Data Integration では、DataHub、Kafka、LogHub(SLS)などのソースから、単一テーブルのデータを MaxCompute へリアルタイムで同期できます。本ガイドでは、DataWorks コンソール上で 単一 Logstore リアルタイム同期 タスクを作成・実行し、LogHub(SLS)の Logstore から MaxCompute へリアルタイムデータを同期する手順について説明します。
前提条件
開始する前に、以下の条件を満たしていることを確認してください。
-
サーバーレスリソースグループまたはデータ統合専用リソースグループです。詳細については、「サーバーレスリソースグループ」および「データ統合専用リソースグループ」をご参照ください。
-
LogHub(SLS)データソースおよび MaxCompute データソース。詳細については、「データソースの構成」をご参照ください。
-
リソースグループと両方のデータソース間のネットワーク接続性。詳細については、「ネットワーク接続ソリューションの概要」をご参照ください。
制限事項
ソースデータを MaxCompute の外部テーブルへ同期することはサポートされていません。
同期タスクの作成と構成
作成ウィザードは 8 つのステップで構成されています。ステップ 4、5、6 は任意であり、タスクを保存後に再編集できます。
ステップ 1:同期タスクのタイプを選択
-
DataWorks コンソールにログインします。上部ナビゲーションバーで目的のリージョンを選択します。左側ナビゲーションウィンドウで、データ統合 > データ統合 を選択します。表示されたページで、ドロップダウンリストからご利用のワークスペースを選択し、データ統合へ移動 をクリックします。
-
ナビゲーションウィンドウで、同期タスク をクリックします。ページ上部の 同期タスクの作成 をクリックし、以下の項目を構成します。
-
ソース:
LogHub -
送信先:
MaxCompute -
タスク名:同期タスクの名前を入力します。
-
タスクタイプ:
単一 Logstore リアルタイム同期
-
ステップ 2:ネットワークおよびリソースの構成
-
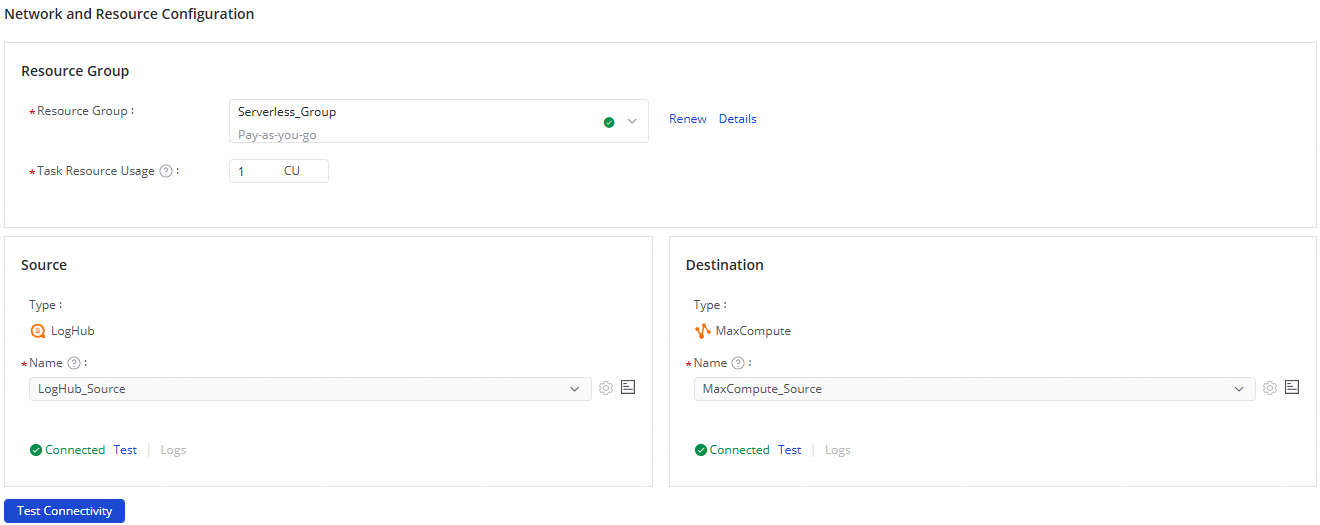
ネットワークおよびリソースの構成 セクションで、同期タスク用の リソースグループ を選択します。タスクのリソース使用量 については、ご要件に応じて CU(Compute Unit)を割り当てます。
-
ソース をご利用の LogHub(SLS)データソースに、送信先 をご利用の MaxCompute データソースに設定し、接続性のテスト をクリックします。
-
両方のデータソースが正常に接続されたことを確認後、次へ をクリックします。
ステップ 3:同期リンクの構成
同期リンクは、SLS ソース、オプションのデータ処理ノード、MaxCompute 送信先の 3 つの部分で構成されます。各要素を順に構成します。
SLS ソースの構成
ページ上部の SLS ソースをクリックして、ソース情報 パネルを開きます。

-
ソース情報 セクションで、同期対象の Logstore を選択します。
-
右上隅の データサンプリング をクリックします。開始時刻 および サンプルデータレコード数 を指定し、収集開始 をクリックします。これにより、Logstore からデータがサンプリングされ、下流ノードの構成用のプレビューが生成されます。
-
Logstore を選択すると、そのフィールドが自動的に 出力フィールドの構成 セクションに読み込まれます。必要に応じて データ型 を調整し、削除 で不要なフィールドを除去したり、出力フィールドの追加 で新しいフィールドを追加できます。
SLS に存在しないフィールドを構成した場合、その値は下流ノードに対して NULL として出力されます。
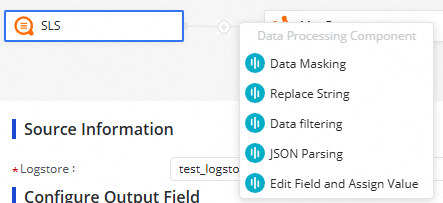
データ処理ノードの追加(任意)
ソースと送信先の間にデータ処理ノードを挿入するには、![]() アイコンをクリックします。利用可能な方法は以下のとおりです。
アイコンをクリックします。利用可能な方法は以下のとおりです。
| 方法 | 使用タイミング |
|---|---|
| データマスキング | 送信先に書き込む前に、機密フィールドを匿名化する |
| 文字列置換 | フィールド内の文字列を検索して置き換える |
| データフィルタリング | 指定した条件に一致しないレコードを除外する場合 |
| JSON 解析 | JSON 形式のカラムからフィールドを抽出する場合 |
| フィールドの編集と値の割り当て | 派生カラムを追加するか、フィールド値を上書きする場合 |
データを処理する順序に従って、ノードを並べ替えます。実行時には、データは指定した順序でノードを通過します。
ノードの出力を検証するには、右上隅の 出力データのプレビュー をクリックし、その後 親ノードの出力の再取得 をクリックして、サンプリングされたログデータからの出力をシミュレートします。
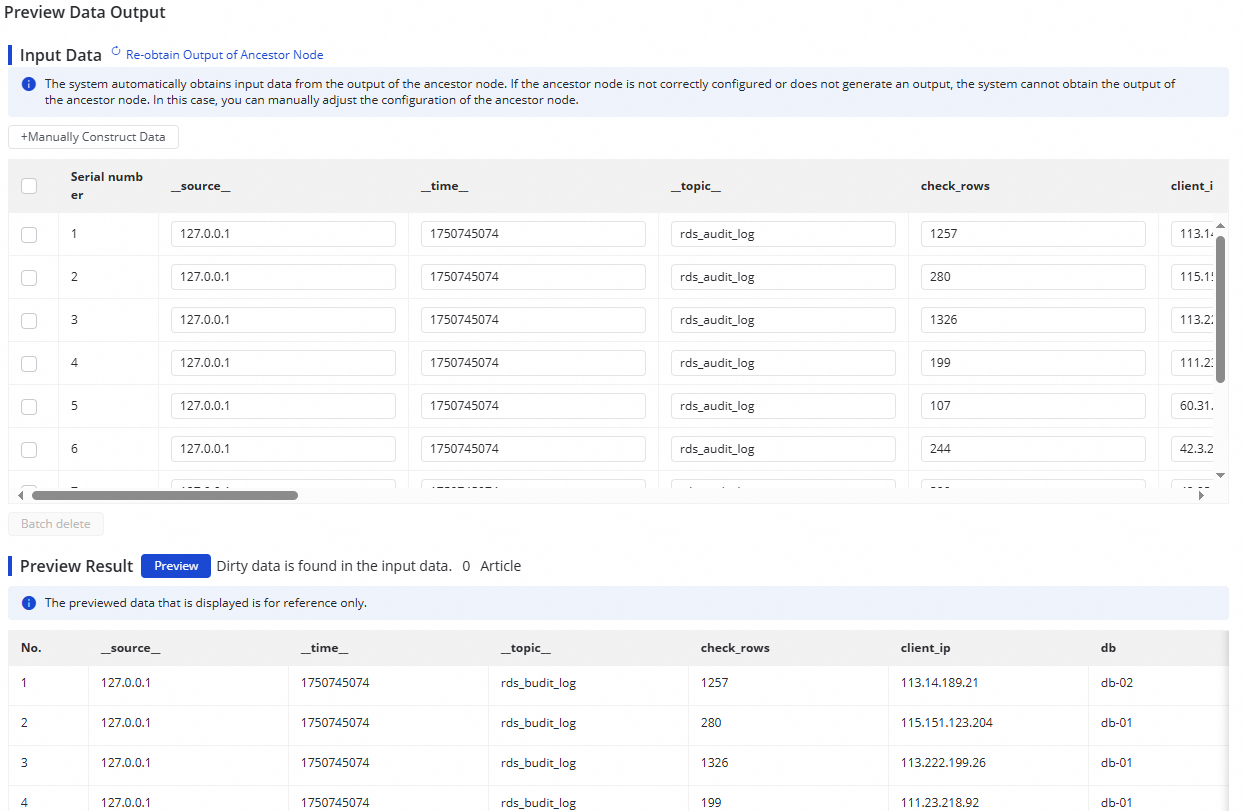
出力データのプレビューには、SLS ソースでのデータサンプリングが完了している必要があります。プレビューが利用できない場合は、まずデータサンプリングを完了してください。
MaxCompute 送信先の構成
ページ上部の MaxCompute 送信先をクリックして、送信先情報 パネルを開きます。

-
送信先情報 エリアで、送信先テーブルの作成方法を選択します。
-
テーブルを自動作成:ソーステーブルと同じ名前のテーブルが作成されます。必要に応じて名前を変更できます。
-
既存テーブルの使用:ドロップダウンリストから既存のテーブルを選択します。
-
-
(任意)送信先テーブルスキーマの編集。[テーブルを自動作成] を選択した場合は、テーブルスキーマの編集 をクリックしてスキーマをカスタマイズできます。また、親ノードの出力カラムに基づくテーブルスキーマの再生成 をクリックすることで、上流ノードの出力カラムからスキーマを自動生成できます。カラムを選択し、プライマリキーとしてマークします。
送信先テーブルにはプライマリキーが必要です。プライマリキーが設定されていないと、タスク構成を保存できません。
-
フィールドマッピングを確認します。送信先の構成を完了すると、システムが自動的に同名のフィールドをマッピングします(同名フィールドのマッピング)。必要に応じてマッピングを調整できます。1 つのソースフィールドを複数の送信先フィールドにマッピングできますが、複数のソースフィールドを同一の送信先フィールドにマッピングすることはできません。マッピングされていないソースフィールドは同期されません。
-
パーティション方法を選択します。
-
自動時刻ベースパーティション:時刻に基づいてデータを自動的にパーティション分割します。
-
フィールド値による動的パーティション:指定したフィールドの値に基づいてデータをパーティション分割します。
-
ステップ 4:アラートルールの構成(任意)
タスクの開始前にアラートルールを構成してください。最初からアラート機能を設定しておくことで、配信失敗の検出および診断が大幅に容易になります。
同期タスクでデータ遅延を引き起こす可能性のある問題が発生した際に通知を受け取るため、アラートルールを設定します。
-
構成ページの右上隅で、アラートルールの構成 をクリックし、リアルタイム同期サブノード向けアラートルール構成 パネルを開きます。
-
アラートルールの追加 をクリックし、アラートパラメーターを構成します。
ここで構成したアラートルールは、この同期タスクによって生成されるリアルタイム同期サブタスクに適用されます。同期タスクを保存した後は、リアルタイム同期タスクページからアラートルールを変更することもできます。詳細については、「リアルタイム同期タスクの実行と管理」をご参照ください。
-
必要に応じてアラートルールを有効化または無効化します。重大度レベルに応じて異なるアラート受信者を割り当てます。
ステップ 5:詳細設定の構成(任意)
右上隅の 詳細設定の構成 をクリックして、詳細設定値を表示・変更します。
予期しないエラーまたはデータ品質の問題を回避するため、各パラメーターの値を変更する前に、その効果を十分に理解してください。
ステップ 6:リソースグループ設定の確認(任意)
右上隅の リソースグループの構成 をクリックして、この同期タスクに割り当てられたリソースグループを表示・変更します。
ステップ 7:シミュレート実行によるテスト
タスクを開始する前に、サンプルデータを用いたシミュレート実行を行い、構成内容を検証します。
-
右上隅の シミュレート実行 をクリックします。
-
ダイアログボックスで、開始時刻 および サンプルデータレコード数 を設定し、収集開始 をクリックしてソースからデータをサンプリングします。
-
プレビュー をクリックして、サンプリングされたデータを送信先テーブルへプッシュします。
同期タスクの特定の構成が無効である場合、テスト実行中に例外が発生した場合、またはダーティデータが生成された場合、システムはリアルタイムでエラーを報告します。これにより、同期タスクの構成を早期に確認し、期待通りの結果が得られるかどうかを迅速に判断できます。
ステップ 8:同期タスクの開始
-
すべての構成を完了したら、ページ下部の 完了 をクリックします。
-
データ統合 > 同期タスク に移動します。作成したタスクを見つけ、操作 列の 開始 をクリックします。
-
タスク セクションのタスク 名または ID をクリックして、実行中の詳細な進行状況を表示します。
同期タスクのモニターと管理
タスク実行状態の表示
同期タスクを作成した後は、同期タスクページからその状態をモニターできます。

操作 列を使用してタスクを 開始 または 停止 できます。その他 をクリックすると、編集 や 表示 などの追加操作が利用可能です。
実行概要 セクションには、実行状態が表示されます。タスクをクリックすると、実行の詳細を表示できます。
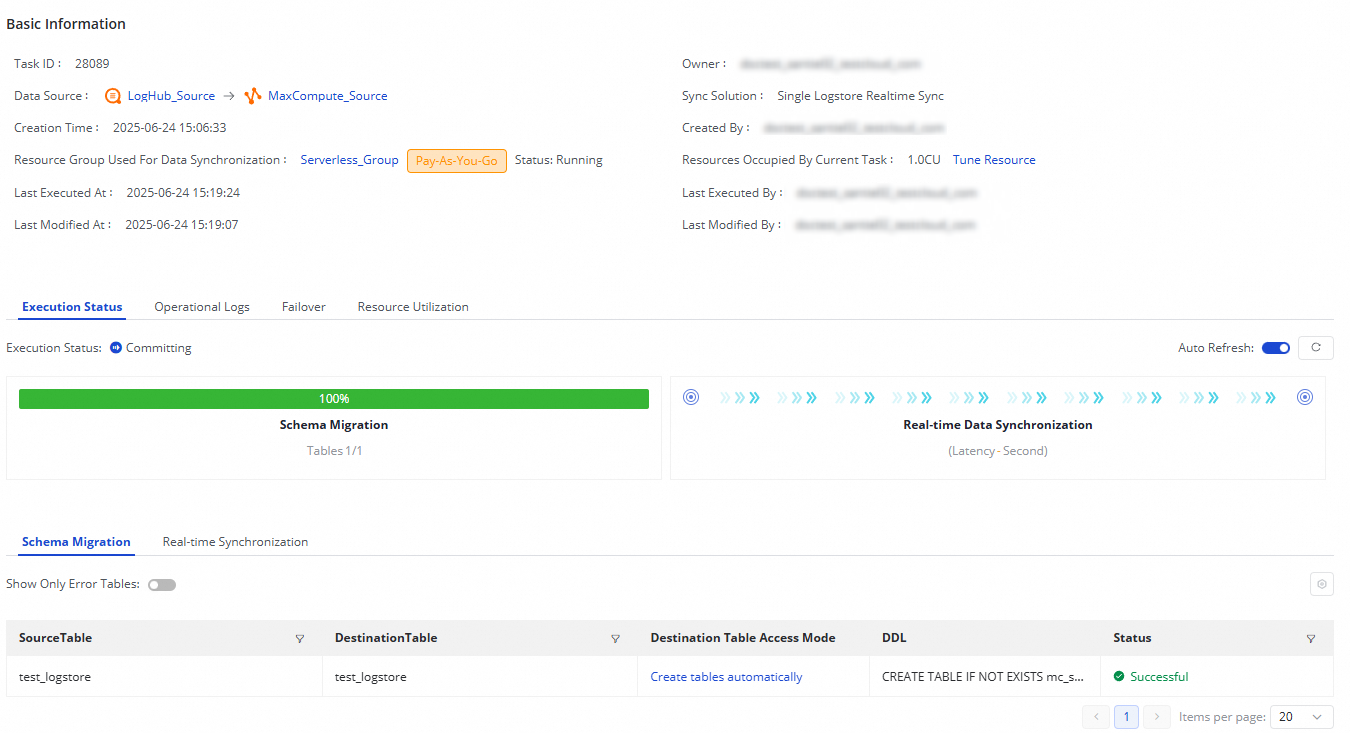
各 LogHub(SLS)から MaxCompute への同期タスクは、以下の 2 つのステージで実行されます。
-
スキーマ移行:既存のテーブルを使用するか、新規テーブルを作成するかを確認します。自動テーブル作成が選択されている場合、テーブルの DDL(Data Definition Language)文がここに表示されます。
-
リアルタイムデータ同期:パフォーマンス統計、リアルタイム実行情報、DDL レコード、およびアラートの詳細が表示されます。
同期タスクの再実行
同期対象のフィールド、送信先テーブルのフィールド、またはテーブル名を変更する必要がある場合、同期タスクを再実行します。システムは変更分のみを同期し、すでに同期済みで変更のないデータは再処理されません。
再実行には、以下の 2 つの方法があります。
-
構成変更なしでの再実行:再実行 を 操作 列からクリックして、現在の構成でタスクを再実行します。
-
構成変更後の再実行:タスク構成を変更し、完了 をクリックします。その後、操作 列の 更新の適用 をクリックして、更新された構成で再実行します。