このトピックでは、MySQL データベース全体から Hive へのオフラインデータ同期を実行する方法について説明します。この例では、MySQL をソースとして、Hive をターゲットとして使用します。
前提条件
サーバーレスリソースグループまたはデータ統合専用リソースグループを購入します。
MySQL データソースと Hive データソースを作成します。詳細については、「データソースの設定」をご参照ください。
リソースグループとデータソース間のネットワーク接続を確立します。詳細については、「ネットワーク接続ソリューションの概要」をご参照ください。
手順
1. 同期タスクのタイプを選択する
Data Integration ページに移動します。
DataWorks コンソールにログインします。上部のナビゲーションバーで、目的のリージョンを選択します。左側のナビゲーションウィンドウで、 を選択します。表示されたページで、ドロップダウンリストから目的のワークスペースを選択し、[データ統合へ] をクリックします。
左側のナビゲーションウィンドウで、[同期タスク] をクリックします。ページの上部で、[同期タスクの作成] をクリックしてタスク作成ページに移動します。次の基本情報を設定します。
ソースとターゲット:
MySQL→Hive新しいタスク名: 同期タスクの名前を入力します。
同期タイプ:
Entire Database Offline。同期ステップ: [フル同期] と [増分同期] を選択します。
2. ネットワークとリソースを設定する
[ネットワークとリソースの設定] セクションで、同期タスクの [リソースグループ] を選択します。[タスクリソース使用量] の CU 数を指定することもできます。
[ソースデータソース] を
MySQLデータソースに、[ターゲットデータソース] をHiveデータソースに設定します。次に、[接続テスト] をクリックします。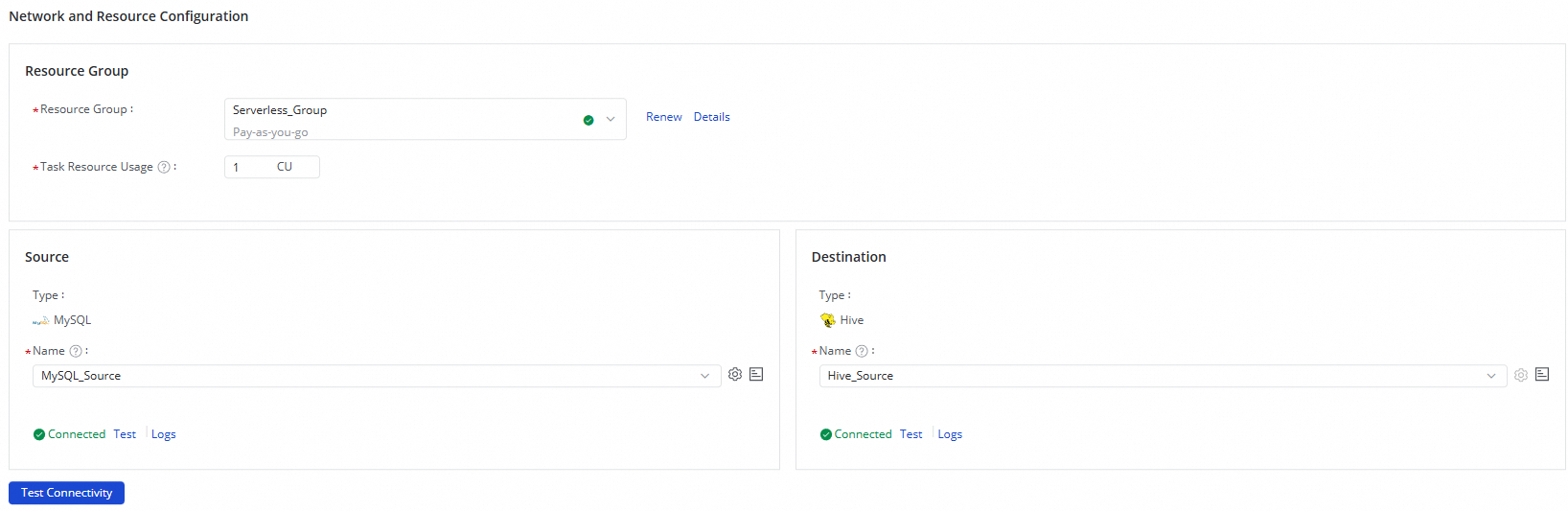
ソースとターゲットのデータソースの接続テストが成功したら、[次へ] をクリックします。
3. 同期するデータベースとテーブルを選択する
[ソーステーブル] エリアで、ソースデータソースから同期するテーブルを選択します。![]() アイコンをクリックして、テーブルを [選択したテーブル] リストに移動します。
アイコンをクリックして、テーブルを [選択したテーブル] リストに移動します。

4. ターゲットデータベースのプロパティを設定する
この操作は、Data Integration によって作成される新しいテーブルのスキーマに影響します。既存のテーブルのスキーマは影響を受けません。
新しいテーブルのストレージモード: [内部テーブル] または [外部テーブル] を選択して、新しいターゲットテーブルが内部テーブルか外部テーブルかを指定できます。
新しいテーブルのフォーマット: [parquet]、[orc]、または [txt] を選択して、新しいターゲットテーブルのストレージフォーマットを指定できます。
書き込みモード: 書き込み操作中にターゲットテーブルをクリアするか、既存データを保持するかを決定します。
パーティション初期化設定: 新しいテーブルの初期パーティション値を決定します。デフォルトでは、ハッシュパーティションのみが作成されます。設定ボタンをクリックして、この設定を変更できます。
5. フル同期と増分同期を設定する
タスクのフル同期と増分同期のタイプを設定します。
[同期ステップ] で [フル同期] と [増分同期] の両方を選択した場合、タスクはデフォルトでワンタイムのフル同期と定期的な増分同期になります。この設定は変更できません。
[同期ステップ] で [フル同期] を選択した場合、タスクを 1 回限りのフル同期または定期的なフル同期に構成できます。
[同期ステップ] で [増分同期] を選択した場合、タスクをワンタイムまたは定期的な増分同期として設定できます。
説明以下のステップでは、ワンタイムのフル同期と定期的な増分同期タスクを例として使用します。
定期的なスケジュールパラメーターを設定します。
タスクを定期的なスケジュールで実行したい場合は、[定期スケジュールパラメーター] をクリックします。
6. ターゲットテーブルのマッピングを設定する
前のステップで同期するテーブルを選択すると、このページに自動的に表示されます。ターゲットテーブルのステータスは「マッピングをリフレッシュする必要があります」です。ソーステーブルとターゲットテーブル間のマッピングを定義する必要があります。これにより、ソーステーブルからデータを読み取り、ターゲットテーブルに書き込む方法が指定されます。次に、[マッピングのリフレッシュ] をクリックして続行します。マッピングをすぐにリフレッシュするか、最初にターゲットテーブルのルールをカスタマイズすることができます。
同期するテーブルを選択し、[一括マッピングリフレッシュ] をクリックします。マッピングルールが設定されていない場合、システムはデフォルトの命名ルールをターゲットテーブルに適用します:
${SourceDatabaseName}_${TableName}。指定された名前のテーブルがターゲットに存在しない場合、自動的に作成されます。このタスクは定期的なスケジュールで実行されるため、そのスケジューリングプロパティを設定する必要があります。これらのプロパティには、[スケジューリングサイクル]、[有効日]、[実行をスキップ] が含まれます。この同期タスクのスケジューリング設定は、データ開発のノードスケジューリング設定と同じです。詳細については、「ノードのスケジューリング」をご参照ください。
選択した [同期ステップ] に基づいて、[増分条件] と [フル条件] を設定します。これらの条件は、ソースデータをフィルタリングするために WHERE 句を適用します。WHERE キーワードではなく、句の内容のみを入力してください。定期的なスケジュールを有効にする場合は、システムパラメーターを使用できます。
[カスタムターゲットデータベース名マッピング] 列で、[設定] をクリックしてターゲットデータベースの命名ルールをカスタマイズします。
組み込みの変数と手動で入力した文字列を使用して、ターゲットデータベース名を作成できます。組み込みの変数を編集することもできます。たとえば、ソースデータベース名にサフィックスを追加してターゲットデータベース名を形成する新しいデータベース命名ルールを作成できます。
[カスタムターゲットテーブル名マッピング] 列で、[編集] をクリックしてターゲットテーブルの命名ルールをカスタマイズします。
組み込みの変数と手動で入力した文字列を使用して、ターゲットテーブル名を作成できます。組み込みの変数を編集することもできます。たとえば、ソーステーブル名にサフィックスを追加してターゲットテーブル名を形成する新しいテーブル命名ルールを作成できます。
1. フィールドタイプのマッピングを編集する
同期タスクは、デフォルトでソースフィールドタイプをターゲットフィールドタイプにマッピングします。このマッピングをカスタマイズするには、テーブルの右上隅にある [フィールドタイプマッピングの編集] をクリックします。マッピングを設定した後、[適用してマッピングをリフレッシュ] をクリックします。
2. ターゲットテーブルのスキーマを編集し、フィールド値を割り当てる
ターゲットテーブルのステータスが [作成予定] の場合、そのスキーマにフィールドを追加できます。次のステップに従ってください:
ターゲットテーブルにフィールドを追加します。
単一のテーブルにフィールドを追加するには、[ターゲットテーブル名] 列の
 ボタンをクリックします。
ボタンをクリックします。バッチでフィールドを追加するには、同期するすべてのテーブルを選択します。テーブルの下部で、 を選択します。
フィールドに値を割り当てます。次の操作を使用して、追加したばかりのフィールドに値を割り当てることができます。
単一のテーブルに値を割り当てるには: [ターゲットテーブルフィールドの割り当て] 列で、[設定] をクリックします。
バッチで値を割り当てるには、リストの下部で を選択して、複数のターゲットテーブルにまたがる同一のフィールドに値を割り当てます。
説明定数または変数を割り当てることができます。
 アイコンをクリックして、割り当てモードを切り替えます。
アイコンをクリックして、割り当てモードを切り替えます。
3. 詳細パラメーターをカスタマイズする
タスクを詳細にコントロールするには、[高度なパラメーターのカスタマイズ] 列の [設定] をクリックします。
これらのパラメーターは、その機能を完全に理解している場合にのみ変更してください。誤った設定は、予期しないエラーやデータ品質の問題を引き起こす可能性があります。
4. ソースチャンキング列を設定する
ソースチャンキング列では、ドロップダウンリストからソーステーブルのフィールドを選択するか、[チャンキングしない] を選択できます。
7. 詳細パラメーターを設定する
同期タスクには、必要に応じて変更できるいくつかのパラメーターが用意されています。たとえば、接続の最大数を制限して、同期タスクが本番データベースに過度の負荷をかけるのを防ぐことができます。
これらのパラメーターは、その機能を完全に理解している場合にのみ変更してください。誤った設定は、予期しないエラーやデータ品質の問題を引き起こす可能性があります。
ページの右上隅にある [詳細パラメーター設定] をクリックして、詳細パラメーター設定ページに移動します。
[詳細パラメーター設定] ページで、パラメーター値を変更します。
8. リソースグループを設定する
ページの右上隅にある [リソースグループ設定] をクリックして、現在のタスクのリソースグループを表示または切り替えます。
9. 同期タスクを実行する
設定が完了したら、ページの下部にある [設定完了] をクリックします。
ページで、作成した同期タスクを見つけ、[アクション] 列の [開始] をクリックします。
[タスクリスト] で、タスクの [名前/ID] をクリックして実行詳細を表示します。
10. アラートを設定する
タスクが実行されると、オペレーションセンターでスケジュールされたジョブが生成されます。タスクエラーによるデータ同期の遅延を防ぐために、同期タスクにアラームポリシーを設定できます。
[タスクリスト] で、実行中の同期タスクを見つけます。[アクション] 列で、 を選択してタスク編集ページを開きます。
[次へ] をクリックします。次に、ページの右上隅にある [アラーム設定] をクリックして、アラーム設定ページを開きます。
[スケジューリング情報] 列で、スケジュールされたジョブをクリックしてオペレーションセンターでタスク詳細ページを開き、[タスク ID] を取得します。
オペレーションセンターの左側のナビゲーションウィンドウで、 を選択して、ルール管理ページに移動します。
[カスタムルールの作成] をクリックし、[ルールオブジェクト]、[トリガーメソッド]、[アラーム動作] を設定します。詳細については、「ルール管理」をご参照ください。
[ルールオブジェクト] フィールドで、取得したタスク ID を使用してターゲットタスクを検索し、アラートを設定します。
同期タスクの O&M
タスクステータスの表示
同期タスクを作成した後、同期タスクページで作成されたタスクのリストとその基本情報を表示できます。

[アクション] 列では、同期タスクを [開始] または [停止] できます。[その他] の下で、[編集] や [表示] などの他の操作を実行できます。
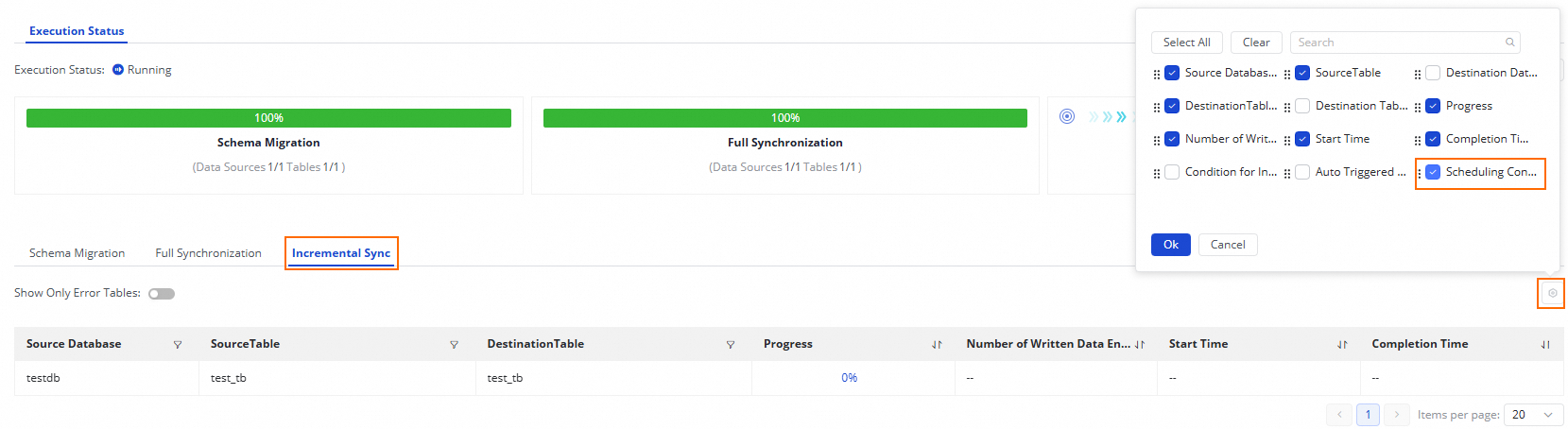
[実行概要] セクションでは、実行中のタスクの基本ステータスを表示し、対応するエリアをクリックして実行詳細を表示できます。
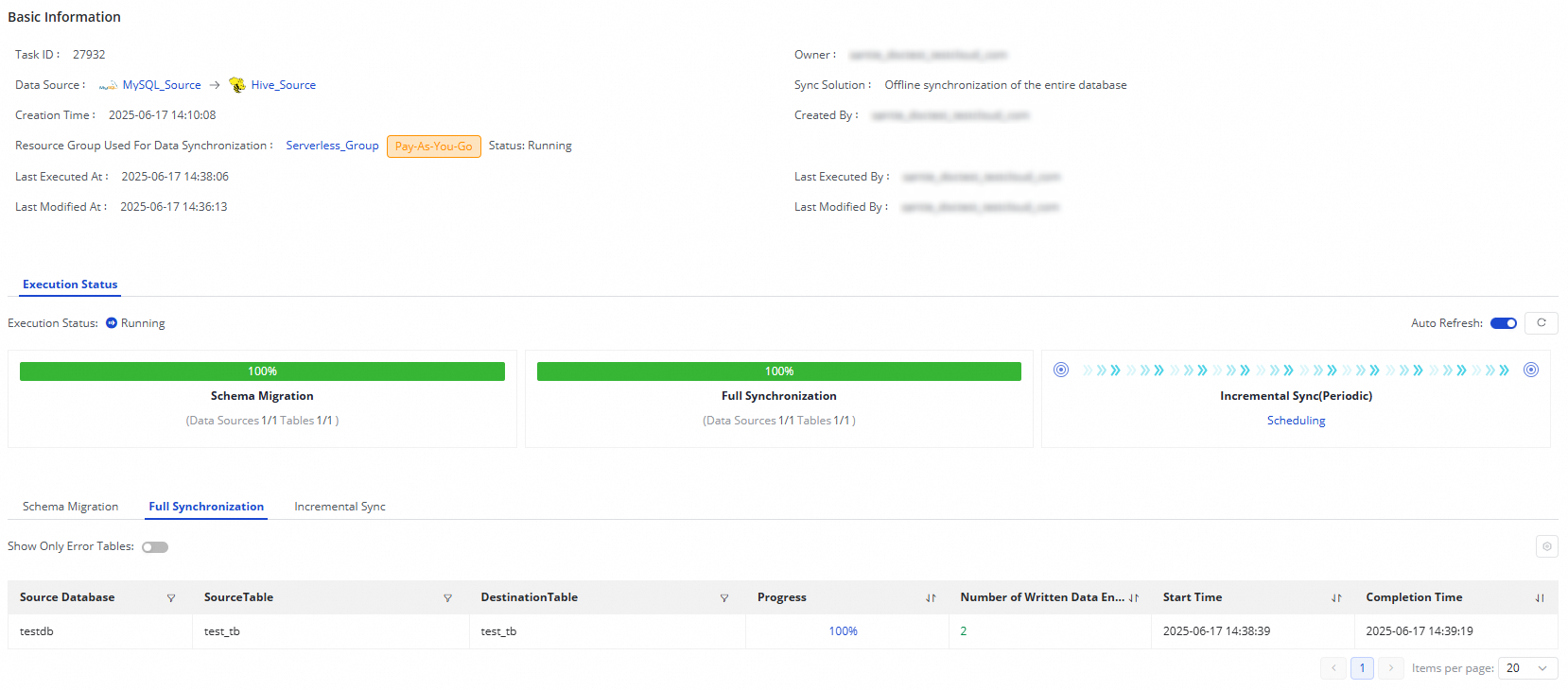
MySQL から Hive へのオフライン同期タスクの場合:
タスクの同期ステップが [フル同期] の場合、スキーマ移行とフル同期が表示されます。
タスクの同期ステップが [増分同期] の場合、スキーマ移行と増分同期が表示されます。
タスクの同期ステップが [フル同期] + [増分同期] の場合、このセクションにはスキーマ移行、フル同期、増分同期が表示されます。
タスクの再実行
[再実行] をクリックして、タスク設定を変更せずにタスクを再実行します。
効果: この操作は、ワンタイムタスクを再実行するか、定期タスクのプロパティを更新します。
テーブルの追加または削除によってタスクを変更した後に再実行するには、タスクを編集して [完了] をクリックします。タスクのステータスは [更新の適用] に変わります。[更新の適用] をクリックすると、変更されたタスクの再実行がすぐにトリガーされます。
効果: 新しいテーブルのみが同期されます。以前に同期されたテーブルは再度同期されません。
タスクを編集 (たとえば、ターゲットテーブル名の変更や別のターゲットテーブルへの切り替え) して [完了] をクリックすると、タスクで利用可能な操作が [更新の適用] に変わります。[更新の適用] をクリックすると、変更されたタスクの再実行がすぐにトリガーされます。
効果: 変更されたテーブルが同期されます。変更されていないテーブルは再度同期されません。
ユースケース
下流のデータ依存関係があり、データ開発操作を実行する必要がある場合は、「ノードのスケジューリング」で説明されているように、ノードの上流と下流の依存関係を設定できます。[定期設定] 列で対応する定期タスクノード情報を表示できます。