Data Integration は、AnalyticDB for MySQL 3.0、ClickHouse、Hologres、MySQL、および PolarDB などのソースから MaxCompute へのデータベース全体のオフライン同期をサポートしています。このトピックでは、Hologres データベースから MaxCompute へのオフライン同期を例に、データベース全体のワンタイムオフライン同期を実行する方法について説明します。
前提条件
Serverless リソースグループまたはデータ統合専用リソースグループを購入済みであること。
Hologres データソースと MaxCompute データソースを作成済みであること。詳細については、「データソースの構成」をご参照ください。
リソースグループとデータソース間のネットワーク接続を確立済みであること。詳細については、「ネットワーク接続ソリューション」をご参照ください。
制限事項
この機能は、テナントレベルのスキーマ構文を使用する MaxCompute データソースをサポートしていません。
ソースデータの MaxCompute 外部テーブルへの同期はサポートされていません。
手順
I. 同期タスクタイプの選択
Data Integration ページに移動します。
DataWorks コンソールにログインします。上部のナビゲーションバーで、目的のリージョンを選択します。左側のナビゲーションウィンドウで、 を選択します。表示されたページで、ドロップダウンリストから目的のワークスペースを選択し、[Data Integration に移動] をクリックします。
左側のナビゲーションウィンドウで、[同期タスク] をクリックします。ページの上部で、[同期タスクの作成] をクリックします。次のように基本情報を構成します。
ソースと宛先:
Hologres→MaxCompute新しいタスク名: 同期タスクの名前を入力します。
同期タイプ:
オフラインデータベース。同期ステップ で、[フル同期] と [増分同期] を選択します。
II. ネットワークとリソースの構成
[ネットワークとリソースの構成] セクションで、同期タスクの [リソースグループ] を選択します。[タスクリソースの使用状況] で CU を割り当てることもできます。
[ソースデータソース] を
Hologresデータソースに、[宛先データソース] をMaxComputeデータソースに設定します。次に、[接続テスト] をクリックします。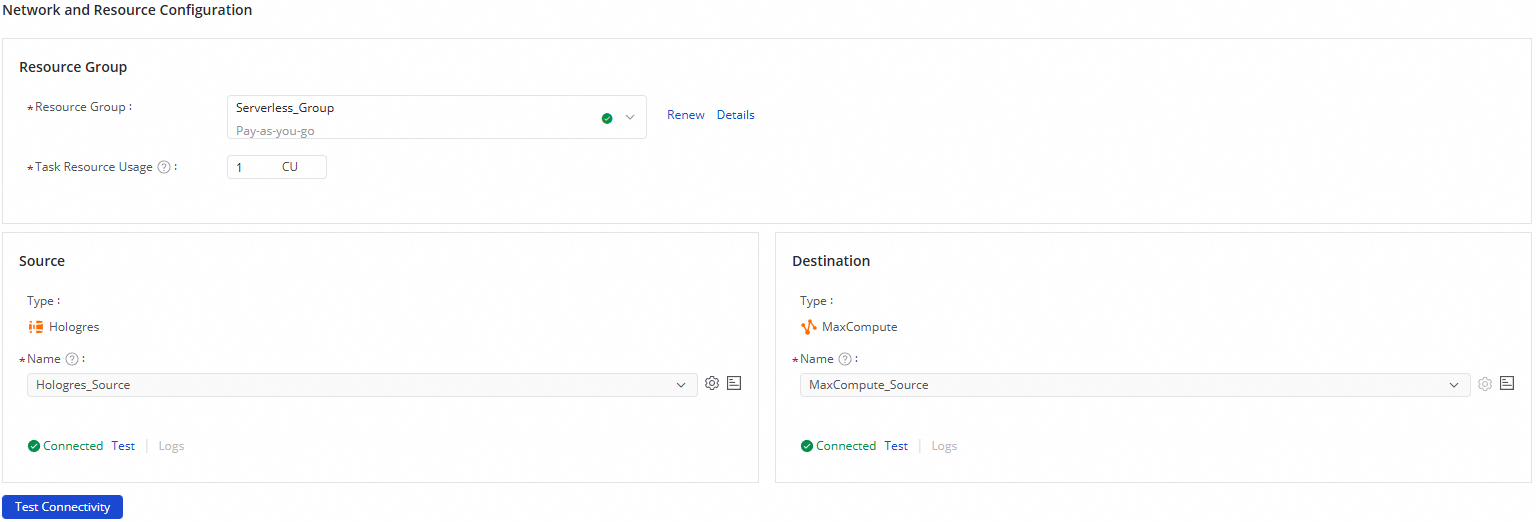
ソースと宛先のデータソースが接続されていることを確認したら、[次へ] をクリックします。
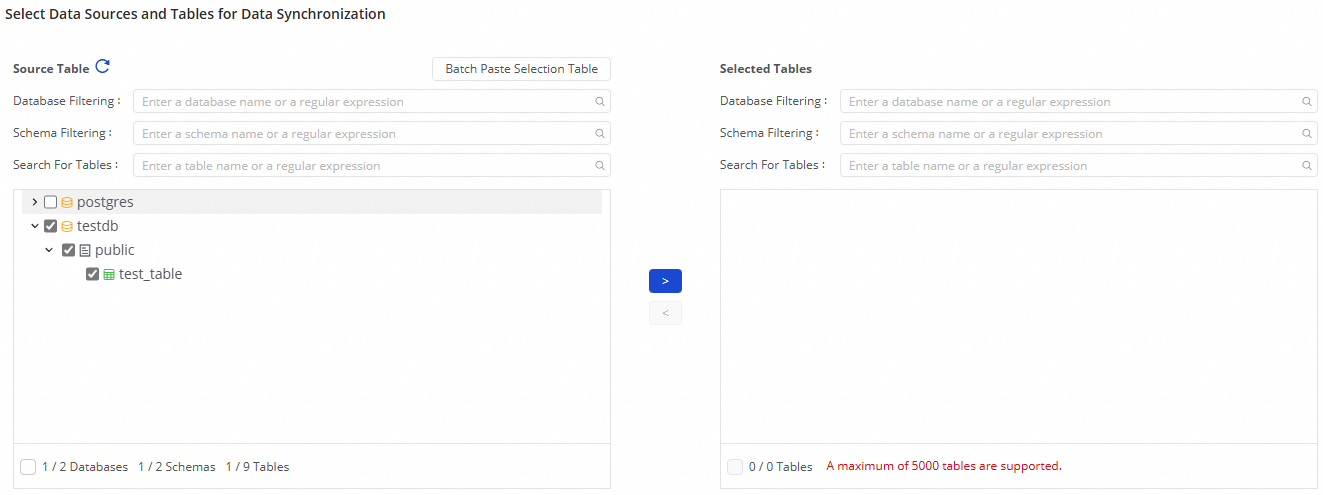
III. 同期するデータベースとテーブルの選択
[ソースデータベースとテーブル] エリアで、ソースデータソースから同期するテーブルを選択します。![]() アイコンをクリックして、テーブルを [選択したデータベースとテーブル] リストに移動します。
アイコンをクリックして、テーブルを [選択したデータベースとテーブル] リストに移動します。
IV. フル同期と増分同期の制御設定
タスクのフル同期と増分同期のタイプを構成します。
[同期ステップ] で [フル同期] と [増分同期] の両方を選択した場合、タスクはデフォルトでワンタイムフル同期と定期的な増分同期になります。この設定は変更できません。
[同期ステップ] で [フル同期] を選択した場合、タスクをワンタイムフル同期または定期的なフル同期に構成できます。
[同期ステップ] で [増分同期] を選択した場合、タスクをワンタイムまたは定期的な増分同期として構成できます。
説明以下の手順では、ワンタイムフル同期と定期的な増分同期タスクを例として使用します。
定期スケジュールパラメーターを構成します。
タスクを定期的に実行する場合は、[定期スケジュールパラメーター] をクリックします。
V. 宛先テーブルへのマッピング
前のステップで同期するテーブルを選択すると、このページに自動的に表示されます。宛先テーブルのステータスは「マッピングを更新する必要があります」です。ソーステーブルと宛先テーブル間のマッピングを定義する必要があります。これにより、ソーステーブルからデータを読み取り、宛先テーブルに書き込む方法が指定されます。次に、[マッピングの更新] をクリックして続行します。マッピングをすぐに更新するか、最初に宛先テーブルのルールをカスタマイズできます。
同期するテーブルを選択し、[一括マッピング更新] をクリックできます。マッピングルールが構成されていない場合、デフォルトのテーブル命名規則は
${SourceSchemaName}_${TableName}です。宛先に同じ名前のテーブルが存在しない場合は、自動的に作成されます。これは定期的なスケジュールであるため、そのプロパティを定義する必要があります。これらのプロパティには、[スケジューリングサイクル]、[スケジューリング時間]、および [スケジューリングリソースグループ] が含まれます。この同期タスクのスケジューリング構成は、データ開発のノードスケジューリング構成と同じです。詳細については、「ノードのスケジューリング」をご参照ください。
ソースデータをフィルタリングするために、[増分条件] に WHERE 句を指定します。WHERE キーワードではなく、句の内容のみを入力してください。定期的なスケジュールが有効になっている場合は、システムパラメーター変数を使用できます。
[カスタム宛先テーブル名マッピング] 列で、[編集] をクリックして宛先テーブルの命名規則をカスタマイズします。
組み込み変数と手動で入力した文字列を使用して、宛先テーブル名を作成できます。組み込み変数を編集することもできます。たとえば、ソーステーブル名にサフィックスを追加して宛先テーブル名を形成する新しいテーブル命名規則を作成できます。
1. フィールドタイプマッピングの編集
同期タスクは、デフォルトでソースフィールドタイプを宛先フィールドタイプにマッピングします。このマッピングをカスタマイズするには、テーブルの右上隅にある [フィールドタイプマッピングの編集] をクリックします。マッピングを構成した後、[適用してマッピングを更新] をクリックします。
2. 宛先テーブルスキーマの編集とフィールド値の割り当て
宛先テーブルのステータスが [作成予定] の場合、そのスキーマにフィールドを追加できます。次の手順に従ってください:
宛先テーブルにフィールドを追加します。
単一のテーブルにフィールドを追加するには、[ターゲットテーブル名] 列の
 ボタンをクリックします。
ボタンをクリックします。フィールドをバッチで追加するには、同期するすべてのテーブルを選択します。テーブルの下部で、 を選択します。
フィールドに値を割り当てます。次の操作を使用して、追加したフィールドに値を割り当てることができます。
単一のテーブルに値を割り当てるには: [宛先テーブルフィールドの割り当て] 列で、[構成] をクリックします。
バッチで値を割り当てるには、リストの下部で を選択して、複数の宛先テーブルにまたがる同一のフィールドに値を割り当てます。
説明定数または変数を割り当てることができます。
 アイコンをクリックして、割り当てモードを切り替えます。
アイコンをクリックして、割り当てモードを切り替えます。
3. 高度なパラメーターのカスタマイズ
タスクを詳細に制御するには、[高度なパラメーターのカスタマイズ] 列の [構成] をクリックします。
これらのパラメーターは、その機能を完全に理解している場合にのみ変更してください。設定が正しくないと、予期しないエラーやデータ品質の問題が発生する可能性があります。
VI. 高度なパラメーターの構成
同期タスクには、必要に応じて変更できるいくつかのパラメーターが用意されています。たとえば、接続の最大数を制限して、同期タスクが本番データベースに過度の圧力をかけるのを防ぐことができます。
これらのパラメーターは、その機能を完全に理解している場合にのみ変更してください。設定が正しくないと、予期しないエラーやデータ品質の問題が発生する可能性があります。
ページの右上隅にある [高度なパラメーター構成] をクリックして、高度なパラメーター構成ページに移動します。
[高度なパラメーター構成] ページで、パラメーター値を変更します。
VII. リソースグループの構成
ページの右上隅にある [リソースグループ構成] をクリックして、現在のタスクのリソースグループを表示または切り替えます。
VIII. 同期タスクの実行
構成が完了したら、ページの下部にある [構成の完了] をクリックします。
ページで、作成した同期タスクを見つけ、[アクション] 列の [開始] をクリックします。
[タスクリスト] で、タスクの [名前/ID] をクリックして実行の詳細を表示します。
IX. アラートの構成
タスクが実行されると、オペレーションセンターでスケジュールされたジョブが生成されます。タスクエラーによるデータ同期の遅延を防ぐために、同期タスクにアラームポリシーを設定できます。
[タスクリスト] で、実行中の同期タスクを見つけます。[アクション] 列で、 を選択してタスク編集ページを開きます。
[次へ] をクリックします。次に、ページの右上隅にある [アラーム構成] をクリックして、アラーム設定ページを開きます。
[スケジューリング情報] 列で、スケジュールされたジョブをクリックしてオペレーションセンターでタスク詳細ページを開き、[タスク ID] を取得します。
オペレーションセンターの左側のナビゲーションウィンドウで、 を選択して、ルール管理ページに移動します。
[カスタムルールの作成] をクリックし、[ルールオブジェクト]、[トリガーメソッド]、および [アラーム動作] を設定します。詳細については、「ルール管理」をご参照ください。
[ルールオブジェクト] フィールドで、取得したタスク ID を使用してターゲットタスクを検索し、アラートを設定します。
同期タスクの O&M
タスクの実行ステータスの表示
同期タスクを作成した後、同期タスクページで作成された同期タスクのリストとその基本情報を表示できます。

[アクション] 列では、同期タスクを [開始] または [停止] できます。[その他] の下で、[編集] や [表示] などの他の操作も実行できます。
実行中のタスクについては、[実行概要] セクションでそのステータスを表示できます。タスクの概要エリアをクリックして、実行の詳細を表示することもできます。
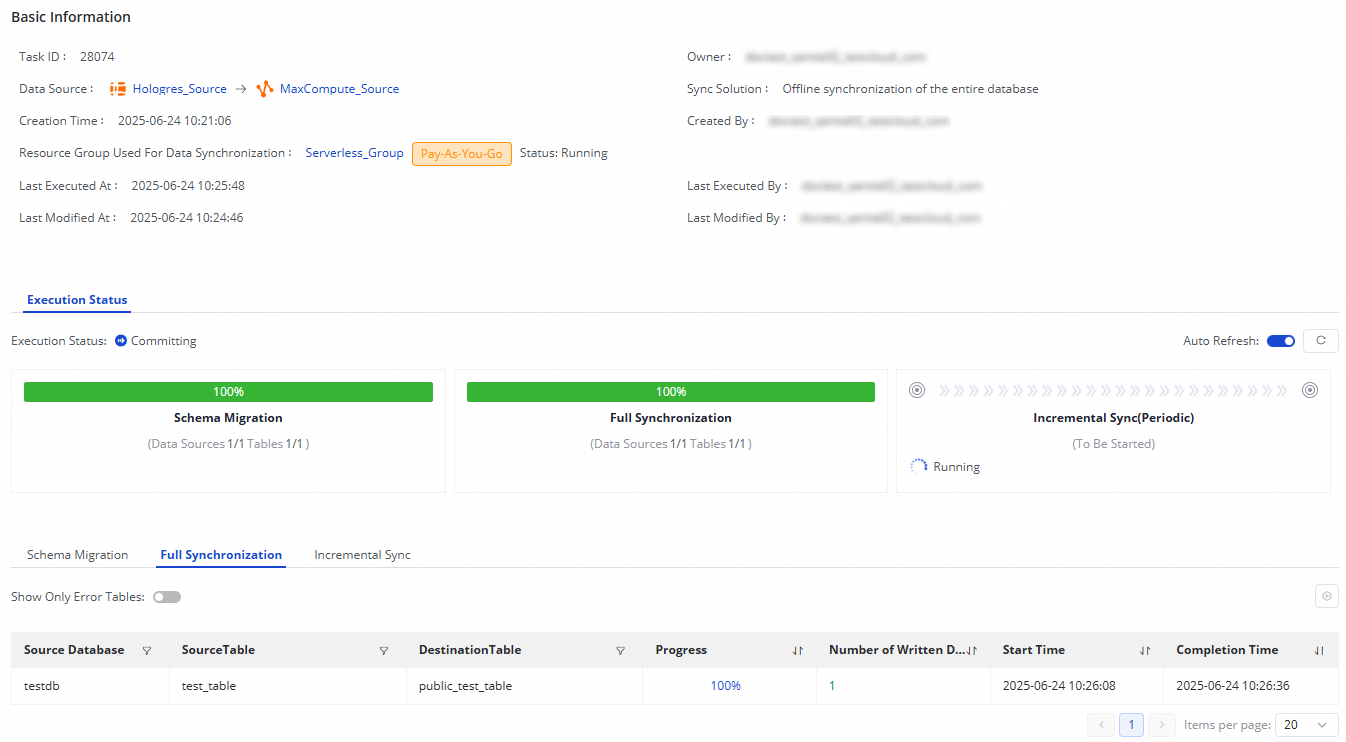
Hologres から MaxCompute へのデータベース全体のオフライン同期タスクの場合:
タスクの同期ステップが [フル同期] の場合、このセクションにはスキーマ移行とフル同期が表示されます。
タスクの同期ステップが [増分同期] の場合、スキーマ移行と増分同期のステップがここに表示されます。
タスクが [フル同期] と [増分同期] の両方を実行する場合、スキーマ移行、フル同期、および増分同期のステータスがここに表示されます。
タスクの再実行
[再実行] をクリックして、タスク構成を変更せずにタスクを再実行します。
効果: この操作は、ワンタイムタスクを再実行するか、定期タスクのプロパティを更新します。
テーブルを追加または削除してタスクを変更した後にタスクを再実行するには、タスクを編集して [完了] をクリックします。タスクのステータスは [更新の適用] に変わります。[更新の適用] をクリックすると、変更されたタスクの再実行がすぐにトリガーされます。
効果: 新しいテーブルのみが同期されます。以前に同期されたテーブルは再度同期されません。
タスクを編集 (たとえば、宛先テーブル名を変更したり、別の宛先テーブルに切り替えたり) して [完了] をクリックすると、タスクで利用可能な操作が [更新の適用] に変わります。[更新の適用] をクリックすると、変更されたタスクの再実行がすぐにトリガーされます。
効果: 変更されたテーブルが同期されます。変更されていないテーブルは再度同期されません。
データ開発シナリオ
下流のデータ依存関係があり、データ開発操作を実行する必要がある場合は、「ノードのスケジューリング」で説明されているように、ノードの上流と下流の依存関係を設定できます。対応する定期タスクノード情報は、[定期構成] 列で表示できます。
