DataWorks では、バッチ同期ノードは自動解析によるスケジューリング依存関係の追加をサポートしていません。ワークフローに、生成されたテーブルが子孫ノードの依存関係となるバッチ同期ノードが含まれている場合は、そのテーブルをバッチ同期ノードの出力に手動で追加する必要があります。これにより、子孫ノードがそのテーブルをクエリする際に、自動解析機能が正しい先祖ノードを識別できるようになります。
よくある落とし穴
バッチ同期ノードが生成されたテーブルを出力に追加しない場合、自動解析ではこのノードを検出できません。その結果、このテーブルを参照する SQL ノードをコミットしようとすると、システムからエラーが返されます。エラーメッセージは
The output name of the dependent ancestor node of the current node: test.table_1 does not exist. The current node cannot be committed. Make sure that the ancestor node that has this output name has been committed! で、エラーコードは 1201111368 です。このエラーは、子孫ノードで自動解析された上流の依存関係が、先祖であるバッチ同期ノードのいずれの出力とも一致しないために発生します。詳細については「エラー分析」をご参照ください。このエラーを防ぐには、次のいずれかの方法でスケジューリング依存関係を設定してください。
方法 1:生成されたテーブルをノードの出力に手動で追加
このエラーを回避するには、子孫ノードで解析された上流の依存関係が、先祖ノードの出力に追加されていることを確認してください。この操作を行うには、バッチ同期ノードのスケジューリング設定ページに移動し、生成されたテーブルをノードの出力に手動で追加します。ノードの [出力] の入力フィールドに、
test.table_1 などの生成されたテーブル名を入力し、[追加] をクリックします。テーブルが出力リストに追加され、追加方法は [手動で追加] と表示されます。方法 2:ノード名とテーブル名の一致
この方法は次のとおりです。
- バッチ同期ノードを作成すると、DataWorks は
projectname.nodename形式で Output を自動生成します。 - SQL ノードがバッチ同期ノードの生成したテーブルを参照すると、DataWorks は
projectname.tablename形式で SQL ノードの Parent Nodes を自動生成します。 - エラーを防ぐには、SQL ノードの Parent Nodes の名前が、バッチ同期ノードの Output の名前と一致していることを確認してください。
説明
projectname.nodename という名前で自動生成される Output は、ノードの作成と同時に作成されます。ノード作成後にノード名を変更しても、この projectname.nodename の Output 名は変更されません。この方法は、バッチ同期ノードを新規に作成する場合にのみ有効です。既存ノードの名前変更によって名前を一致させようとしても機能しません。エラー分析
バッチ同期ノードを含む一般的なワークフローを例に説明します。次の表は、ノード作成と依存関係設定のプロセスをまとめたものです。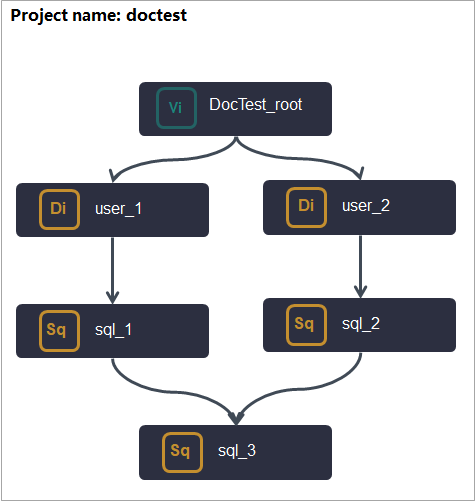
これらの手順を完了してノードをコミットする際に、自動解析がサポートされていない点を考慮せず、生成されたテーブルをノードの Output に手動で追加しなかった場合、依存先の先祖ノードの出力が存在しないというエラーがシステムから報告されます。
| 手順 | 説明 | スケジューリング依存関係 |
| 1 | ワークフロー計画に基づいて必要なノードを作成します。 例えば、仮想ノード、バッチ同期ノード、MaxCompute ノードを作成します。 |
ノードを作成すると、DataWorks は各ノードに対して 2 つの Output 設定を自動生成します。1 つは projectname.nodename 形式の名前で、もう 1 つは _out が末尾に付加された名前です。例えば、バッチ同期ノード user_1 の場合、ノード作成後にシステムは次の出力を生成します。
|
| 2 | ノードを線で接続して、実行順序と依存関係を定義します。 | ワークフローページでノードを接続すると、DataWorks は接続に基づいて依存関係設定を自動的に追加します。 例えば、接続後、MaxCompute ノード sql_1 はバッチ同期ノード user_1 の子孫ノードになります。DataWorks は、 |
| 3 | 各ノードのタスクコードを開発します。 | ノードのコードを記述すると、DataWorks は I/O コマンドを自動解析し、対応する Output または Parent Nodes を追加します。 例えば、MaxCompute ノード sql_1 が、バッチ同期ノード user_1 が生成するテーブル |
このエラーが発生する理由は次のとおりです。
- バッチ同期ノード user_1 は自動解析をサポートしていません。そのため、生成されたテーブル table_1 は、user_1 ノードの Output に自動的に追加されません。つまり、user_1 ノードには
doctest.table_1という名前の出力は存在しません。 - 子孫ノード sql_1 では、自動解析により
projectname.tablename形式の名前を持つ Parent Nodes が追加されます。この例では、名前はdoctest.table_1です。しかし、doctest.table_1は user_1 の出力ではないため、この依存関係を user_1 のノード ID に一致させることができません。 - sql_1 ノードをコミットすると、システムは
doctest.table_1への上流の依存関係を検出します。この依存関係はノード ID に関連付けられていないため、システムは先祖ノードを見つけられず、依存先の先祖ノードの出力名が存在しないことを報告します。