ユーザーレビュー、製品説明、カスタマーサービスログなどの非構造化テキストデータの処理は、データパイプラインにおける一般的な課題です。DataWorks のパイプライン内で、大規模言語モデル (LLM) の強力な機能を直接利用できます。自然言語の指示により、テキスト要約、感情分析、コンテンツ分類、情報抽出などの高度な AI タスクを実行できます。これによりデータ処理ワークフローが簡素化され、データエンジニアやアナリストは、複雑なアルゴリズムを記述することなく、既存の抽出、変換、ロード (ETL) パイプラインに AI 機能を統合できます。
前提条件
DataWorks でモデルサービスをデプロイします。詳細については、「モデルをデプロイする」をご参照ください。
モデルとリソース仕様の選択は、モデルサービスのパフォーマンスと応答速度に直接影響します。また、モデルサービスでは リソースグループ料金が発生します。
LLM ノードの設定
いくつかの簡単な設定で、大規模言語モデルノードを設定して実行できます。
|
パラメーター |
説明 |
|
モデルサービス |
前提条件でデプロイしたモデルサービスです。 |
|
モデル名 |
モデルサービスで使用するモデルです。デフォルトでモデルが選択されています。 |
|
システムプロンプト |
大規模言語モデルの振る舞い (役割、機能、ルールなど) を定義します。 パラメーターを参照するには、${param} 形式を使用します。 |
|
ユーザープロンプト |
具体的な質問または指示を入力します。DataWorks には、すぐに利用できる 4 つの組み込みテンプレートが用意されています。 ${param} 形式を使用してパラメーターを参照します。 例:プロンプトに「Select the items that match |
例
この例では、パイプラインで大規模言語モデルノードを使用し、ノード間でパラメーターを受け渡す方法を示します。
-
DataWorks LLM service にログインし、Qwen3-1.7B に基づいてモデルサービスを作成します。[Resource Group] では、現在のワークスペースにバインドされているリソースグループを選択します。
-
Data Studio に移動し、次のノードを含むパイプラインを作成します。
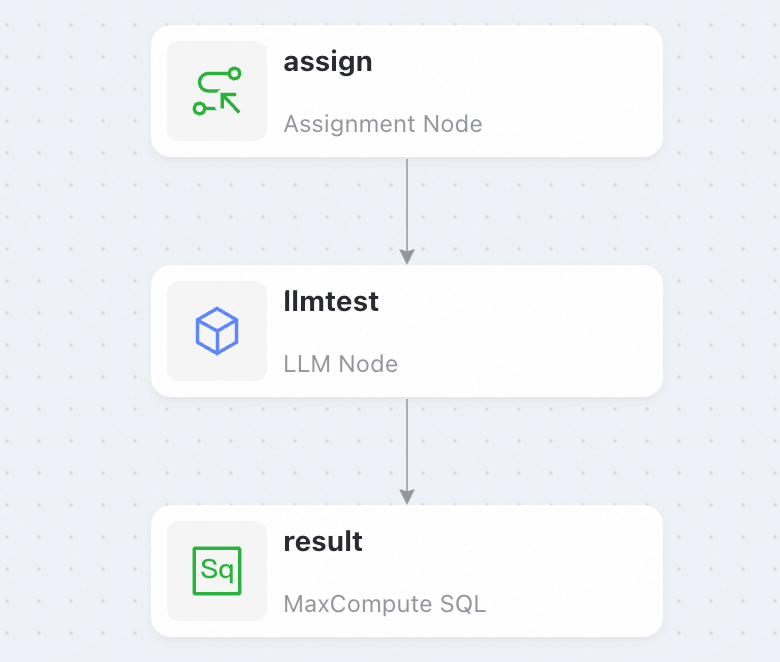
-
代入ノードを設定します。右下のツールバーで言語を Shell に設定し、次のコードを入力します。
このノードの詳細については、「割り当てノード」をご参照ください。
echo 'DataWorks'; -
大規模言語モデルノードを設定します。
-
事前に設定したモデルサービスとモデル名を選択します。
-
ユーザープロンプトを次のように設定します:
Write an introduction about ${title} with a word limit of ${length}. -
右側の設定パネルで、 を選択し、リソースグループを大規模言語モデルサービスの作成時に選択したものに変更します。
-
右側の設定パネルの の下に、値を アップストリームノードの出力 とするパラメーター title と、固定値を 300 とするパラメーター length を追加します。
アップストリームノードの出力をバインドするには、値入力フィールドの右側にある
 アイコンをクリックします。
アイコンをクリックします。
-
-
大規模言語モデルの結果を取得するように、MaxCompute SQL ノードを設定します。
重要MaxCompute SQL ノードを MaxCompute リソースにバインドする必要があります。リソースがない場合は、代わりに Shell ノードを使用して出力を表示できます。
-
次のコードを入力します:
select '${content}'; -
右側の設定パネルで、 を選択し、リソースグループを大規模言語モデルサービスの作成時に選択したものに変更します。
-
右側の の下に、パラメーター content を追加し、その値を アップストリームノードの出力 に設定します。
アップストリームノードの出力をバインドするには、値入力フィールドの右側にある
アイコンをクリックします。バインド後、パラメーター値は The outputs parameter of the llmtest node is bound と表示されます。
-
-
パイプラインに戻り、上部の Run をクリックし、ポップアップウィンドウで実行パラメーターを入力します。
-
実行が成功すると、MaxCompute SQL ノードは大規模言語モデルから次のような結果を返します:
DataWorks is an enterprise data development and management platform from Alibaba Cloud. It supports data collection, cleansing, integration, scheduling, and visualization for large-scale data processing. It provides a visual interface, connects to various data sources, and features powerful task scheduling and data quality monitoring. DataWorks handles both real-time and batch processing, helping enterprises manage data as assets and improve efficiency. Its unified process helps build reliable data pipelines for data governance and intelligent analysis.