Spark on MaxCompute のジョブは、ローカルモードまたはクラスターモードで実行できます。また、DataWorks で Spark on MaxCompute のバッチジョブ (クラスターモード) を実行し、他のノードタイプと統合してスケジューリングすることも可能です。このトピックでは、DataWorks で Spark on MaxCompute ジョブを設定およびスケジューリングする方法について説明します。
概要
Spark on MaxCompute は、オープンソースの Spark と互換性のある MaxCompute のコンピューティングサービスです。統一された計算リソースとデータセット権限システム上に構築されており、使い慣れた開発手法で Spark ジョブを送信・実行できる Spark コンピューティングフレームワークを提供し、幅広いデータ処理および分析ニーズに対応します。DataWorks では、MaxCompute Spark ノードを使用して Spark on MaxCompute タスクのスケジューリングと実行を行い、他のジョブと統合できます。
Spark on MaxCompute は Java、Scala、Python での開発をサポートしており、タスクはローカルモードまたはクラスターモードで実行できます。DataWorks では、Spark on MaxCompute のバッチジョブはクラスターモードで実行されます。Spark on MaxCompute のランタイムモードの詳細については、「ランタイムモード」をご参照ください。
権限
(オプション、RAM ユーザーに必要) タスク開発に使用する RAM ユーザーは、対応するワークスペースに追加し、開発者またはワークスペース管理者のロールを付与する必要があります (ワークスペース管理者は広範な権限を持つため、付与には注意が必要です)。メンバーの追加に関する詳細については、「ワークスペースへのメンバー追加」をご参照ください。
Alibaba Cloud アカウントを使用している場合は、このステップをスキップできます。
制限事項
Spark 3.x を使用する MaxCompute Spark ノードを送信する際にエラーが発生した場合は、サーバーレスリソースグループを購入して使用してください。詳細については、「サーバーレスリソースグループの使用」をご参照ください。
事前準備
MaxCompute Spark ノードは、Java/Scala および Python での Spark on MaxCompute バッチジョブの実行をサポートしています。開発言語によって開発手順や設定インターフェイスが異なるため、ビジネスニーズに最も適した言語を選択してください。
Java/Scala
MaxCompute Spark ノードで Java または Scala のコードを実行する前に、まずローカルで Spark on MaxCompute のジョブコードを開発し、それを MaxCompute リソースとして DataWorks にアップロードする必要があります。以下の手順に従ってください:
開発環境をセットアップします。
ご利用のオペレーティングシステムに基づき、Spark on MaxCompute タスクを実行するための開発環境を準備します。詳細については、「Linux 開発環境のセットアップ」または「Windows 開発環境のセットアップ」をご参照ください。
Java/Scala コードを開発します。
MaxCompute Spark ノードで Java または Scala コードを実行する前に、ローカルまたは既存の環境で Spark on MaxCompute コードを開発します。Spark on MaxCompute が提供する「概要」を使用することを推奨します。
コードをパッケージ化して DataWorks にアップロードします。
コードを開発した後、パッケージ化して MaxCompute リソースとして DataWorks にアップロードします。詳細については、「リソース管理」をご参照ください。
Python (デフォルトの Python 環境)
DataWorks では、DataWorks の Python リソースに直接コードを記述することで PySpark ジョブを開発し、MaxCompute Spark ノードを使用してコードロジックを送信・実行できます。DataWorks での Python リソースの作成については、PySpark 開発の例として「PySpark を使用した Spark on MaxCompute アプリケーションの開発」をご参照ください。
このアプローチでは DataWorks が提供するデフォルトの Python 環境を使用するため、直接依存できるサードパーティパッケージは限られています。デフォルトの環境が PySpark ジョブのサードパーティ依存関係の要件を満たせない場合は、以下の開発言語:Python (カスタム Python 環境) セクションを参照して、タスクを実行するための独自の Python 環境を準備してください。また、Python リソースのサポートが強化された PyODPS 2 ノードや PyODPS 3 ノードを選択することもできます。
Python (カスタム Python 環境)
プラットフォームが提供するデフォルトの Python 環境がビジネス要件を満たせない場合は、以下の手順に従って Python 環境をカスタマイズし、Spark on MaxCompute タスクを実行してください。
ローカルで Python 環境を準備します。
「PySpark の Python バージョンと依存関係のサポート」を参照し、ビジネスニーズに基づいて利用可能な Python 環境を設定します。
環境をパッケージ化して DataWorks にアップロードします。
Python 環境を ZIP パッケージに圧縮し、MaxCompute リソースとして DataWorks にアップロードして、後続の Spark on MaxCompute タスクの実行環境として使用します。
設定項目
DataWorks は、Spark on MaxCompute のバッチジョブをクラスターモードで実行します。クラスターモードでは、カスタムプログラムのエントリーポイント main を指定する必要があります。main が終了すると (つまり、ステータスが Success または Fail になると)、対応する Spark ジョブは終了します。さらに、spark-defaults.conf の各設定は、executor の数、メモリサイズ、spark.hadoop.odps.runtime.end.point など、MaxCompute Spark ノードの設定項目に個別に追加する必要があります。
spark-defaults.conf ファイルをアップロードする必要はありません。代わりに、spark-defaults.conf 内の設定を MaxCompute Spark ノードの設定項目に 1 つずつ追加してください。
Java/Scala の設定

パラメーター | 説明 | 対応する spark-submit オプション |
Spark Version | Spark1.x、Spark2.x、Spark3.x が含まれます。 説明 Spark 3.x を使用する MaxCompute Spark ノードを送信する際にエラーが発生した場合は、サーバーレスリソースグループを購入して使用してください。詳細については、「サーバーレスリソースグループの使用」をご参照ください。 | — |
Language | ここで Java/Scala または Python を選択します。実際の Spark on MaxCompute 開発言語に基づいて選択してください。 | — |
Main JAR Resource | タスクが使用するメインの JAR リソースファイルまたはメインの Python リソースを指定します。 リソースファイルは DataWorks にアップロードし、事前に送信しておく必要があります。詳細については、「リソース管理」をご参照ください。 |
|
Configuration Item | ジョブを送信する際に使用する設定項目を指定します。注意事項:
|
|
Main Class | メインクラスの名前です。開発言語が |
|
Parameter | 必要に応じてパラメーターを追加できます。複数のパラメーターはスペースで区切ります。DataWorks はスケジューリングパラメーターをサポートしています。ここでの Parameter のフォーマットは サポートされているスケジューリングパラメーターの割り当てフォーマットについては、「スケジューリングパラメーターのソースと式」をご参照ください。 |
|
JAR Resources | 開発言語が リソースファイルは DataWorks にアップロードし、事前に送信しておく必要があります。詳細については、「リソース管理」をご参照ください。 | リソースコマンド:
|
File Resources | ファイルリソースです。 |
|
Archive Resources | ZIP フォーマットで圧縮されたリソースのみがリストされます。 |
|
Python の設定
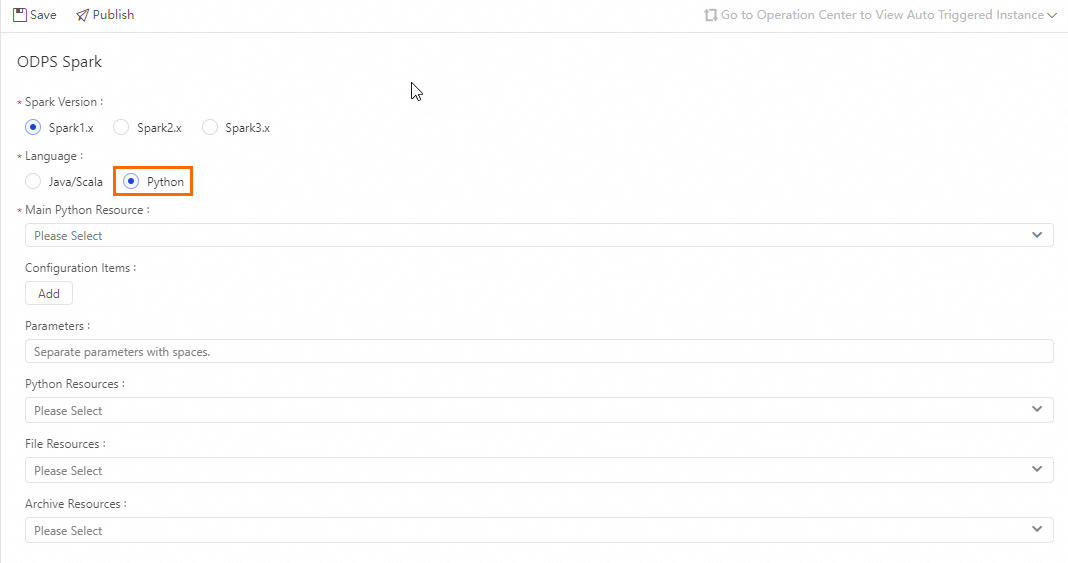
パラメーター | 説明 | 対応する spark-submit オプション |
Spark Version | Spark1.x、Spark2.x、Spark3.x が含まれます。 説明 Spark 3.x を使用する MaxCompute Spark ノードを送信する際にエラーが発生した場合は、サーバーレスリソースグループを購入して使用してください。詳細については、「サーバーレスリソースグループの使用」をご参照ください。 | — |
Language | ここで Python を選択します。実際の Spark on MaxCompute 開発言語に基づいて選択してください。 | — |
Main Python Resource | タスクが使用するメインの JAR リソースファイルまたはメインの Python リソースを指定します。 リソースファイルは DataWorks にアップロードし、事前に送信しておく必要があります。詳細については、「リソース管理」をご参照ください。 |
|
Configuration Item | ジョブを送信する際に使用する設定項目を指定します。注意事項:
|
|
Parameter | 必要に応じてパラメーターを追加できます。複数のパラメーターはスペースで区切ります。DataWorks はスケジューリングパラメーターをサポートしています。ここでの Parameter のフォーマットは サポートされているスケジューリングパラメーターの割り当てフォーマットについては、「スケジューリングパラメーターのソースと式」をご参照ください。 |
|
Python Resources | 開発言語が リソースファイルは DataWorks にアップロードし、事前に送信しておく必要があります。詳細については、「リソース管理」をご参照ください。 |
|
File Resources | ファイルリソースです。 |
|
Archive Resources | 圧縮されたリソースのみがリストされます。 |
|
操作手順
リソースを作成します。
Data Studio ページの左側のナビゲーションウィンドウの [Resource Management] セクションで、[作成] をクリックし、[MaxCompute Spark Python リソースの作成] を選択して、
spark_is_number.pyという名前を付けます。詳細については、「リソース管理」をご参照ください。コードは以下の通りです:# -*- coding: utf-8 -*- import sys from pyspark.sql import SparkSession try: # for python 2 reload(sys) sys.setdefaultencoding('utf8') except: # python 3 not needed pass if __name__ == '__main__': spark = SparkSession.builder\ .appName("spark sql")\ .config("spark.sql.broadcastTimeout", 20 * 60)\ .config("spark.sql.crossJoin.enabled", True)\ .config("odps.exec.dynamic.partition.mode", "nonstrict")\ .config("spark.sql.catalogImplementation", "odps")\ .getOrCreate() def is_number(s): try: float(s) return True except ValueError: pass try: import unicodedata unicodedata.numeric(s) return True except (TypeError, ValueError): pass return False print(is_number('foo')) print(is_number('1')) print(is_number('1.3')) print(is_number('-1.37')) print(is_number('1e3'))リソースを保存します。
作成した MaxCompute Spark ノードで、ノードのパラメーターとスケジュール設定を構成します。詳細については、「設定項目」をご参照ください。
ノードをスケジュール実行するには、ビジネスニーズに基づいてスケジュール情報を設定します。詳細については、「ノードスケジューリングの設定」をご参照ください。
ノードタスクを設定した後、ノードをデプロイする必要があります。詳細については、「ノードとワークフローのデプロイメント」をご参照ください。
タスクがデプロイされた後、オペレーションセンターで定期タスクの実行ステータスを確認できます。詳細については、「オペレーションセンター入門」をご参照ください。
説明Data Studio の MaxCompute Spark ノードには実行エントリがないため、開発環境のオペレーションセンターから Spark タスクを実行する必要があります。
バックフィルデータインスタンスが正常に実行された後、そのランタイムログ内のトラッキング URL を開いて実行結果を確認します。