作成] ページを開きます。[ワークフローの作成] ページで、[スケジュールタイプ] を [トリガー実行] に設定し、ワークフローの [名前] を入力して [OK] をクリックします。
ステップ 2:ワークフローのオーケストレーションとノードの開発
ツールバーで [+ ノードの追加] をクリックしてノードリストを開きます。左側のノードタイプリストから Shell ノードをキャンバスにドラッグし、名前を入力して作成します。
Shell ノードをダブルクリックしてコードエディタを開き、次のコードを入力します。
echo "Hello, Trigger Workflow! Current time is ${bizdate}"ツールバーの [保存] をクリックします。
ステップ 3:開発環境でのデバッグ
ワークフローキャンバスに戻り、上部のツールバーにある
 アイコンをクリックします。
アイコンをクリックします。表示されるダイアログボックスで、ワークフローの [現在の実行値] を入力します (たとえば、現在の日付が 20260310 の場合、
bizdateは20260309に置き換える必要があります)。下部の実行ログで、ノードの実行ステータスと
echoコマンドの出力を確認できます。
ステップ 4:本番環境での公開と実行
ワークフローキャンバスで、[公開]
 ボタンをクリックし、プロンプトに従ってワークフローを公開します。
ボタンをクリックし、プロンプトに従ってワークフローを公開します。ワークフローが公開されたら、[オペレーションセンター] > [手動トリガーノード O&M] > [手動タスク] > [トリガーワークフロー] に移動します。
公開したワークフローを見つけ、[操作] 列の [実行] をクリックします。
表示されるダイアログボックスで、再度 [実行] をクリックして、本番環境でワークフローのインスタンスをトリガーします。この実行の詳細は [手動インスタンス] ページで確認できます。
これで、トリガーワークフローを使用する基本を習得しました。次に、より強力なイベント駆動機能について見ていきましょう。
高度なユースケース:イベントトリガーワークフローの作成
シナリオ 1:OSS の新規ファイルを処理する
目的:OSS の指定されたディレクトリに新しい CSV ファイルがアップロードされたときに、ファイルパスを出力するワークフローを自動的にトリガーします。
ステップ 1:OSS トリガーの作成
[オペレーションセンター] > [テナントスケジュール設定] > [トリガー管理] に移動します。
[トリガーの作成] をクリックし、以下のパラメーターを設定します。
説明パラメーターの詳細については、「OSS トリガー」をご参照ください。
[トリガー名]:カスタム名を入力します。例:
oss_new_file_trigger。[適用ワークスペース]:ワークフローが配置されているターゲットワークスペースを選択します。
[トリガーイベントタイプ]:
Object Storage Service (OSS)を選択します。[トリガーイベント]:
oss:ObjectCreated:PutObjectまたは他のアップロードイベントを選択します。[バケット名]:ご利用の OSS バケットを選択します。
[ファイル名]:監視するファイルパスとフォーマットを指定します。ワイルドカードがサポートされています。たとえば、
input/ディレクトリ内のすべての.csvファイルを監視するには、input/*.csvと入力します。ロール設定:この機能を初めて使用する場合は、ワンクリック承認を完了する必要があります。生成された
DataWorks-EventBridge-OSS-MNS-Role-*************という名前のロールを選択します。*************は、ロール名が一意であることを保証するためにランダムに生成された 13 桁の ID を表します。
[OK] をクリックしてトリガーを作成します。
ステップ 2:ワークフローの作成と関連付け
「クイックスタート:手動トリガーワークフローの作成」の手順に従って、
process_oss_file_workflowという名前のトリガーワークフローを作成します。ワークフローキャンバスの右側にある [プロパティ] パネルで、[スケジュールポリシー] を選択します。
[トリガー] ドロップダウンリストから、先ほど作成した
oss_new_file_triggerを選択します。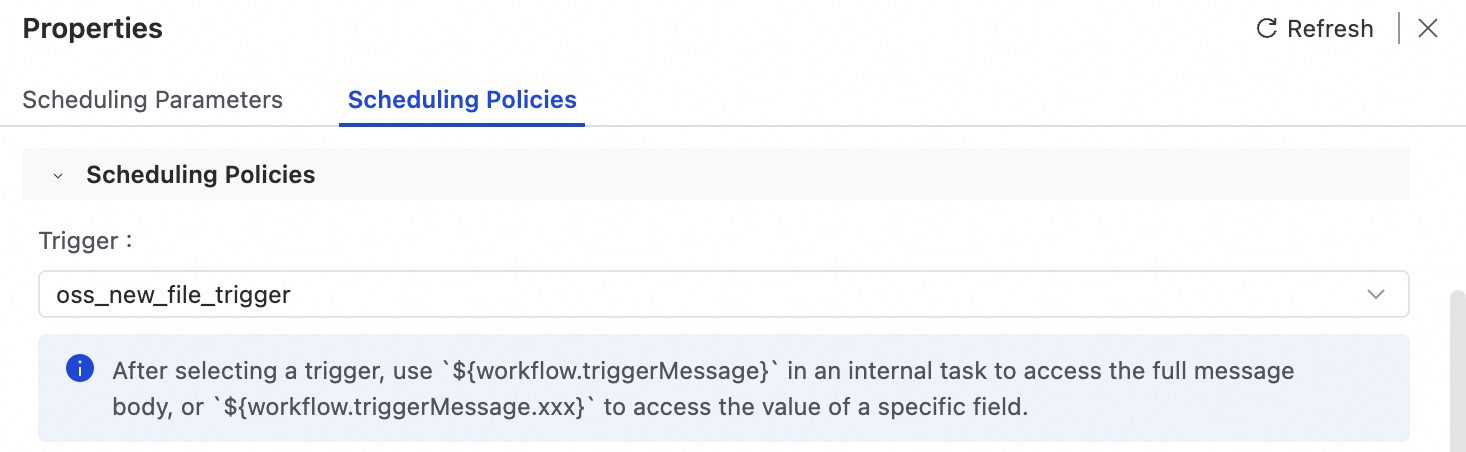
ステップ 3:ノードの開発とイベントパラメーターの解析
ツールバーで [+ ノードの追加] をクリックしてノードリストを開きます。左側のノードタイプリストから Shell ノードをキャンバスにドラッグし、名前を入力して作成します。
ノードをダブルクリックし、次のコードを入力してトリガーイベントからファイルパスを取得して出力します。
# ワークフローがトリガーされると、イベント情報は組み込み変数 workflow.triggerMessage を介して渡されます。 # ${workflow.triggerMessage.data.oss.object.key} を使用して、アップロードされたファイルの完全なパスを取得できます。 echo "========= Start Processing OSS File =========" message="${workflow.triggerMessage}" echo "Raw Value: ${message}" # イベントメッセージからファイルパスを抽出します。 FILE_PATH="${workflow.triggerMessage.data.oss.object.key}" echo "A new file has arrived: ${FILE_PATH}" # ここに特定の処理ロジックを追加します。 echo "========= Finish Processing OSS File ========="説明${workflow.triggerMessage} は、イベントメッセージ本文全体を JSON 形式で取得します。特定の OSS メッセージ形式は、EventBridge で [イベントバス] >
DATAWORKS_TRIGGER_FOR_BUCKET_<OSS_Bucket_Name>> [イベント追跡] > [イベント詳細] に移動して確認できます。
ステップ 4:デバッグと公開
デバッグ:
ワークフローキャンバスに戻り、[実行]
ボタンをクリックします。[トリガーメッセージ本文] 入力ボックスに、シミュレートされた OSS イベントを JSON 形式で貼り付けます。トリガー設定ページからサンプルメッセージをコピーし、
keyフィールドの値を変更できます。以下は最小限の例です。{ "data": { "oss":{ "object": { "key": "input/test_file_20260310.csv" } } } }[実行] をクリックし、ログを確認して
input/test_file_20260310.csvが正常に出力されることを確認します。
公開:デバッグが成功したら、[公開] ボタンをクリックしてワークフローを本番環境にデプロイします。イベント駆動トリガーは本番環境でのみアクティブになります。
ステップ 5:本番環境での検証
OSS コンソールまたはクライアントを使用して、トリガーで設定したバケットとパス (例:
input/ディレクトリ) に CSV ファイルをアップロードします。https://eventbridge.console.alibabacloud.com/<regionId>/event-bus/DATAWORKS_TRIGGER_FOR_BUCKET_<OssBucketName>/event-tracingに移動して、最近のトリガーイベントのリストをクエリします。特定のイベントの [イベント詳細] をクリックして、そのトリガーメッセージ (workflow.triggerMessage の値) を表示することもできます。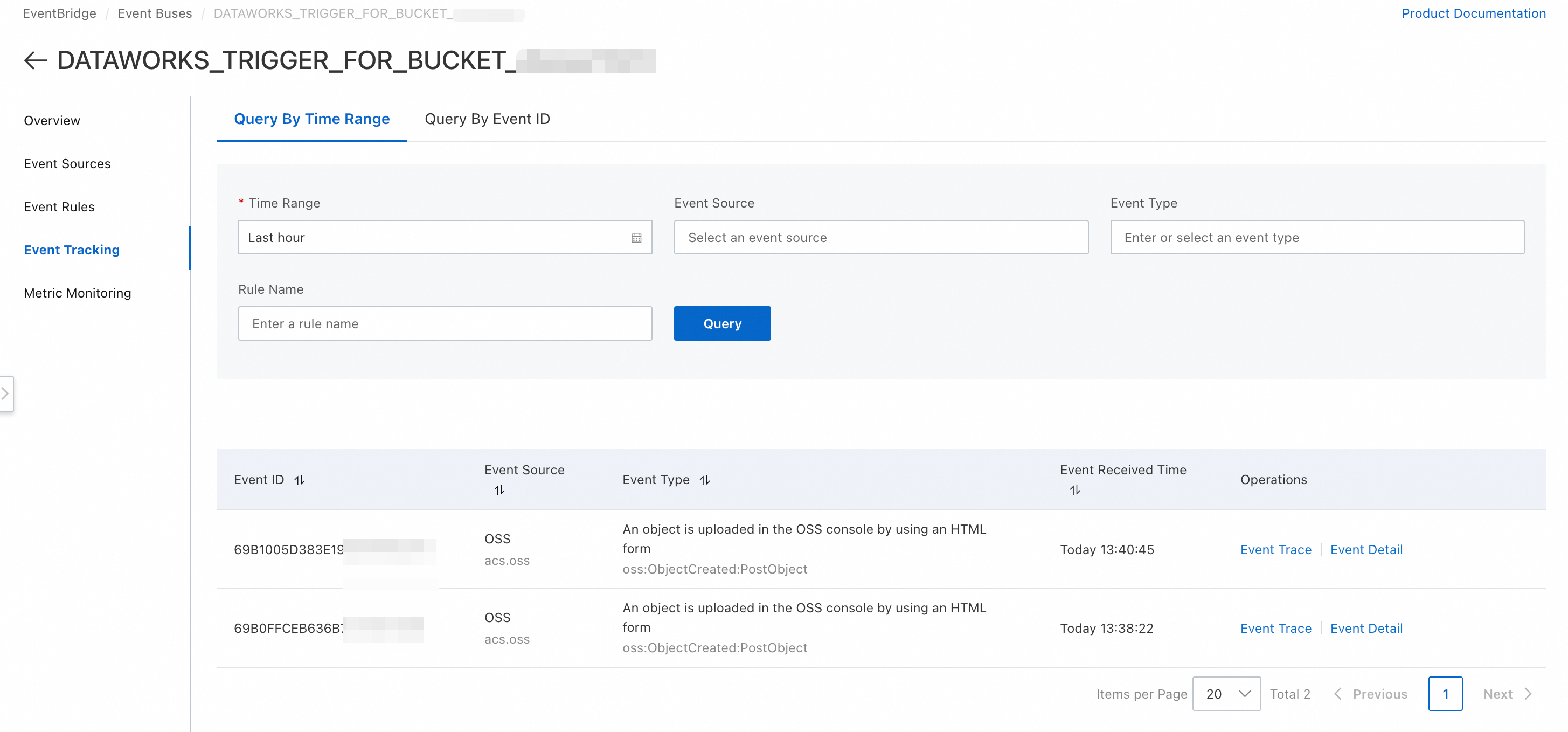
DataWorks で、[オペレーションセンター] > [手動トリガーノード O&M] > [手動タスク] > [トリガーワークフロー] に移動します。公開された
process_oss_file_workflowがリストに表示されます。
しばらくすると、新しいワークフローインスタンスが自動的にトリガーされ、実行されます。DataWorks の [オペレーションセンター] > [手動トリガーノード O&M] > [手動インスタンス] で表示できます。インスタンスをクリックしてログを表示し、ファイルパスが正しく処理されたことを確認します。
ベストプラクティス:べき等性の設計
ネットワークの変動などの要因により、OSS イベントが複数回配信される可能性があります。重複したデータ処理を防ぐため、ビジネスロジックにべき等性を実装することを推奨します。一般的なアプローチは、ファイルを処理する前に MaxCompute テーブルなどのレコードテーブルを確認することです。ファイルの ETag または一意のパスを識別子として使用し、すでに処理されている場合はファイルをスキップします。
シナリオ 2:ApsaraMQ for Kafka メッセージの処理
目的:Kafka トピックを監視してユーザーの行動ログを取得します。新しいメッセージが到着したときにワークフローをトリガーし、その内容に基づいて異なるロジックを実行します。
ステップ 1:Kafka トリガーの作成
[オペレーションセンター] > [テナントスケジュール設定] > [トリガー管理] に移動し、[トリガーの作成] をクリックします。
以下のパラメーターを設定します。
[トリガー名]:
kafka_user_action_trigger。トリガーイベントタイプ: [ApsaraMQ for Kafka] を選択します。
[Kafka インスタンス] と [トピック]:監視したいインスタンスとトピックを選択します。
ConsumerGroupId:[クイック作成] を選択することをお勧めします。 システムは、他のアプリケーションとの競合を避けるために、コンシューマーグループ ID を自動的に生成します。
[キー] (オプション):メッセージキーを指定できます。キーが完全に一致するメッセージのみがワークフローをトリガーします。
[OK] をクリックします。
ステップ 2:ワークフローの作成と関連付け
「クイックスタート:手動トリガーワークフローの作成」の手順に従って、
handle_user_action_workflowという名前のトリガーワークフローを作成します。ワークフローキャンバスの右側にある [プロパティ] パネルで、[スケジュールポリシー] を選択します。
[トリガー] ドロップダウンリストから、先ほど作成した
kafka_user_action_triggerを選択します。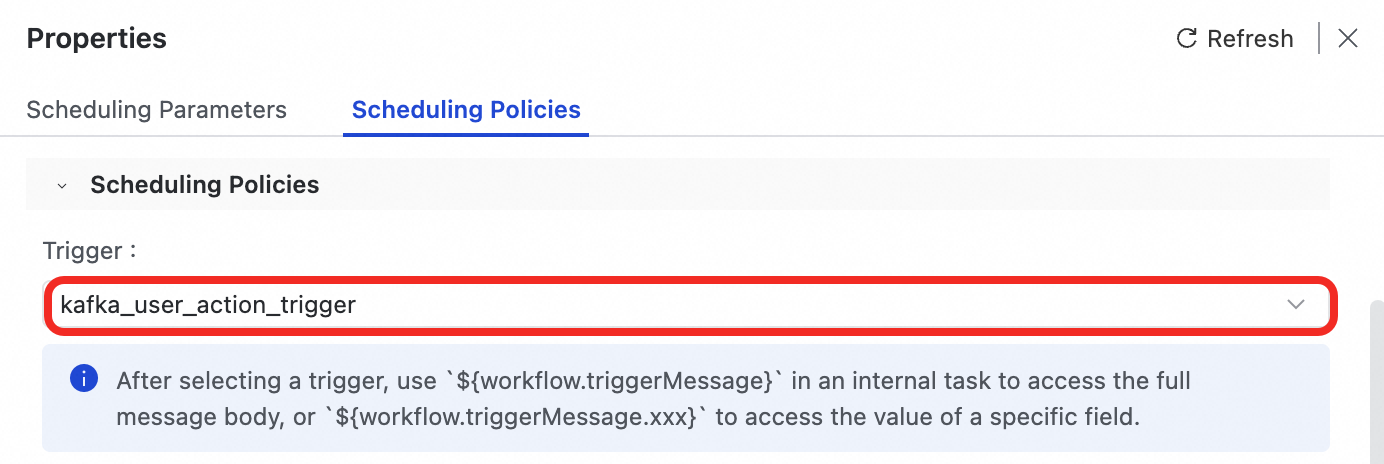
(重要) メッセージが高い頻度で到着する可能性があるため、[最大並列インスタンス数] を設定することを推奨します。たとえば、値を
100に設定して、メッセージの急増がスケジュールリソースを圧迫するのを防ぎます。
ステップ 3:ノードの開発とネストされた JSON の解析
Kafka メッセージの value フィールドが、{"user_id": "1001", "action_type": "login", "timestamp": 1688888888} という形式の JSON 文字列であると仮定します。
ツールバーで [+ ノードの追加] をクリックしてノードリストを開きます。左側のノードタイプリストから Python ノードをキャンバスにドラッグします。
次のコードを入力してメッセージを解析します。
valueフィールドは文字列であるため、コード内で 2 回目の JSON 解析を実行する必要があります。import json # 1. 組み込み変数を使用して、Kafka メッセージから JSON エンコードされた文字列である 'value' フィールドを取得します。 message_value_str = '${workflow.triggerMessage.value}' print(f'Received raw message value string: {message_value_str}') try: # 2. 文字列を Python の辞書に解析します。 message_data = json.loads(message_value_str) user_id = message_data.get("user_id") action_type = message_data.get("action_type") print(f"Successfully parsed message. User ID: {user_id}, Action: {action_type}") # 3. action_type に基づいて異なるビジネスロジックを実行します。 if action_type == 'login': # o.run_sql(f"INSERT OVERWRITE TABLE user_login_record PARTITION(ds='{bizdate}') VALUES ('{user_id}');") print("Processing login action...") elif action_type == 'purchase': print("Processing purchase action...") else: print("Unknown action type.") except json.JSONDecodeError as e: print(f"Error decoding JSON: {e}") # 専用のログテーブルにエラーメッセージを書き込むなど、例外処理ロジックを追加します。 raise e # 例外を再発生させてノードを失敗としてマークし、トラブルシューティングに役立てます。
ステップ 4:デバッグと公開
デバッグ:
ワークフローキャンバスに戻り、[実行]
ボタンをクリックします。[トリガーメッセージ本文] 入力ボックスに、シミュレートされた Kafka イベントを貼り付けます。
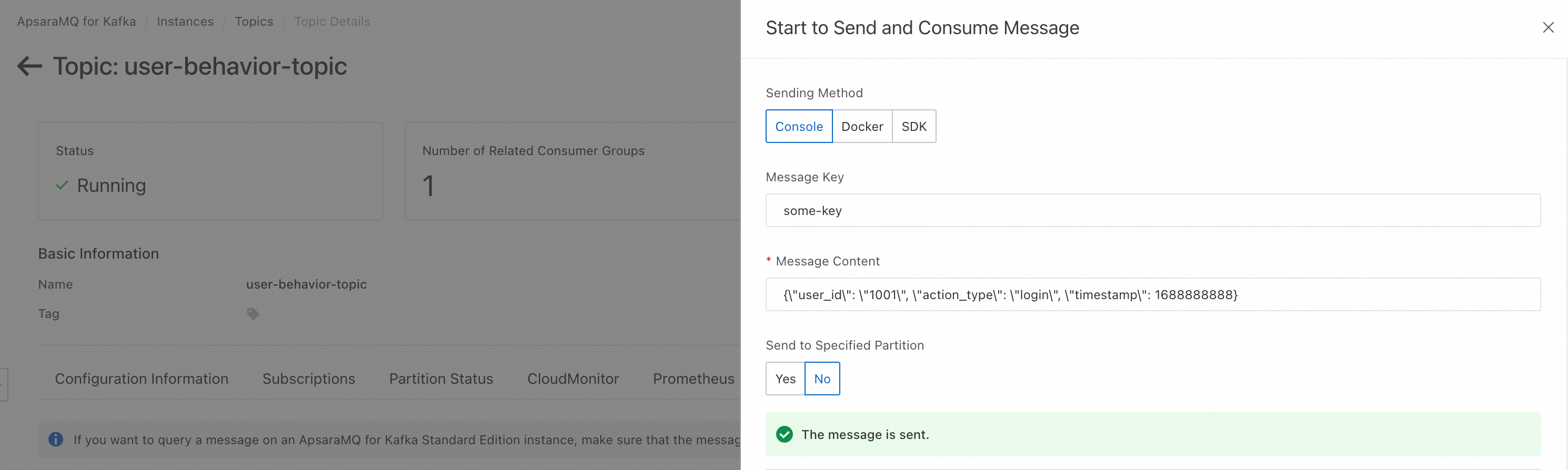
valueフィールドはエスケープされた JSON 文字列であることに注意してください。{ "topic": "user-behavior-topic", "key": "some-key", "value": "{\"user_id\": \"1001\", \"action_type\": \"login\", \"timestamp\": 1688888888}" }実行してログを確認し、Python ノードが
user_idとaction_typeの値を正しく解析することを確認します。
公開:デバッグが成功したら、ワークフローを本番環境に公開します。
ステップ 5:本番環境での検証
設定した Kafka トピックに正しい形式のメッセージを送信します。
DataWorks で、[オペレーションセンター] > [手動トリガーノード O&M] > [手動タスク] > [トリガーワークフロー] に移動します。公開された
handle_user_action_workflowがリストに表示されます。
オペレーションセンター > [手動でトリガーされたノード O&M] > [手動インスタンス] > [トリガーされたワークフローインスタンス] で、新しいワークフローインスタンスがトリガーされたかどうかを監視し、その実行ログを確認します。

ベストプラクティス:同時実行数と順序性
同時実行制御:メッセージの急増に対応するために、常に適切な最大並列インスタンス数を設定してください。
順序保証:DataWorks のスケジューリングは、厳密なメッセージ処理順序を保証しません。同じユーザーまたはパーティションのメッセージが順序通りに実行されることを保証する必要がある場合は、ビジネスコード内で分散ロック (たとえば、Redis や MaxCompute を使用) を実装する必要があります。または、Flink のようにパーティションごとの順序付き消費を保証する計算エンジンに処理ロジックを委任することもできます。
コア設計と構成
ワークフローオーケストレーション
トリガーワークフローのオーケストレーションは、スケジュールワークフローのオーケストレーションと似ています。詳細については、「ノードとワークフローのオーケストレーション」をご参照ください。
スケジュールパラメーター
ワークフローキャンバスの右側にある [プロパティ] パネルで、ワークフローのグローバルパラメーターを設定できます。その中のすべてのノードはこれらのパラメーターを参照できます。
参照構文:ノードコード内で、
${workflow.parameter_name}形式を使用してワークフローパラメーターを参照します。パラメーターの優先度:DataWorks のパラメーターには階層的な上書き関係があります。優先順位は、ノードパラメーター > ワークフローパラメーターです。
パラメーターの詳細については、「パラメーターの設計とフロー」をご参照ください。
スケジュールポリシー
複数のワークフローが同時にトリガーされ、リソースのボトルネックが発生した場合、[優先度] と [優先度重み付けポリシー] を使用してリソーススケジューリングを管理し、最も重要なタスクが最初に実行されるようにします。
コアビジネスの継続性を確保:重要なビジネスワークフローに高い優先度を設定することで、重要でないワークフローよりも常に先に実行されるようにします。
クリティカルパスのランタイムを短縮:単一のワークフローインスタンス内で、[優先度重み付けポリシー] を使用してノードの実行順序に影響を与えることができます。たとえば、[下向き重み付け] ポリシーを使用すると、上流の依存関係が多いクリティカルパス上のノードは、より高い動的な重みを取得します。これにより、それらの実行が優先され、ワークフロー全体のランタイムが短縮されます。
パラメーター
説明
[優先度]
スケジューリングキューにおけるワークフローインスタンスの絶対的な優先度レベルを定義します。利用可能なレベルは 1、3、5、7、8 で、数値が大きいほど優先度が高くなります。優先度の高いタスクやワークフローは、常に優先度の低いものよりも先にスケジューリングリソースが割り当てられます。
[優先度重み付けポリシー]
同じ優先度レベル内で、個々のノード (タスク) の重みがどのように動的に計算されるかを定義します。重みが大きいノードが実行優先度を与えられます。
重み付けなし:すべてのノードは固定のベースライン重みを持ちます。
下向き重み付け:ノードの重みは動的に調整されます。依存する上流ノードが多いほど、その重みは高くなります。この戦略は、有向非巡回グラフ (DAG) のクリティカルパス上のノードの実行を優先するのに役立ちます。重みは次のように計算されます:
初期重み + すべての上流ノードの優先度の合計。
[最大並列インスタンス数]
同時実行制御とリソース保護のために、このワークフローが同時に実行できるインスタンスの最大数を制御します。この制限に達すると、新しくトリガーされたインスタンスは待機状態になります。これを [無制限] または最大 100,000 までのカスタム値に設定できます。
説明指定された制限がリソースグループの最大容量を超える場合、実際の同時実行数はリソースグループの物理的な制限によって決まります。
DataWorks の優先度システムは、階層的な上書きルールに従います:ランタイム指定 > ノードレベルの構成 > ワークフローレベルの構成。
ワークフローレベルの構成 (ベースライン):ワークフローの [スケジュールポリシー] パネルで構成され、すべてのノードのデフォルト設定として機能します。
ノードレベルの構成 (上書き):特定のノードの [プロパティ] > [スケジュールポリシー] パネルでより高い [優先度] を設定することで、ワークフローレベルの設定を上書きできます。
ランタイム指定 (一時的):[オペレーションセンター] で手動で実行をトリガーする際に、[ランタイムで優先度を上書き] スイッチを使用して優先度を指定できます。この構成は最高の優先度を持ち、現在の実行にのみ適用され、永続的な設定は変更されません。
O&M と管理
インスタンスのモニタリング:[手動インスタンス] ページ ([オペレーションセンター] > [手動トリガーノード O&M] にあります) で、すべてのトリガーされた、または手動で実行されたインスタンスの表示、再実行、終了、ログの確認ができます。
ワークフローのクローン:[ビジネスフロー] でワークフローを右クリックし、[クローン] を選択して、すべてのノードと依存関係を含む新しいワークフローにすばやくコピーします。詳細については、スケジュールワークフローの「ワークフローのクローン」をご参照ください。
バージョン管理:ワークフローキャンバスの右側にある [バージョン] パネルで、ワークフローの履歴バージョンを表示、比較、復元できます。詳細については、スケジュールワークフローの「バージョン管理」をご参照ください。
制限事項と注意事項
有効な環境:イベント駆動トリガーメカニズムは、ワークフローが本番環境 (オペレーションセンター) に公開された後にのみ有効になります。
ノード数:単一のワークフローは最大 400 ノードをサポートします。メンテナンスを簡素化するために、100 未満に保つことを推奨します。
同時実行数制限:最大並列インスタンス数は 100,000 ですが、実際の同時実行容量は購入したスケジューリングリソースグループの仕様によって制限されます。
ノードレベルのスケジューリング:ノードレベルでスケジューリングを構成する場合、優先度のみが構成できます。優先度重み付けポリシーはサポートされていません。
サポートされていないノードタイプ:EMR Spark Streaming、Flink SQL Streaming、Flink JAR Streaming、Flink Python Streaming、および依存関係チェックノードは、トリガーワークフローではサポートされていません。これらは独立したノードとしてのみ開発および実行できます。