DataWorksは、for-eachノードを提供します。 for-eachノードを使用すると、割り当てノードによって渡された結果セットをループ処理できます。また、for-eachノードの内部ノードをカスタマイズすることもできます。このトピックでは、for-eachノードの構成とアプリケーションロジックについて説明します。
使用上の注意
次の表に、for-eachノードの使用上の注意を示します。
項目 | 参照 |
for-eachノードの使用シナリオについて学習します。 | 説明 for-eachノードは、割り当てノードによって渡された結果セットのみをループ処理するために使用されます。 |
ループ数の上限、for-eachノードをテストする方法、for-eachノードのログを表示する方法など、for-eachノードの制限事項と注意事項について学習します。 | |
ビジネス要件に基づいて、for-eachノードの内部ワークフローを設定できることを学習します。 for-eachノードの内部ワークフローを設定する場合は、内部ワークフローが開始ノードで始まり、終了ノードで終わることを確認してください。 | |
for-eachノードのループ数は、割り当てノードの出力によって決定されることを学習します。 | |
for-eachノードによって提供される組み込み変数を使用して、各ループで割り当てノードの結果セットから関連する値を取得できることを学習します。 | |
for-eachノードの変数値とループ数のサンプルについて学習します。 | ShellノードまたはODPS SQLノードがfor-eachノードの割り当てノードとして使用される場合の、for-eachノードのサンプル変数値とサンプルループ数 |
シナリオ
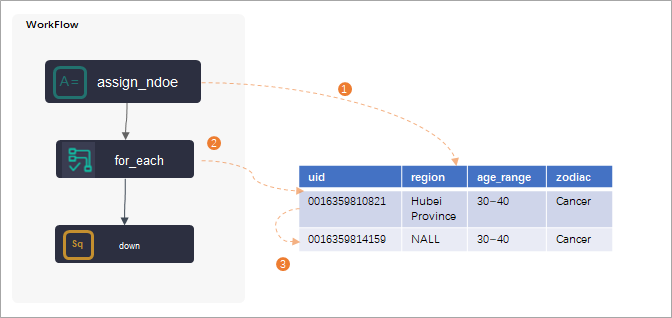
DataWorksのfor-eachノードは、ループトラバーサルシナリオで使用され、割り当てノードと一緒に使用する必要があります。割り当てノードは、for-eachノードの祖先ノードとして設定する必要があります。割り当てノードがその出力をfor-eachノードに渡した後、for-eachノードは出力をループ処理します。
制限
DataWorks Standard Edition以上のエディションのみがfor-eachノードをサポートしています。 DataWorksエディションの違いについては、DataWorksエディションの違いを参照してください。
for-eachノードの最大ループ数は 1024 です。 for-eachノードの実際のループ数は、割り当てノードによって渡される結果セットによって決まります。
並列実行はサポートされていません。前のループが終了した場合にのみ、ループを開始できます。
注意事項
ディメンション | 項目 | 説明 |
依存関係 | 依存関係の設定 | for-eachノードは、割り当てノードによって渡された値をループ処理する必要があります。したがって、割り当てノードは、for-eachノードの祖先ノードとして設定する必要があります。 for-eachノードは、割り当てノードに依存する必要があります。 |
トラバーサルサポート | ループ数の上限 | for-eachノードの最大ループ数は 1024 です。 for-eachノードのループ数が 1024 を超えると、エラーが報告されます。 for-eachノードの実際のループ数は、割り当てノードの出力によって決まります。 |
ループ数 | for-eachノードのループ数は、割り当てノードによって渡される結果セットによって決まります。 | |
内部ノード | ワークフローオーケストレーション | |
値の取得 | for-eachノードによって提供される組み込み変数を使用して、for-eachノードの祖先ノードとして設定されている割り当てノードによって渡される特定の値を取得できます。 | |
デバッグ | ノードのデバッグ |
|
ログの表示 | オペレーションセンターでfor-eachノードの操作ログを表示するには、次の手順を実行します。 [サイクルタスク] ページでfor-eachノードを見つけ、ノードの有向非巡回グラフ (DAG) を開きます。 DAGで、ノード名を右クリックし、[内部ノードの表示]を選択して、内部ノードの操作ログを表示します。 |
for-eachノードの構成とワークフローオーケストレーション
for-eachノードは、内部ノードを含む特殊なノードの一種です。 for-eachノードを作成すると、次の3つの内部ノードが自動的に作成されます。[開始ノード](ループ開始ノード)、[shellノード](ループタスクノード)、[終了ノード](ループ終了ノード)。内部ノードは、割り当てノードの出力をループ処理するために、内部ノードワークフローに編成されます。 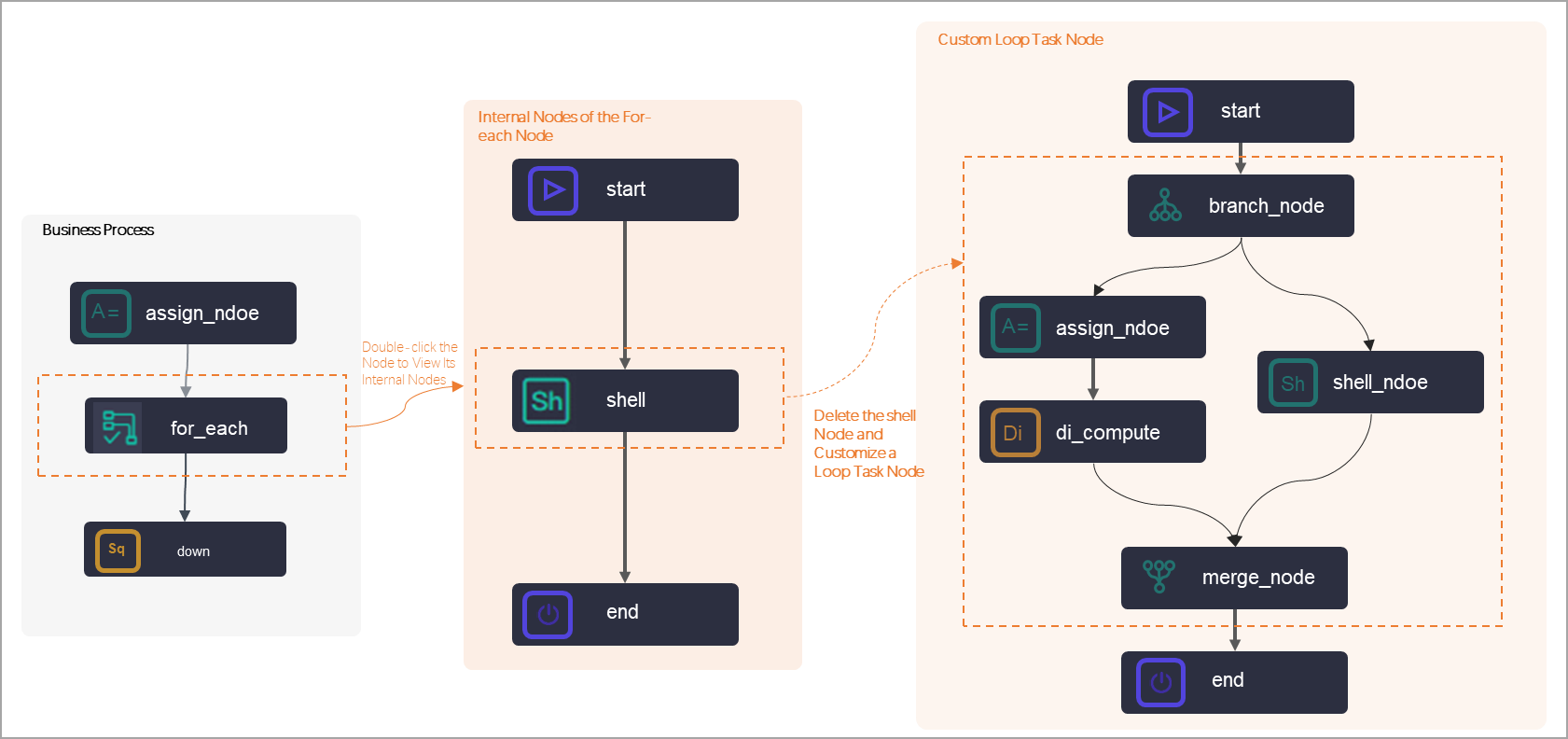 前の図は、次の情報を示しています。
前の図は、次の情報を示しています。
Shellノード
DataWorksは、内部Shellタスクノードを自動的に作成します。デフォルトの[shell]ノードを削除し、ビジネス要件に基づいて内部ループタスクノードを設定できます。
内部ループタスクノードとしてShellノードを使用する場合は、[shellノード]をダブルクリックし、ノード設定タブでノードコードを編集します。
ループタスクが複雑な場合は、for-eachノードの内部ワークフローにさらに内部ノードを作成してループタスクを処理し、ビジネス要件に基づいて内部ノードを接続できます。
説明for-eachノードの内部ループタスクノードをカスタマイズする場合、for-eachノードの既存の内部ノード間の依存関係を削除し、ビジネス要件に基づいてfor-eachノードの内部ワークフローを設定できます。 for-eachノードの内部ワークフローを設定する場合は、内部ワークフローが[開始ノード]で始まり、[終了ノード]で終わることを確認してください。
[開始]ノードと[終了]ノード
開始ノードはループの開始を示し、終了ノードはループの終了を示します。2つのノードは、ループタスクの処理には使用されません。
説明for-eachノードのループ数は、for-eachノードの終了ノードではなく、割り当てノードの出力によって決まります。割り当てノードは、for-eachノードの祖先ノードとして設定されます。
ループ数
for-eachノードの最大ループ数は 1024 です。 for-eachノードの実際のループ数は、割り当てノードによって渡される結果セットによって決まります。
for-eachノードのループ数は、割り当てノードによって渡される結果セットによって決まります。
for-eachノードの祖先ノードとして設定する割り当てノードがShellまたはPythonを使用する場合、for-eachノードのループ数は、生成された1次元配列によって決まります。ループ数は、1次元配列の要素数と同じです。要素はコンマ (,) で区切られます。
たとえば、割り当てノードがShellまたはPython (Python 2) を使用する場合、割り当てノードの出力は、
2021-03-28,2021-03-29,2021-03-30,2021-03-31,2021-04-01などの1次元配列です。 for-eachノードは、割り当てノードの出力を5回ループ処理します。for-eachノードの内部ループタスクノードとしてSQLノードを使用する場合、for-eachノードのループ数は、生成された2次元配列によって決まります。ループ数は、2次元配列の行数と同じです。
たとえば、割り当てノードでODPS SQLが使用される場合、割り当てノードの出力は2次元配列です。
+----------------------------------------------+ | uid | region | age_range | zodiac | +----------------------------------------------+ | 0016359810821 | Hubei Province | 30 to 40 years old | Cancer | // 湖北省、30~40歳、かに座 | 0016359814159 | Unknown | 30 to 40 years old | Cancer | // 不明、30~40歳、かに座 +----------------------------------------------+出力は、for-eachノードが割り当てノードの出力を2回ループ処理することを示しています。
組み込み変数
for-eachノードによって提供される組み込み変数を使用して、for-eachノードの祖先ノードとして設定されている割り当てノードによって渡された結果セットを取得できます。 for-eachノードの内部ワークフローに割り当てノードが含まれている場合は、デフォルトの方法を使用して割り当てノードの出力を取得できます。デフォルトの方法の詳細については、割り当てノードの設定を参照してください。
DataWorksのfor-eachノードによって提供される組み込み変数を使用して、for-eachノードが割り当てノードの出力をループ処理するときに、終了したループ数と現在のループと最初のループの間のオフセットを取得できます。
組み込み変数 | 説明 | forループとの比較 |
| 割り当てノードのデータセットを取得します。 | forループのコード結果に相当します。 |
| 現在のデータエントリを取得します。 | forループのコード例:
|
| 現在のループと最初のループの間のオフセットを取得します。 | |
| 終了したループ数を取得します。 | - |
出力テーブルのスキーマに精通している場合は、次の表の変数を使用して、各ループで関連する値を取得することもできます。
その他の変数 | 説明 |
| for-eachノードの祖先ノードとして設定されている割り当てノードの出力が2次元配列の場合、この変数は、for-eachノードが割り当てノードの出力をループ処理するときに、現在のデータエントリの特定の列のデータを取得するために使用されます。 |
| for-eachノードの祖先ノードとして設定されている割り当てノードの出力が2次元配列の場合、この変数は、割り当てノードのデータセットの行 i と列 j のデータを取得するために使用されます。 |
| for-eachノードの祖先ノードとして設定されている割り当てノードの出力が1次元配列の場合、この変数は、特定の列のデータを取得するために使用されます。 |
変数値の例
例 1:Shellノードが割り当てノードとして使用される
割り当てノードの出力
Shellノードが割り当てノードとして使用され、割り当てノードの最後の出力は
2021-03-28,2021-03-29,2021-03-30,2021-03-31,2021-04-01です。for-eachノードの変数の値
説明割り当てノードの出力は1次元配列であり、配列内の5つの要素はコンマ (,) で区切られます。したがって、for-eachノードのループ数は 5 です。
組み込み変数
最初のループの値
2番目のループの値
${dag.loopDataArray} ${dag.loopDataArray}2021-03-28,2021-03-29,2021-03-30,2021-03-31,2021-04-01${dag.foreach.current}2021-03-282021-03-29${dag.offset}0
1
${dag.loopTimes}1
2
${dag.foreach.current[3]} // ${dag.loopDataArray[0][3]} の誤りではないか? ${dag.foreach.current[3]}// 存在しないのでエラーとなる。
例 2:ODPS SQLノードが割り当てノードとして使用される
割り当てノードの出力
ODPS SQLノードが割り当てノードとして使用され、最後のSELECTステートメントは次の2つのデータを返します。
+----------------------------------------------+ | uid | region | age_range | zodiac | +----------------------------------------------+ | 0016359810821 | Hubei Province | 30 to 40 years old | Cancer | // 湖北省、30~40歳、かに座 | 0016359814159 | Unknown | 30 to 40 years old | Cancer | // 不明、30~40歳、かに座 +----------------------------------------------+for-eachノードの変数の値
説明割り当てノードの出力は2次元配列であり、配列には2行のデータが含まれています。したがって、for-eachノードのループ数は 2 です。
組み込み変数
最初のループの値
2番目のループの値
${dag.loopDataArray}+----------------------------------------------+ | uid | region | age_range | zodiac | +----------------------------------------------+ | 0016359810821 | Hubei Province | 30 to 40 years old | Cancer | //湖北省 | 0016359814159 | Unknown | 30 to 40 years old | Cancer | //不明 +----------------------------------------------+${dag.foreach.current}0016359810821,Hubei Province,30–40 years old,Cancer0016359814159,unknown,30–40 years old,Cancer${dag.offset}0
1
${dag.loopTimes}1
2
${dag.foreach.current[0]}00163598108210016359814159${dag.loopDataArray[1][0]} ${dag.loopDataArray[1][0]}0016359814159