本トピックでは、データ検出タスクを作成し、機密データ検出ページで不正確に識別されたデータを手動で修正する方法について説明します。
手動で修正した結果は、翌日に表示され、有効になります。
検出タスクの作成
センシティブデータ検出ルールページに移動します。詳細については、「センシティブデータ検出ルールページへの移動」をご参照ください。
[検出タスク] タブをクリックして、検出タスクページに移動します。
機密データ検出タスクを開始します。
[機密データ検出タスク] を設定します。
[センシティブデータ検出タスクを有効にする] ダイアログボックスで、タスクタイプ、スキャンメソッド、および範囲を設定します。リアルタイムタスク、スケジュールされたタスク、またはワンタイムタスクを設定できます。
リアルタイムタスクの設定
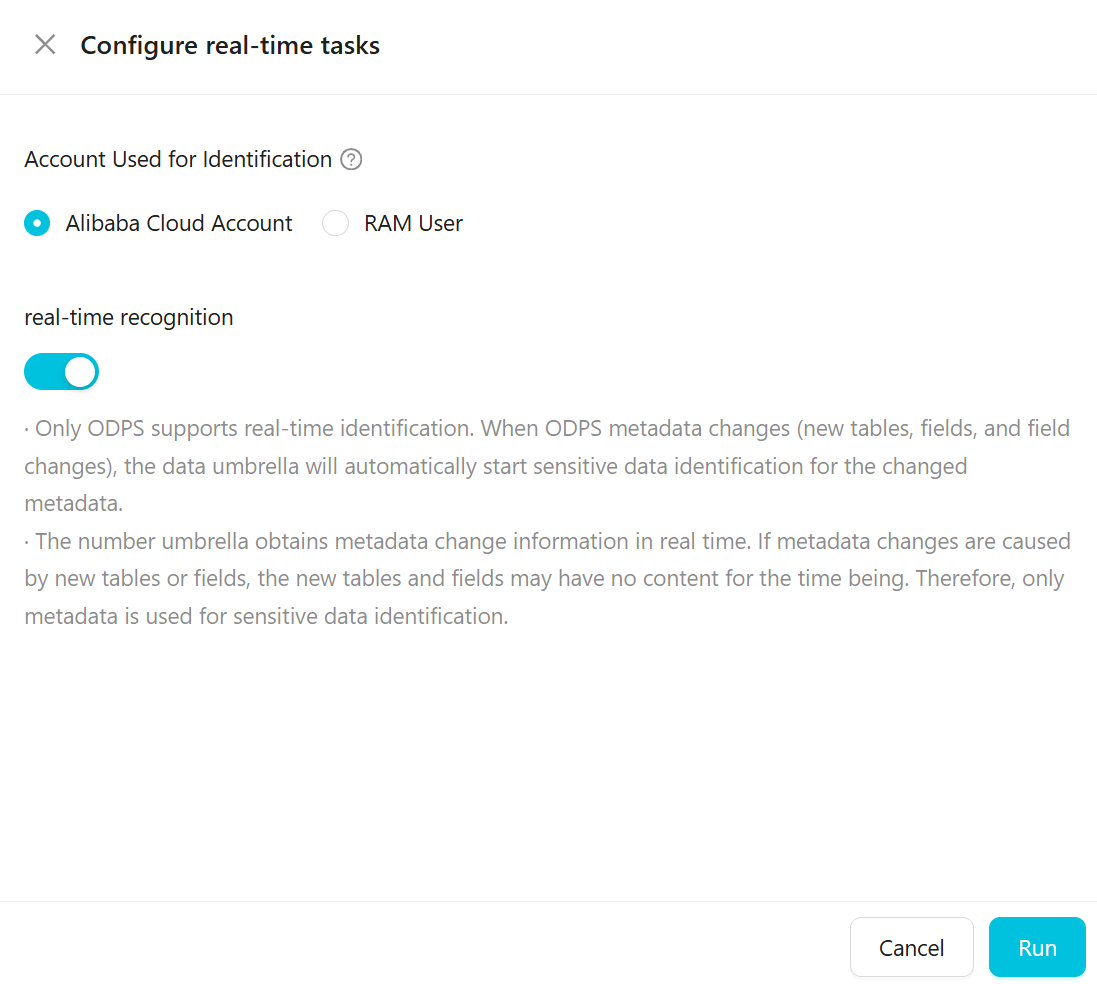
次の表にパラメーターを説明します。
パラメーター
説明
検出アカウント
Alibaba Cloud アカウントまたは RAM ユーザーを使用してデータサンプリングとスキャンを設定します。選択したアカウントは、データのサンプリングとスキャンに使用されます。サンプリングできるデータの範囲は、アカウントの権限によって異なります。
説明RAM ユーザーを検出に使用するには、まず RAM ユーザーに MaxCompute プロジェクトの権限を付与する必要があります。
リアルタイム検出
ODPS のみがリアルタイム検出をサポートしています。テーブルやフィールドの追加、フィールドの変更など、ODPS のメタデータが変更されると、データセキュリティガードは変更されたメタデータに対して自動的に機密データ検出タスクを開始します。
データセキュリティガードはメタデータの変更情報をリアルタイムで取得します。変更が新しいテーブルまたはフィールドによるものである場合、新しいテーブルまたはフィールドにはまだコンテンツがない可能性があります。この場合、機密データ検出にはメタデータのみが使用されます。
定期タスクの設定
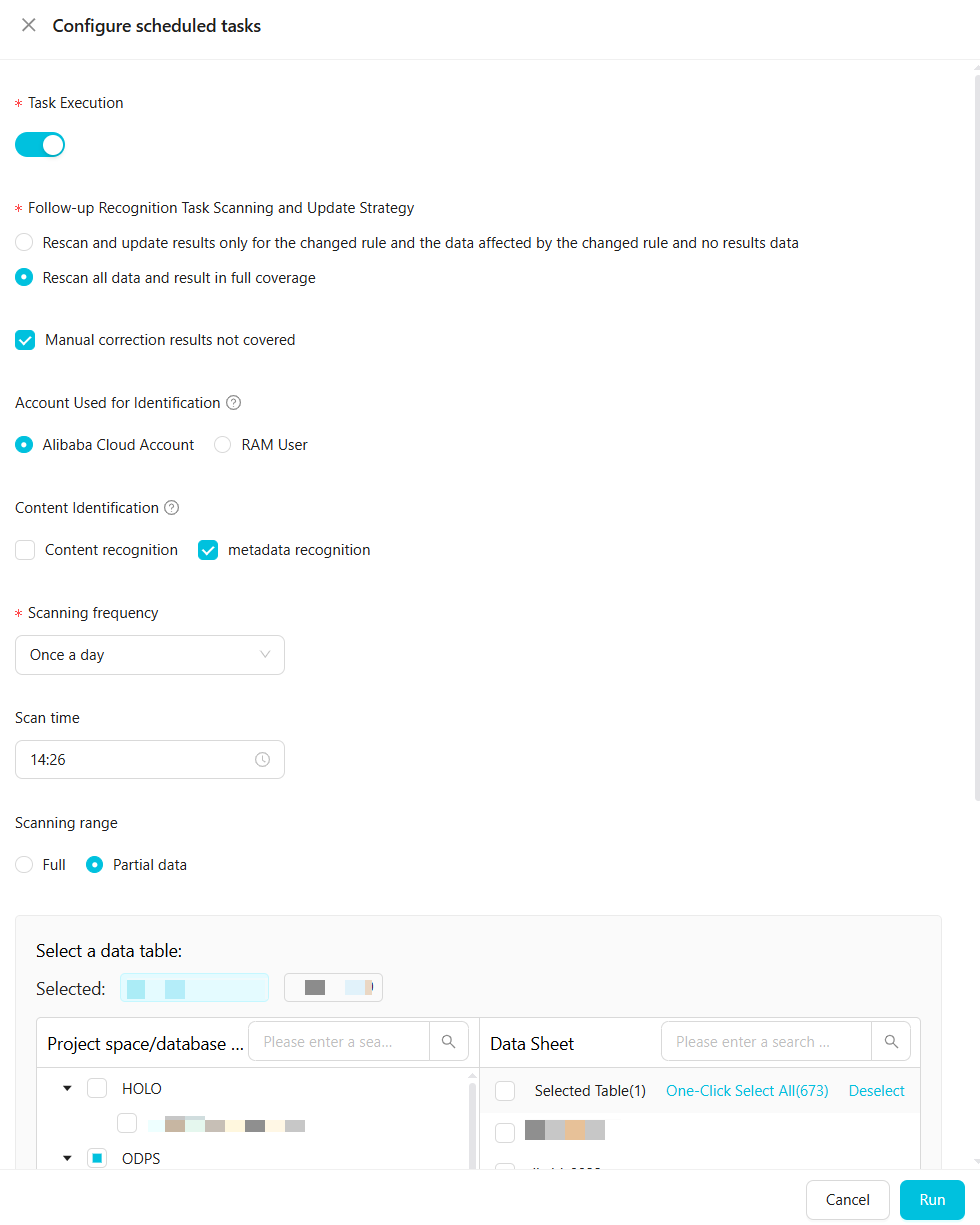 次の表にパラメーターを示します。
次の表にパラメーターを示します。パラメーター
説明
タスク実行
タスクの実行は手動で有効にする必要があります。
後続の検出タスクのスキャンと更新ポリシー
2つのオプションがあります:
変更されたルール、変更されたルールの影響を受けるデータ、および結果のないデータのみを再スキャンして結果を更新します。
すべてのデータを再スキャンし、すべての結果を上書きします。
手動で修正した結果を上書きしないように選択できます。
検出アカウント
[Alibaba Cloud アカウント] または [RAM ユーザー] を使用してデータサンプリングとスキャンを設定します。選択したアカウントは、データのサンプリングとスキャンに使用されます。サンプリングおよびスキャンできるデータの範囲は、アカウントの権限によって異なります。
説明RAM ユーザーをサンプリングとスキャンに使用するには、まず RAM ユーザーに MaxCompute プロジェクトの権限を付与する必要があります。
コンテンツ検出
[コンテンツ検出] と [メタデータ検出] ルールを有効にするかどうかを設定します。対応するルールは、選択した後にのみ有効になります。
説明[コンテンツ検出] を選択しない場合、データセキュリティガードはデータのサンプリングやスキャンを行いません。コンテンツ検出ルールは有効になりませんが、フィールド名とフィールドコメントのルールは引き続き有効です。
サンプルサイズ
コンテンツ検出のサンプルサイズを設定します。100 より大きい値を推奨します。
このパラメーターは、[コンテンツ検出] を選択した場合に必須です。
スキャン頻度とスキャン時間
定期タスクのスキャン周期を定義します。
このパラメーターは、[タスクタイプ] を [スケジュールされたタスク] に設定した場合にのみ必須です。
スキャン頻度は [週に1回] または [1日に1回] に設定できます。週次スキャンの場合、月曜日から金曜日までの任意の日を選択できます。時間範囲は 0:00 から 23:59 です。
スキャン範囲
センシティブデータ検出タスクのデータ範囲を設定します。
すべて:現在のテナントの権限が付与されたアカウント配下のすべてのデータをスキャンします。
部分的なデータ:指定されたプロジェクトのテーブルデータをスキャンします。
説明デフォルトのプロジェクト範囲には、すべての DPI エンジンのすべてのプロジェクトが含まれます。
ODPS、EMR、および HOLO プロジェクトの指定されたテーブルのデータをスキャンできます。
テーブル名の全長は
0~100文字です。すべての文字タイプがサポートされています。このフィールドを空のままにすると、すべてのテーブルがスキャンされます。ワイルドカード文字
.*がサポートされています。たとえば、.*nameはnameで終わるテーブル名に一致し、private.*はprivateで始まるテーブル名に一致します。複数のテーブル名またはフィールド名を区切るには、カンマ (,) を使用します。
[部分的なデータ] を選択した場合、複数のプロジェクトまたはデータベースのスキャン範囲を追加できます。最終的なスキャン範囲は、指定されたすべての範囲の和集合になります。
ページの左側でプロジェクトを手動で選択する必要があります。
プロジェクトを選択すると、そのプロジェクトまたはデータベース内のデータテーブルが右側に表示されます。テーブルを手動で選択するか、一度にすべてのテーブルを選択できます。デフォルトでは、データベース内のすべてのデータテーブルが選択されます。
プロジェクト、データベース、およびデータテーブルでキーワード検索がサポートされています。キーワードでデータテーブルを検索するには、まずプロジェクトを選択し、そのプロジェクト内で検索を実行します。
ワンタイムタスクの設定
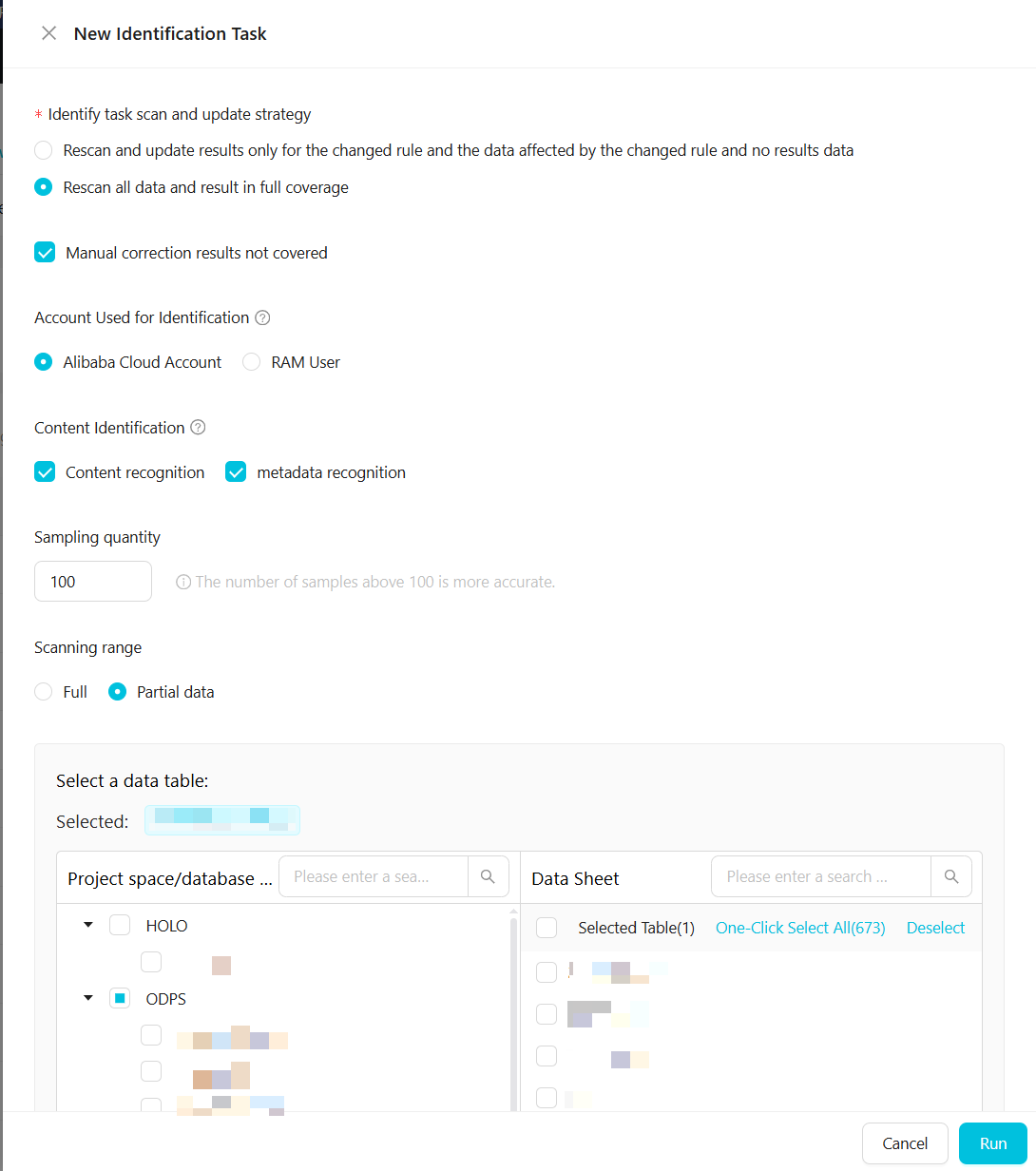 次の表にパラメーターを示します。
次の表にパラメーターを示します。パラメーター
説明
検出タスクのスキャンと更新ポリシー
2つのオプションがあります:
変更されたルール、変更されたルールの影響を受けるデータ、および結果のないデータのみを再スキャンして結果を更新します。
すべてのデータを再スキャンし、すべての結果を上書きします。
手動で修正した結果を上書きしないように選択できます。
検出アカウント
[Alibaba Cloud アカウント] または [RAM ユーザー] を使用してデータサンプリングとスキャンを設定します。選択したアカウントは、データのサンプリングとスキャンに使用されます。サンプリングおよびスキャンできるデータの範囲は、アカウントの権限によって異なります。
説明RAM ユーザーをサンプリングとスキャンに使用するには、まず RAM ユーザーに MaxCompute プロジェクトの権限を付与する必要があります。
コンテンツ検出
[コンテンツ検出] と [メタデータ検出] ルールを有効にするかどうかを設定します。対応するルールは、選択した後にのみ有効になります。
説明[コンテンツ検出] を選択しない場合、データセキュリティガードはデータのサンプリングやスキャンを行いません。コンテンツ検出ルールは有効になりませんが、フィールド名とフィールドコメントのルールは引き続き有効です。
サンプルサイズ
コンテンツ検出のサンプルサイズを設定します。100 より大きい値を推奨します。
このパラメーターは、[コンテンツ検出] を選択した場合に必須です。
スキャン範囲
センシティブデータ検出タスクのデータ範囲を設定します。
すべて:現在のテナントの権限が付与されたアカウント配下のすべてのデータをスキャンします。
部分的なデータ:指定されたプロジェクトのテーブルデータをスキャンします。
説明デフォルトのプロジェクト範囲には、すべての DPI エンジンのすべてのプロジェクトが含まれます。
ODPS、EMR、および HOLO プロジェクトの指定されたテーブルのデータをスキャンできます。
テーブル名の全長は
0~100文字です。すべての文字タイプがサポートされています。このフィールドを空のままにすると、すべてのテーブルがスキャンされます。ワイルドカード文字
.*がサポートされています。たとえば、.*nameはnameで終わるテーブル名に一致し、private.*はprivateで始まるテーブル名に一致します。複数のテーブル名またはフィールド名を区切るには、カンマ (,) を使用します。
[部分的なデータ] を選択した場合、複数のプロジェクトまたはデータベースのスキャン範囲を追加できます。最終的なスキャン範囲は、指定されたすべての範囲の和集合になります。
ページの左側でプロジェクトを手動で選択する必要があります。
プロジェクトを選択すると、そのプロジェクトまたはデータベース内のデータテーブルが右側に表示されます。テーブルを手動で選択するか、一度にすべてのテーブルを選択できます。デフォルトでは、データベース内のすべてのデータテーブルが選択されます。
プロジェクト、データベース、およびデータテーブルでキーワード検索がサポートされています。キーワードでデータテーブルを検索するには、まずプロジェクトを選択し、そのプロジェクト内で検索を実行します。
[有効にする] をクリックしてスキャンタスクを開始します。
タスクが開始されると、[タスクステータス] は次のように変更されます:
リアルタイムタスク:ステータスが [有効化中] に変わります。
定期タスク:ステータスが「有効化中」に変わります。設定されたスキャン時間に達すると、プラットフォームは設定に基づいて機密データ検出を実行します。
ワンタイムタスク:ステータスが進捗横棒グラフに変わります。進捗が 100% に達するとタスクは完了です。進捗は次の数式で計算されます:(現在のタスクでスキャンされたテーブル数 / 現在のタスクでスキャンされるテーブルの総数) × 100%。
説明検出ルールが変更された後、新しいルールは次の定期タスクで有効になります。変更をすぐに適用するには、ワンタイム検出タスクを作成できます。
スキャンタスクが完了すると、[タスクステータス] は [タスクなし] に更新されます。
検出結果の手動修正
センシティブデータ検出ルールページに移動します。詳細については、「センシティブデータ検出ルールページへの移動」をご参照ください。
[検出結果] タブをクリックして、検出結果ページに移動します。
不正確な検出結果を手動で修正します。
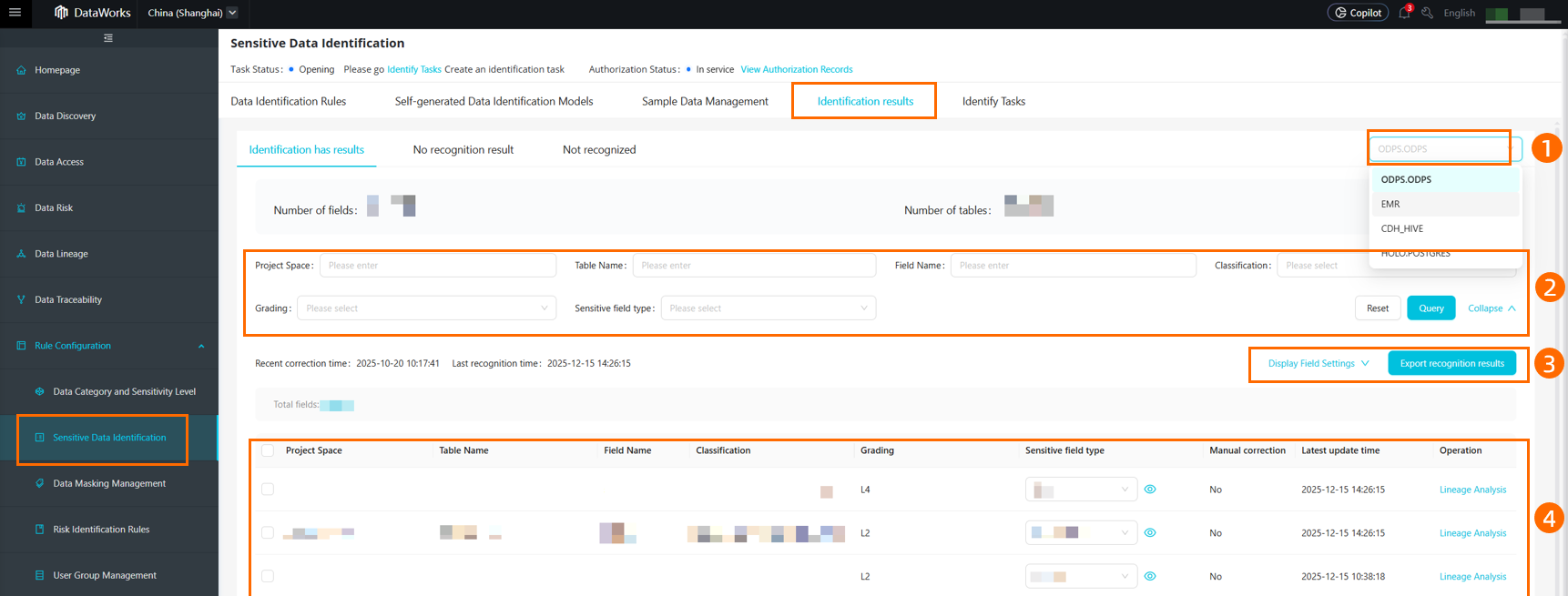
操作
説明
DPI エンジンタイプでフィルター
前の図のエリア ① で、ドロップダウンリストから DPI エンジンを選択できます。
説明ODPS、EMR、CDH_HIVE、および HOLO エンジンの機密フィールドの検出結果を修正できます。
フィルター
前の図のエリア ② で、検出結果をフィルターできます。
[プロジェクト]、[テーブル名]、[フィールド名] などの条件でフィルターできます。また、[展開] をクリックしてより多くのフィルター条件を表示し、[分類]、[分級]、[機密フィールドタイプ] でさらにフィルターすることもできます。
[分類]:現在のテナントのデフォルトの分類・分級テンプレートの分類情報。詳細については、「機密データの分類と分級の設定」をご参照ください。
[分級]:現在のテナントのデフォルトの分類・分級テンプレートの分級情報。
単一データの修正
前の図のエリア ③ には、検出結果のリストが表示されます。[表示フィールド設定] をクリックし、表示したいフィールドを選択してリストの詳細を更新できます。デフォルトでは、リストには [プロジェクト]、[テーブル名]、[フィールド名]、[分類]、[分級]、[機密フィールドタイプ]、[手動修正済み]、および [最終更新日時] が表示されます。
[機密フィールドタイプ] が正しくないフィールドについては、[機密フィールドタイプ] 列のドロップダウン矢印をクリックします。リストには、現在のテナントのデフォルトの分類・分級テンプレートから [公開済み] の機密フィールドタイプが表示されます。既存の機密フィールドタイプがニーズを満たしているか確認します:
ニーズを満たしている場合:別の既存の機密フィールドタイプを選択します。次に、右側の
 アイコンをクリックして [データ検出ルール] ページに移動します。元の機密フィールドタイプと新しい機密フィールドタイプの両方の検出ルールを変更して、将来の検出精度を確保します。
アイコンをクリックして [データ検出ルール] ページに移動します。元の機密フィールドタイプと新しい機密フィールドタイプの両方の検出ルールを変更して、将来の検出精度を確保します。ニーズを満たしていない場合:右側の
アイコンをクリックして [データ検出ルール] ページに移動します。または、ドロップダウンリストの一番下までスクロールし、[機密フィールドタイプの管理] をクリックします。[データ検出ルール] ページにリダイレクトされ、[機密フィールドタイプの作成] ダイアログボックスが表示されます。新しい機密フィールドタイプを追加し、その検出ルールを設定します。詳細については、「データ検出ルールの設定と検出タスクの実行」をご参照ください。
データのバッチ修正
バッチ修正したいフィールドを選択し、上の図のエリア ④ にある [バッチ修正] ボタンをクリックします。[認識結果のバッチ修正] ダイアログボックスが表示されます。[機密フィールドタイプ] ドロップダウンリストには、現在のテナントのデフォルトの分類・分級テンプレートから [公開済み] の機密フィールドタイプが表示されます。正しい機密フィールドタイプを選択し、[保存] をクリックして認識結果のバッチ修正を完了します。
検出結果のエクスポート
システムによって識別されたデータについては、[検出結果のエクスポート] をクリックして、フィルター条件に一致する結果をローカルコンピューターにエクスポートできます。
[検出結果のエクスポート]:
 アイコンをクリックすると、現在のフィルター条件に一致する検出結果が自動的にエクスポートされます。説明
アイコンをクリックすると、現在のフィルター条件に一致する検出結果が自動的にエクスポートされます。説明最大 100,000 件のデータをエクスポートできます。