DataWorks のバッチ全データベース同期機能を使用すると、データベース全体または特定のテーブルのスキーマとデータを、ソースから送信先へ同期できます。定期的なスケジュールでバッチによる完全同期または増分同期を実行でき、データ移行のための効率的なソリューションを提供します。このトピックでは、MySQL データベース全体を MaxCompute に移行する例を用いて、このタイプのタスクを設定するための一般的なワークフローについて説明します。
前提条件
データソースの準備
ソースと送信先のデータソースを作成します。データソースの設定方法の詳細については、「データソース管理」をご参照ください。
データソースがバッチ全データベース同期をサポートしていることを確認します。詳細については、「サポートされているデータソース」をご参照ください。
リソースグループ:サーバーレスリソースグループを購入し、設定します。
ネットワーク接続:リソースグループとデータソース間のネットワーク接続を確立します。
適用範囲
バッチ全データベース同期タスクは DataStudio と Data Integration の両方で設定できます。これらの機能は相互に連携しています。
一貫した設定:タスクを DataStudio とデータ統合のどちらで作成しても、設定インターフェイス、パラメーター設定、および基盤となる機能は同じです。
双方向同期:データ統合で作成されたタスクは、システムによって自動的に DataStudio の
data_integration_jobsディレクトリに同期され、ソースタイプ-送信先タイプのチャネルごとに分類されて一元管理されます。
同期タスクの設定
ステップ 1:同期タスクの作成
DataWorks コンソールにログインします。上部のナビゲーションバーで、目的のリージョンを選択します。左側のナビゲーションウィンドウで、 を選択します。表示されたページで、ドロップダウンリストから目的のワークスペースを選択し、[データ統合へ移動] をクリックします。
左側のナビゲーションウィンドウで Synchronization Task をクリックします。表示されたページで Create Synchronization Task をクリックし、タスク情報を設定します。
Data Source Type:
MySQL。Data Source Type:
MaxCompute。Specific Type:
バッチ全データベース。Synchronization Mode:同期ステップと完全・増分制御の設定は連動しています。これらの設定を組み合わせることで、さまざまな同期ソリューションを作成できます。詳細については、「完全・増分制御」をご参照ください。
Schema Migration:ソースと一致するデータベースオブジェクト (テーブル、フィールド、データ型など) を送信先に自動的に作成しますが、データは含まれません。
Full Synchronization (オプション):指定されたソースオブジェクト (テーブルなど) のすべての履歴データを、1 回の操作で送信先にコピーします。これは通常、初期データ移行や初期化に使用されます。
Incremental Sync (オプション):完全同期が完了した後、このステップでは増分条件に基づいて、ソースからの新しいデータを継続的にキャプチャし、送信先に同期します。
ステップ 2:データソースとランタイムリソースの設定
Source Data Source セクションで、ワークスペースから
MySQLデータソースを選択します。Destination セクションで、MaxComputeデータソースを選択します。Running Resources セクションで、同期タスクの Resource Group を選択し、Resource Group CU を割り当てます。リソース不足により同期タスクで OOM (Out of Memory) が発生した場合は、Resource Group CUs の使用量の値を適宜調整してください。
ソースと送信先の両方のデータソースが 接続チェック に合格することを確認します。
ステップ 3:同期計画の設定
1. ソースの設定
このステップでは、ソースデータベースとテーブルエリアから同期するテーブルを選択し、![]() アイコンをクリックして右側の選択済みエリアに移動します。
アイコンをクリックして右側の選択済みエリアに移動します。
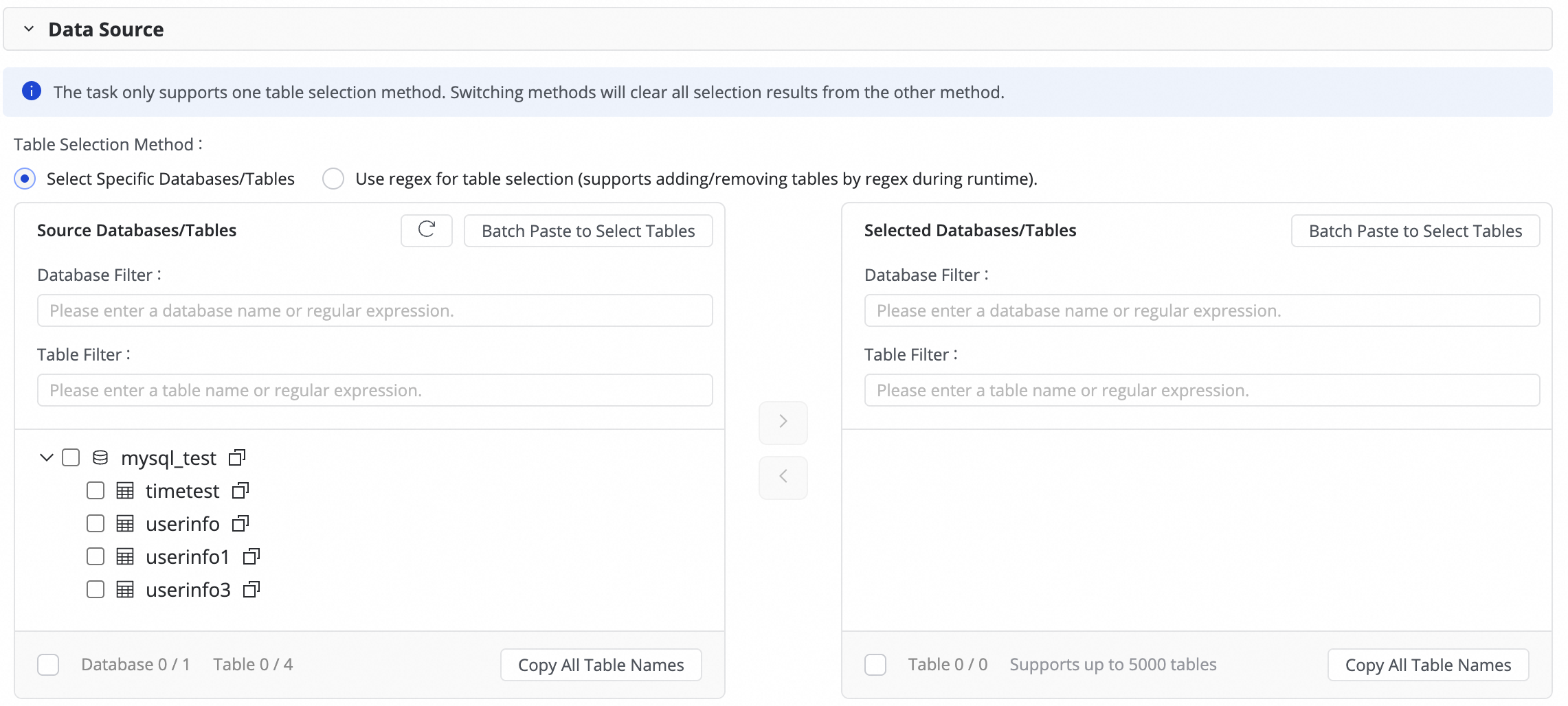
データベースやテーブルが多数ある場合は、Database Filtering または Table filtering を使用し、正規表現を設定して同期したいテーブルを選択できます。
2. 送信先の設定
Partition Initialization Configuration の横にある Configuration ボタンをクリックして、新しい送信先テーブルのデフォルトの初期パーティション設定を行います。ここで行った変更は、すべての新しい送信先テーブルのパーティション設定を上書きしますが、既存のテーブルには影響しません。
3. 計画設定 (完全・増分制御)
タスクの実行頻度を設定します。
完全同期または増分同期を選択した場合:タスクを1回限りまたは定期的に実行するかを選択できます。
完全同期と増分同期の両方を選択した場合:システムは組み込みモードの初回に1回限りの完全同期、その後は定期的な増分同期を使用します。このオプションは変更できません。
同期ステップ
完全・増分制御
データ書き込み動作
ユースケース
完全同期
1回限り
タスク開始後、タスクは 1 回の実行でソーステーブルのすべてのデータを送信先テーブルまたは指定されたパーティションに同期します。
データ初期化、システム移行。
定期的
設定されたスケジューリング周期に基づき、タスクはソーステーブルのすべてのデータを送信先テーブルまたは指定されたパーティションに定期的に同期します。
データ照合、T+1 完全スナップショット。
増分同期
1回限り
タスクが開始されると、「増分条件」に基づいて、指定されたパーティションに増分データを 1 回同期します。
特定のバッチデータを手動で修復。
定期的
タスク開始後、タスクは設定されたスケジューリング周期と増分条件に基づいて、指定されたパーティションに増分データを定期的に同期します。
日次 ETL、SCD (Slowly Changing Dimensions) テーブルの構築。
完全同期 & 増分同期
(組み込みモード、選択不可)
初回実行:1 回限りのスキーマ初期化と履歴データの完全同期を自動的に実行します。
後続の実行:設定されたスケジューリング周期と増分条件に基づいて、タスクは指定されたパーティションに増分データを定期的に同期します。
ワンクリックでのデータウェアハウジングまたはデータレイクへの取り込み。
説明バッチ全データベース同期では、システムは公開後すぐに生成方式を使用して定期スケジュールのインスタンスを生成します。詳細については、「インスタンス生成方式:公開後すぐに生成」をご参照ください。
Value assignment ステップでパーティションの生成方法を定義できます。定数を使用するか、システムで事前定義された変数や定期スケジュールパラメーターを使用してパーティションを動的に生成できます。
スケジューリング周期、増分条件、およびパーティション生成方法の設定は相互に関連しています。詳細については、「6. 増分条件の設定」をご参照ください。
定期スケジュールパラメーターを設定します。
タスクに定期的な同期が含まれる場合は、Scheduling Parameters for Periodical Scheduling をクリックして設定します。これらのパラメーターを使用して、送信先テーブルマッピングの増分条件と値の割り当てを設定します。
4. 送信先テーブルマッピング
このステップでは、ソーステーブルと送信先テーブル間のマッピングルールを定義し、定期スケジュールと増分条件を使用してデータ書き込み方法を指定します。

操作 | 説明 | ||||||||||||
マッピングの更新 | システムは選択したソーステーブルを自動的にリストアップしますが、送信先テーブルの特定のプロパティを適用するにはマッピングを更新する必要があります。
| ||||||||||||
フィールドデータ型のマッピングを編集 (オプション) | システムは、ソースと送信先のフィールド型間にデフォルトのマッピングを提供します。テーブルの右上隅にある Edit Mapping of Field Data Types をクリックして、フィールド型のマッピングをカスタマイズできます。設定後、Apply and Refresh Mapping をクリックします。 フィールド型のマッピングを編集する際は、型変換ルールが有効であることを確認してください。そうでない場合、型変換エラーがダーティデータを生成し、タスクの失敗を引き起こす可能性があります。 | ||||||||||||
送信先テーブル名のマッピングルールをカスタマイズ (オプション) | システムには、テーブル名を生成するためのデフォルトルールがあります:
この機能は、以下のユースケースをサポートしています:
| ||||||||||||
送信先データベース名のマッピングルールをカスタマイズ (オプション) | Hologres などの一部の送信先データソースタイプでは、送信先データベースのマッピングルールを定義できます。設定方法は送信先テーブル名のマッピングルールをカスタマイズと同様です。 | ||||||||||||
送信先スキーマ名のマッピングルールをカスタマイズ (オプション) | Hologres などの一部の送信先データソースタイプでは、送信先スキーマのマッピングルールを定義できます。設定方法は送信先テーブル名のマッピングルールをカスタマイズと同様です。 | ||||||||||||
送信先テーブルスキーマの編集 (オプション) | システムはソーステーブルスキーマに基づいて送信先テーブルスキーマを自動的に生成します。ほとんどの場合、手動での介入は不要です。必要に応じて、次のようにスキーマをカスタマイズできます:
| ||||||||||||
値の割り当て | ソーステーブルと送信先テーブルで名前が同じ場合、システムは標準フィールドを自動的にマッピングします。パーティションフィールドと新しく追加されたフィールドについては、手動で値を割り当てる必要があります。次の手順に従ってください:
テーブルフィールドとパーティションフィールドの Value Type を使用して、定数と変数を割り当てることができます。サポートされているモードは次のとおりです:
システムは、実行時に変数と定期スケジュールパラメーターの両方を日付固有の値に自動的に置き換えます。 | ||||||||||||
ソースシャーディング列の設定 | ソースシャーディング列のドロップダウンリストから、ソーステーブルのフィールドを選択するか、Disable を選択できます。このフィールドは、同期タスクを複数のサブタスクにシャーディングし、データの同時バッチ読み取りを可能にします。 テーブルのプライマリキーをソースシャーディング列として使用することを推奨します。文字列、浮動小数点、日付型はサポートされていません。 ソースシャーディング列は、ソースが MySQL の場合にのみ利用可能です。 | ||||||||||||
詳細パラメーターの設定 | 各サブタスクに対して [writer 設定] と [ランタイム設定] を設定できます。これらのパラメーターは、タスクの遅延、他のタスクをブロックする過剰なリソース消費、またはデータ損失などの予期せぬ問題を避けるため、その目的を完全に理解している場合にのみ変更してください。 | ||||||||||||
テーブルタイプ | MaxCompute は標準テーブル、PK Delta テーブル、Append Delta テーブルをサポートしています。送信先テーブルがまだ作成されていない場合、送信先テーブルスキーマを編集する際にテーブルタイプを選択できます。既存のテーブルのタイプは変更できません。 Delta テーブルの詳細については、「Delta テーブル」をご参照ください。 |
 アイコンをクリックし、Manually enter と Built-in Variable の値を組み合わせて送信先テーブル名を生成できます。変数には、ソースデータソース名、ソースデータベース名、ソーステーブル名が含まれます。
アイコンをクリックし、Manually enter と Built-in Variable の値を組み合わせて送信先テーブル名を生成できます。変数には、ソースデータソース名、ソースデータベース名、ソーステーブル名が含まれます。





 アイコンをクリックして、フィールドを追加します。
アイコンをクリックして、フィールドを追加します。 アイコンにカーソルを合わせると、各変数の意味を確認できます。
アイコンにカーソルを合わせると、各変数の意味を確認できます。5. 定期スケジュール
増分同期を定期的に設定した場合、送信先テーブルの定期スケジュールを設定する必要があります。これには、Scheduling Frequency、Data Timestamp、Resource Group for Scheduling などの設定が含まれます。同期タスクのスケジューリング設定は、DataStudio のノードの設定と一貫しています。パラメーターの詳細については、「ノードのスケジューリング設定」をご参照ください。
1回限りの同期タスクに多数のテーブルが含まれる場合、タスクの滞留やリソース競合を防ぐために、スケジュールを設定する際に実行時間をずらすことを推奨します。
6. 増分条件
タスクが増分データを同期する必要がある場合、増分条件を設定する必要があります。この条件は、各スケジュール済みインスタンスがどのデータを同期するかを決定します。
機能と構文
機能:増分条件は、ソースデータをフィルタリングする
WHERE句です。構文:条件を設定する際は、
WHEREキーワードに続く条件式のみを入力してください。WHEREキーワード自体は含めないでください。
増分同期にスケジューリングパラメーターを使用する
定期的な増分同期を実装するには、増分条件でスケジューリングパラメーターを使用できます。たとえば、条件を
<span data-tag="ph" id="codeph_rtz_ohk_wy5"><code code-type="xCode" data-tag="code" id="68c36d2fd9h4l">STR_TO_DATE('${bizdate}', '%Y%m%d') <= columnName AND columnName < DATE_ADD(STR_TO_DATE('${bizdate}', '%Y%m%d'), INTERVAL 1 DAY)として設定することで、前日に生成されたデータを同期できます。特定のパーティションに書き込む
増分条件と送信先テーブルのパーティションフィールドを組み合わせることで、各バッチの増分データを正しいパーティションに書き込むことができます。
たとえば、増分条件が前のステップで説明したように設定されている場合、パーティションフィールドを
ds=${bizdate}に設定し、送信先テーブルを日次でパーティション分割できます。これにより、各日次インスタンスはソースから対応する日付のデータのみを同期し、同じ名前の送信先パーティションに書き込みます。
増分条件の時間範囲、パーティション生成の時間間隔、および定期スケジュールのスケジューリング周期を適切に組み合わせることで、ビジネスロジックと物理パーティションを厳密に整合させた、自動化された T+n 増分 ETL パイプラインを構築できます。
ステップ 4:詳細設定の構成
詳細パラメーター
詳細パラメーターを変更してタスクを微調整し、カスタムの同期要件を満たすことができます。
ページの右上隅にある [詳細パラメーターの設定] をクリックして、詳細パラメーター設定ページを開きます。
画面のプロンプトに従ってパラメーター値を変更します。各パラメーターにはその機能の説明が含まれています。
AI を使用して設定を支援することもできます。タスクの同時実行数の調整など、自然言語で命令を入力すると、AI モデルが推奨パラメーター値を生成します。その後、AI が生成したパラメーターを承認または拒否できます。
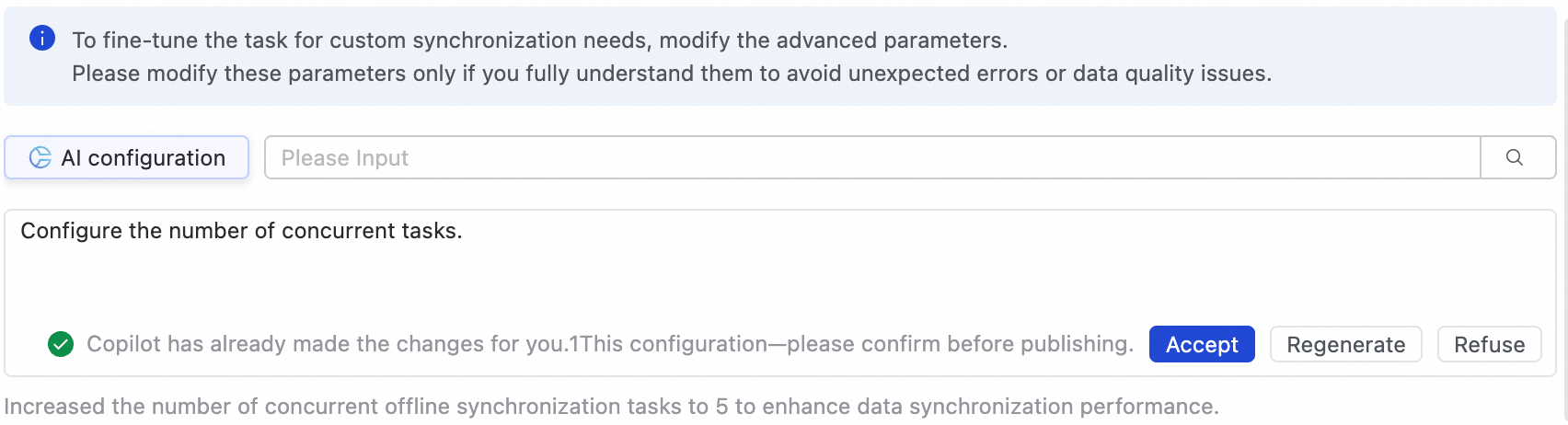
これらのパラメーターは、タスクの遅延、他のタスクをブロックする過剰なリソース消費、またはデータ損失などの予期せぬ問題を避けるため、その目的を完全に理解している場合にのみ変更してください。
エンジンパラメーター
エンジンパラメーターは通常の設定では構成する必要はありません。必要な場合は、専門家の指導の下でのみ使用してください。サポートが必要な場合は、テクニカルサポートにお問い合わせください。
ステップ 5:タスクのデプロイと実行
設定が完了したら、ページ下部の Save をクリックします。
バッチ全データベース同期タスクは直接デバッグできません。Operation Center にデプロイして実行する必要があります。したがって、新規または編集したタスクは、変更を適用するために Deploy する必要があります。
タスクをデプロイする際に Start immediately after deployment を選択すると、タスクはデプロイされるとすぐに実行を開始します。そうでない場合は、デプロイ後、 ページに移動し、[操作] 列からタスクを手動で開始する必要があります。
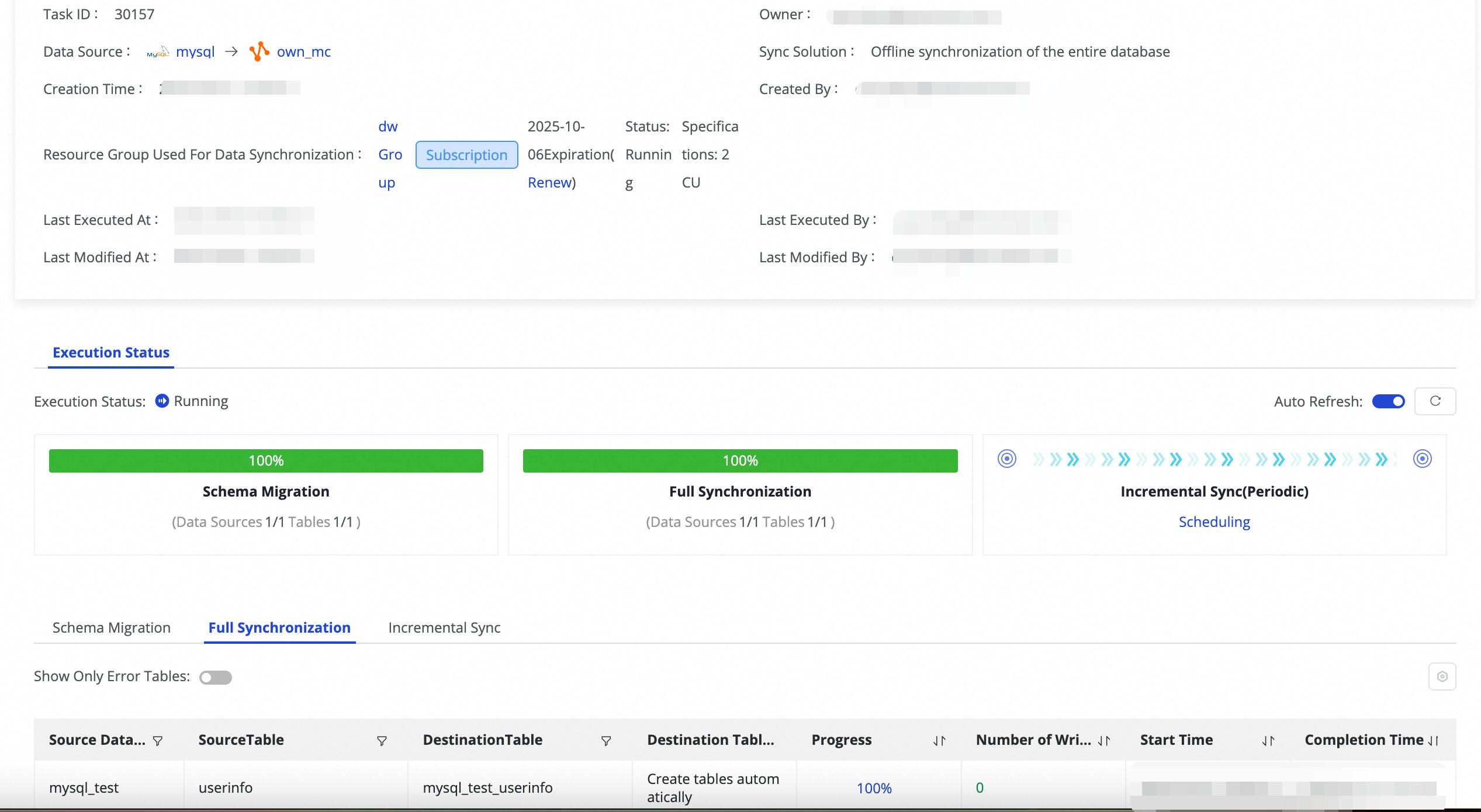
Tasks リストで、タスクの Name/ID をクリックして詳細な実行情報を表示します。
ステップ 6:アラートルールの設定
オペレーションセンターで、バッチ全データベース同期タスクに対応するサブタスクのアラートルールを設定する必要があります。
ページで、対象タスクの Task ID を見つけてコピーします。
で、タスク ID を使用して対応するサブタスクを見つけます。たとえば、タスク ID が
34862の場合、増分同期サブタスクはoffline_odps_cyc_sync_mysql_test_timetest_to_mysql_test_timetest_34862のような名前になることがあります。そのタスクの [操作] 列で、 をクリックしてルール管理ページを開きます。Create Custom Rule をクリックし、Rule Object、Trigger Method、および Alert Details を設定します。詳細については、「ルール管理」をご参照ください。
Rule Object フィールドでサブタスク ID を検索して対象タスクを見つけ、アラートを設定できます。
同期タスクの管理
タスクの編集
ページで、編集したいタスクを見つけます。Operation 列で More をクリックし、次に Edit をクリックします。編集手順は初期設定手順と同じです。
実行中でないタスクについては、設定を変更し、保存してからデプロイして変更を適用できます。
実行中のタスクを編集し、Start immediately after deployment を選択せずにデプロイした場合、元のアクションボタンは Apply Updates に変わります。本番環境に変更を適用するには、このボタンをクリックする必要があります。
[更新を適用] をクリックすると、システムは変更された内容に対して停止、デプロイ、再起動の 3 段階のプロセスを実行します。
テーブルを追加した場合:
更新を適用すると、システムは新しいテーブルの同期サブタスクを追加します。このサブタスクのスキーマ移行と1回限りの完全同期はすぐに開始されます。その後、増分同期はスケジュールに従って実行されます。
送信先テーブルを切り替えた場合 (古いテーブルを削除して新しいテーブルを追加するのと同じ):
更新を適用すると、システムは古いテーブルのサブタスクを削除し、新しいテーブルのサブタスクを生成します。新しいサブタスクのスキーマ移行と1回限りの完全同期はすぐに開始されます。その後、新しいタスクはスケジュールに従って増分同期を進めます。
その他の情報を変更した場合:
テーブルのスキーマ移行と1回限りの完全同期は影響を受けません。更新された設定は新しい増分同期インスタンスに適用されます。以前に生成されたインスタンスには影響しません。
このプロセスは、変更されていないテーブルに影響を与えたり、再実行したりすることはありません。
タスクの表示
同期タスクを作成した後、[同期タスク] ページで作成されたタスクのリストとその基本情報を表示できます。

[操作] 列では、同期タスクを 開始 または 停止 できます。[その他] メニューでは、[編集] や View などの他の操作を実行できます。
実行中のタスクについては、Execution Overview セクションでその基本ステータスを確認できます。また、概要エリアをクリックして実行詳細を表示することもできます。
割り当てと制限事項
デバッグの制限:バッチ全データベース同期タスクは、データ統合または DataStudio インターフェイスで直接デバッグすることはできません。タスクを実行するには、オペレーションセンターにデプロイする必要があります。
シャーディング列の制限:ソースシャーディング列の設定機能は、現在ソースが MySQL の場合にのみサポートされています。シャーディング列のフィールドは数値型である必要があります。文字列、浮動小数点、日付型はサポートされていません。
スキーマ変更の制限:送信先テーブルスキーマの編集を行う際、列の名前を変更することはできません。既存の送信先テーブルについては、テーブルタイプを変更することはできません。
次のステップ
タスクが開始された後、タスク名をクリックして実行詳細を表示し、タスクの操作とチューニングを実行できます。
よくある質問
バッチ全データベース同期タスクに関するよくある質問については、「完全同期および増分同期タスクに関するよくある質問」をご参照ください。
その他の例
「バッチ全データベース同期のユースケース」をご参照ください。