DataWorks のデータ統合における単一テーブルリアルタイム同期タスクでは、JSON 解析コンポーネントを使用して、ソースからの JSON データを対応するテーブルデータに解析できます。
JSON 解析コンポーネントの作成と設定
ステップ 1: データ統合タスクの設定
-
データソースを作成します。詳細については、「データソース管理」をご参照ください。
-
データ統合タスクを作成します。詳細については、「単一テーブルリアルタイム同期タスクの設定」をご参照ください。
説明単一テーブルリアルタイムデータ統合タスクでは、ソースコンポーネントと送信先コンポーネントの間にデータ処理コンポーネントを追加できます。詳細については、「サポートされているデータソースと同期ソリューション」をご参照ください。
ステップ 2: JSON 解析コンポーネントの追加
単一テーブルリアルタイム同期タスクで、Data Processing スイッチをオンにし、[+ノードを追加] をクリックして、JSON Parsing コンポーネントを追加します。
ノードの名前と説明を入力し、JSON 解析コンポーネントを設定します。
重要JSON データ構造を取得するには、まずソースデータコンポーネント (Kafka など) で Data Sampling を完了する必要があります。
固定 JSON 解析フィールドの追加
フォーマット済みの JSON データを取得します。
JSON ソース
説明
図
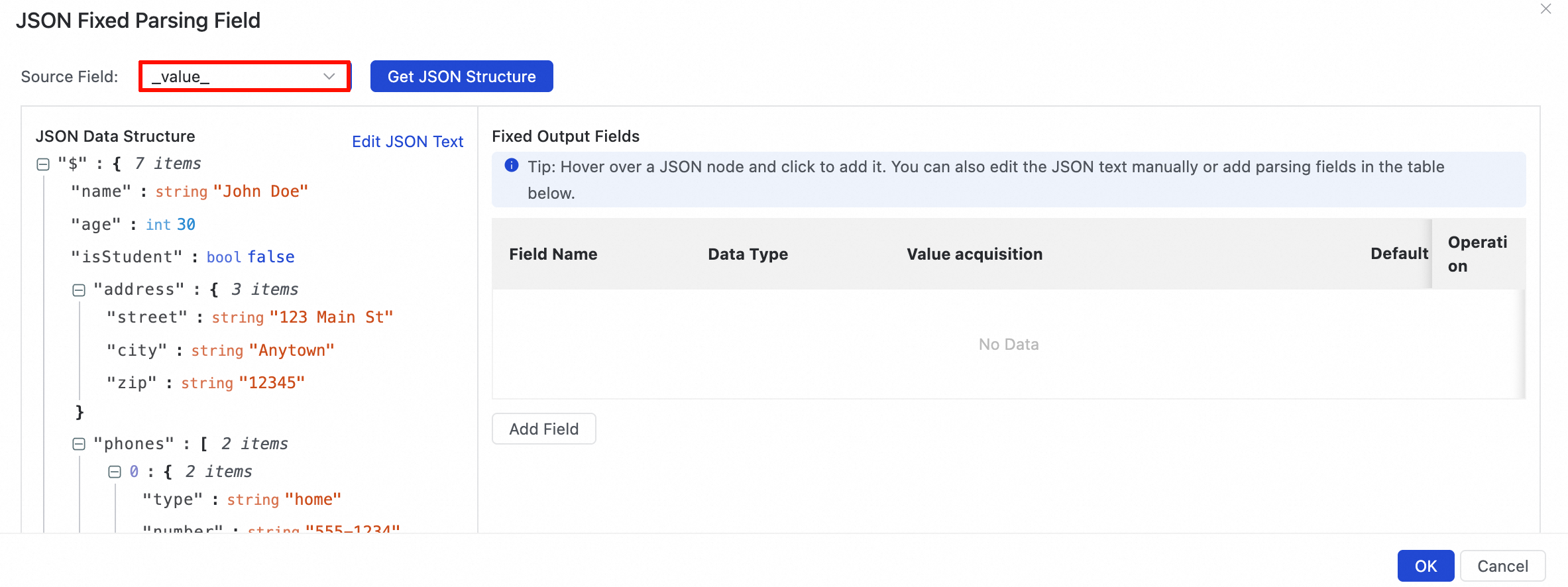
データサンプリングから JSON データを取得
データサンプリングを実行した後、Add Fixed Parsing Field をクリックします。JSON Fixed Parsing Field ダイアログボックスで、ソースフィールドを選択し、Get JSON Structure をクリックして JSON 構造を取得します。
手動で入力した JSON データを取得
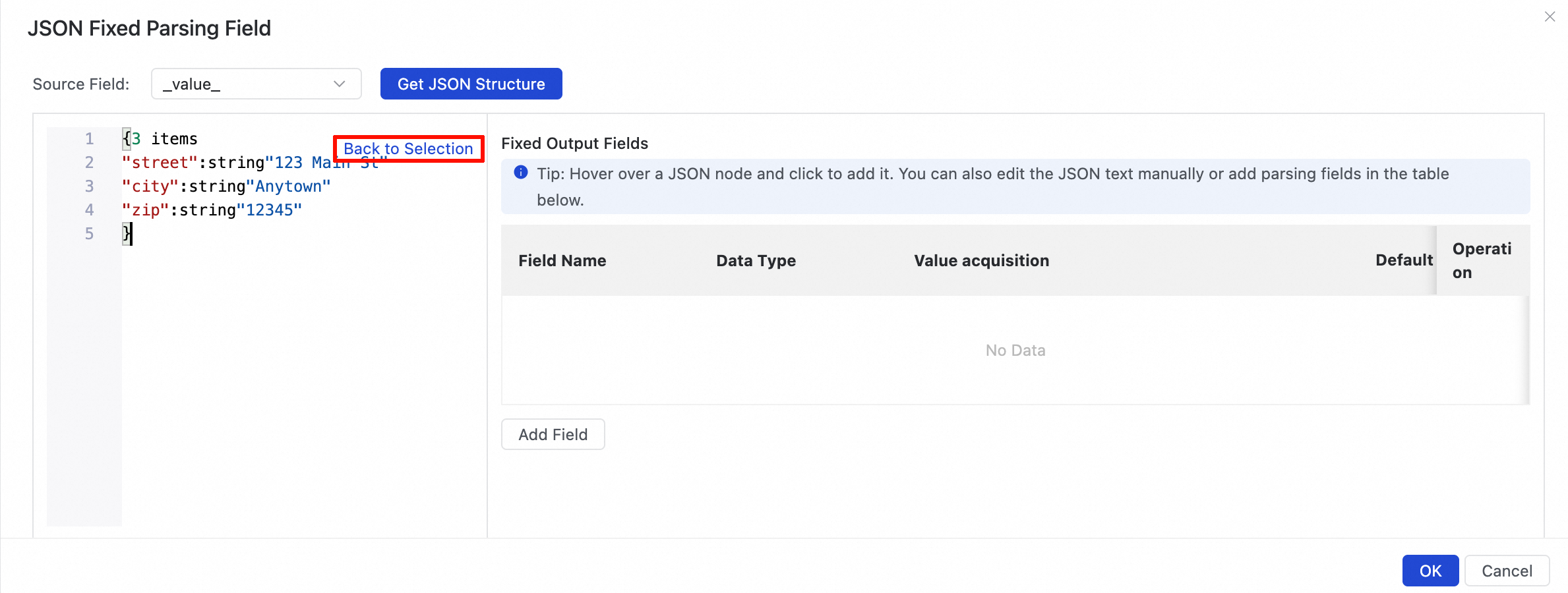
データサンプリングを実行していない場合や、ソースデータが空の場合は、手動でフィールドを編集できます:
[JSON テキストの編集] ボタンをクリックして編集モードに入ります。[JSON テキストの編集] ウィンドウで、手動で JSON コンテンツを入力し、Back to Selection をクリックしてフィールドを選択します。
JSON Data Structure ビューで、
 アイコンをクリックしてリーフノードを選択します。対応する解析ルールが Fixed Output Fields セクションに自動的に追加されます。
アイコンをクリックしてリーフノードを選択します。対応する解析ルールが Fixed Output Fields セクションに自動的に追加されます。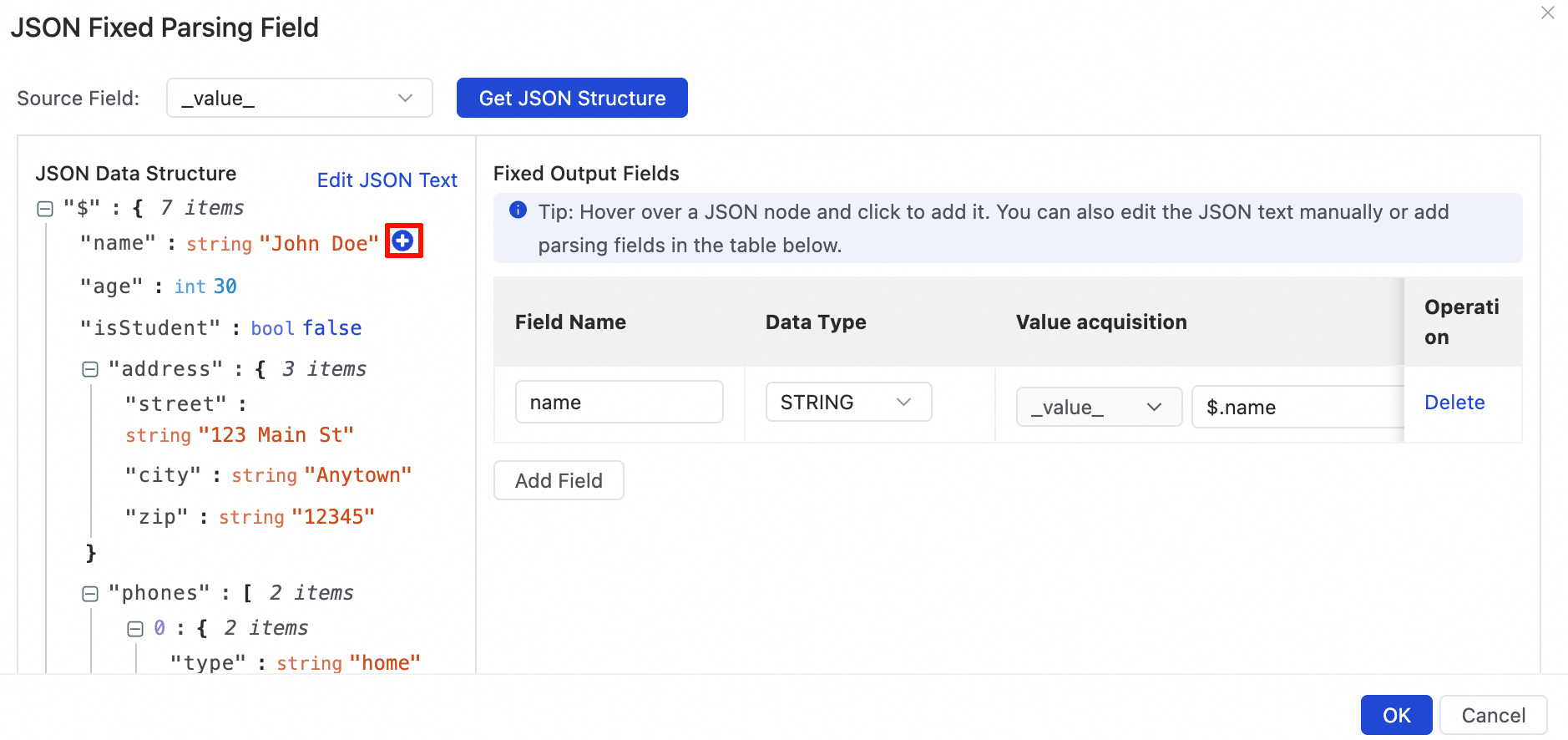
JSON のリーフノードを解析して生成されたテーブルの例。
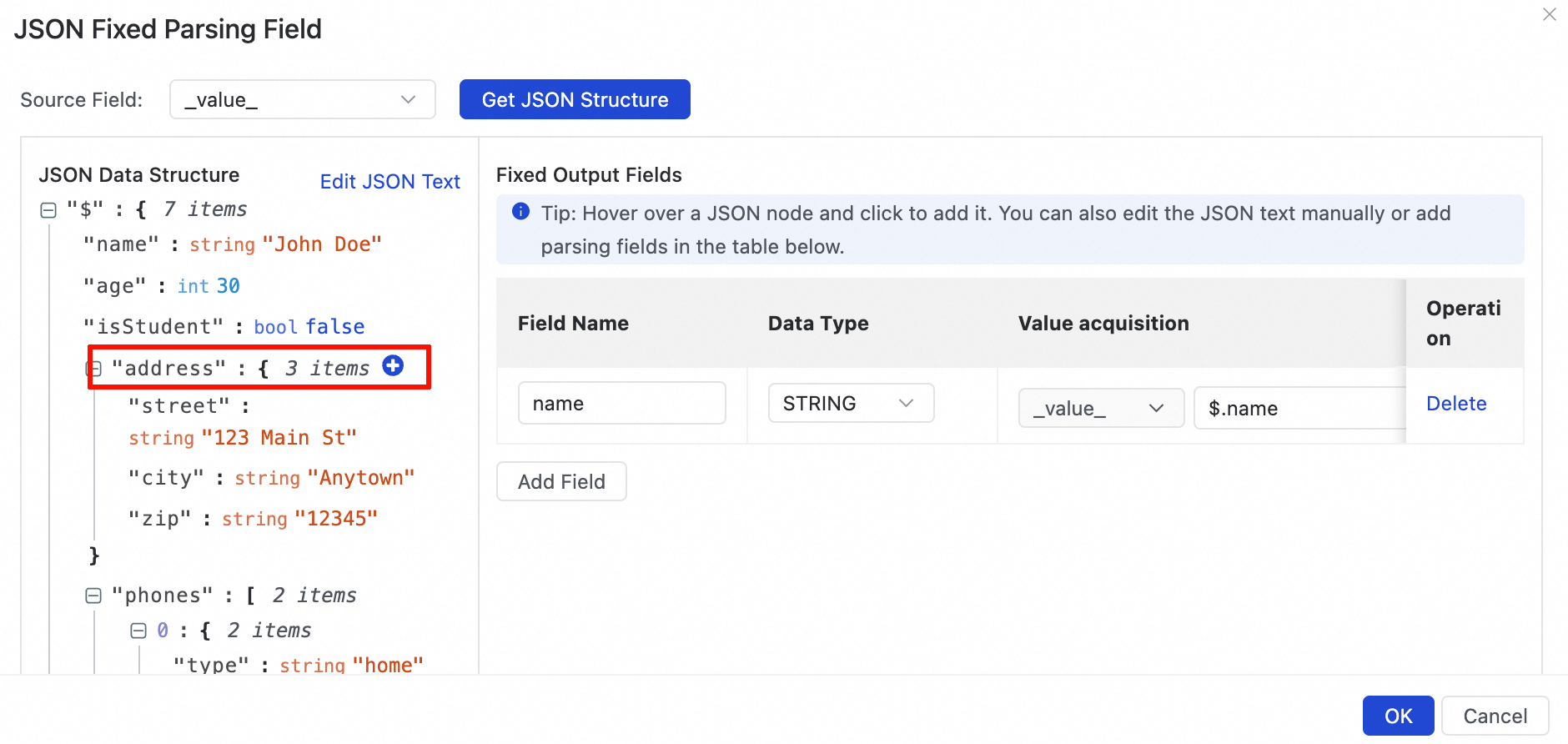
JSON Data Structure ビューで、解析対象のフィールドを選択します。JSON オブジェクトを選択した場合 (例えば、address フィールドの横にある
アイコンをクリックした場合)、ダイアログボックスが表示されます。その後、次のいずれかの解析メソッドを選択できます:JSON オブジェクト内の各キーと値のペアを個別のフィールドとして追加します。キーがフィールド名として使用され、対応する値が割り当てられます。
JSON オブジェクト全体を単一のフィールドとして追加します。値はオブジェクトの JSON 文字列です。
オプション
図
解析結果
[JSON オブジェクト内の各キーと値のペアを個別のフィールドとして追加し、キーをフィールド名、値を対応する値とする] を選択します。
これにより、オブジェクトは
street、city、zipの 3 つのフィールドに解析され、それぞれに対応する値が割り当てられます。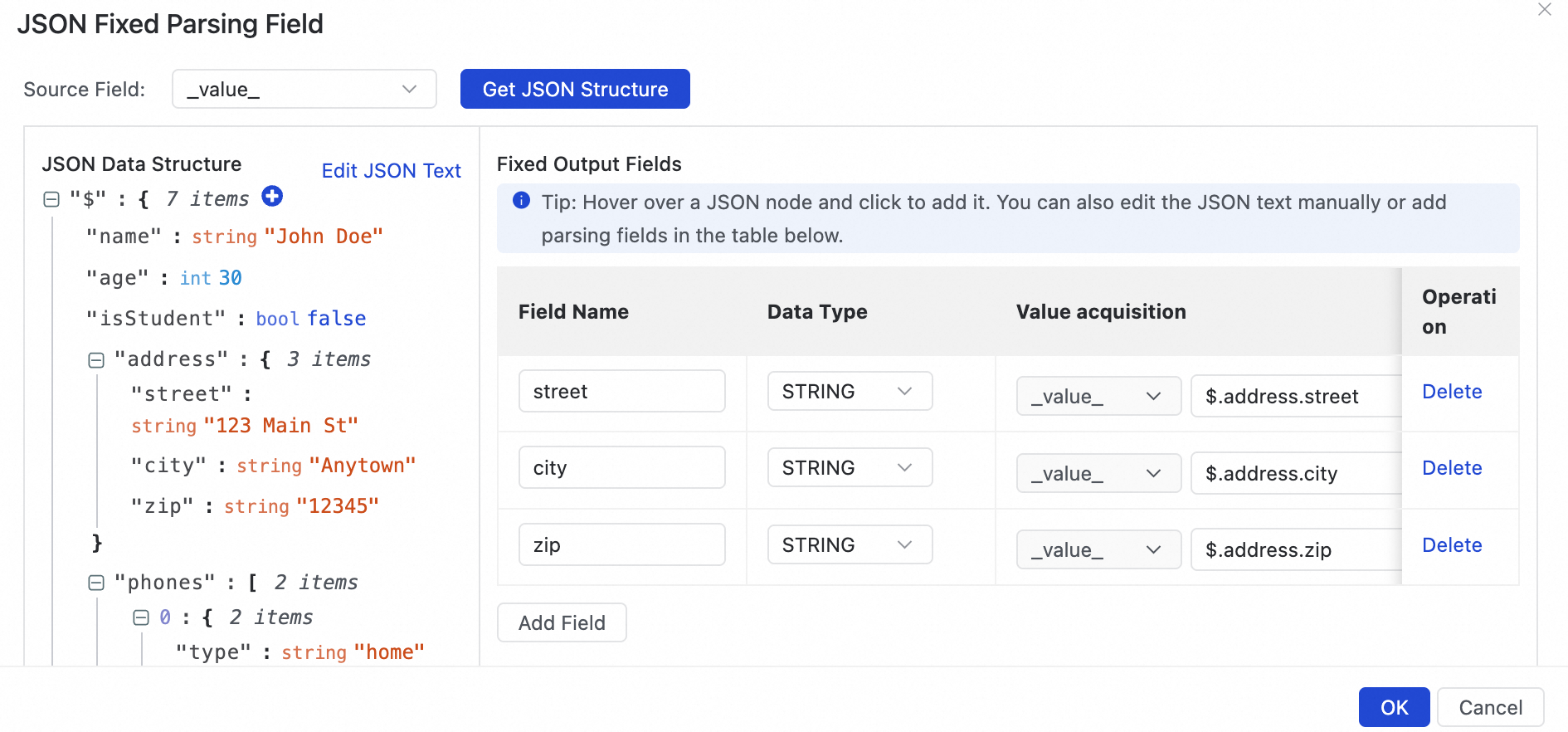
[JSON オブジェクト全体を単一のフィールドとして追加し、値をオブジェクトの JSON 文字列とする] を選択します。
これにより、address オブジェクト全体が単一のデータレコードに解析されます。このフィールドの値は、
street、city、zipキーを含む JSON 文字列です。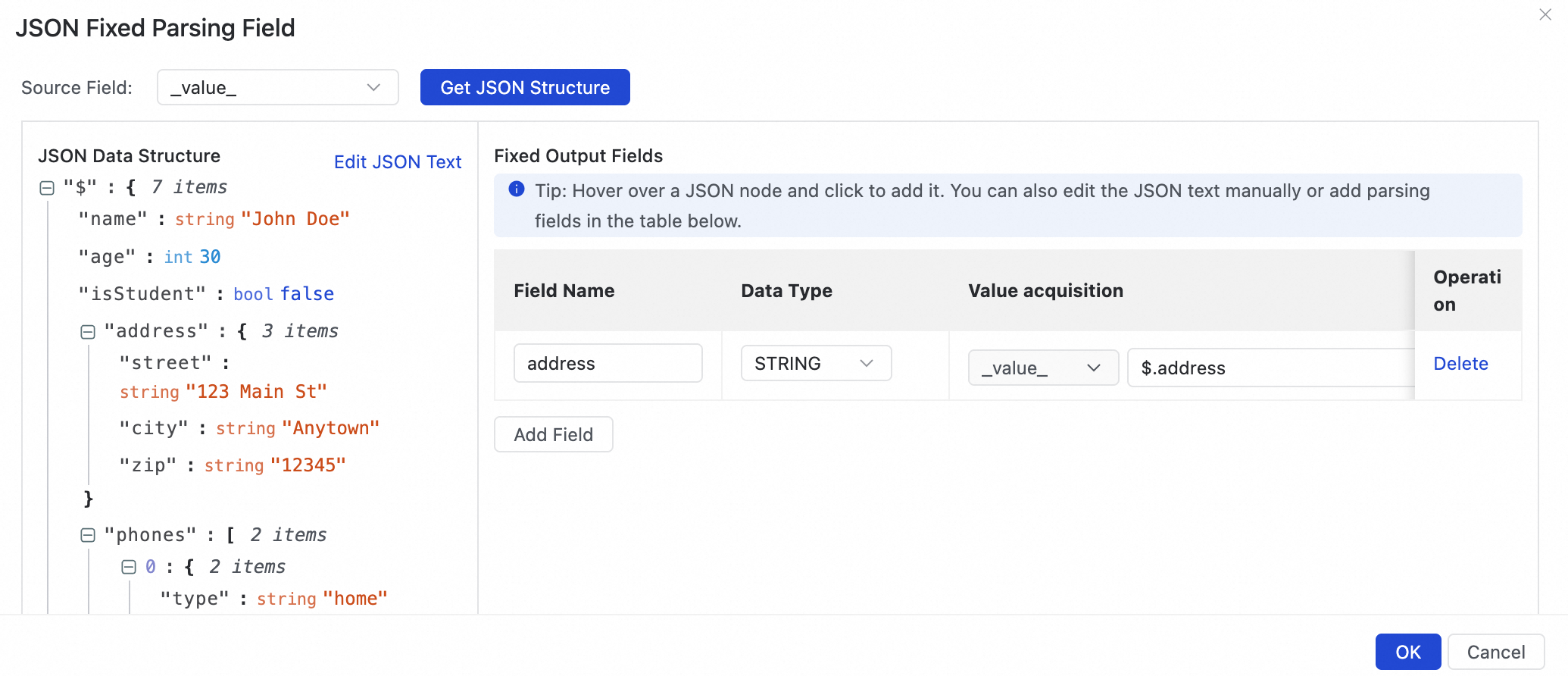
JSON Data Structure ビューで、解析対象のフィールドを選択します。JSON 配列を選択した場合、ダイアログボックスが表示されます。次のいずれかの解析メソッドを選択できます:
配列を複数行出力として追加します。
配列全体を単一のフィールドとして追加します。値は配列の JSON 文字列です。
オプション
図
解析結果
図の JSON について、配列フィールドの横にある
アイコンをクリックし、ダイアログボックスで [配列を複数行出力として追加] を選択します。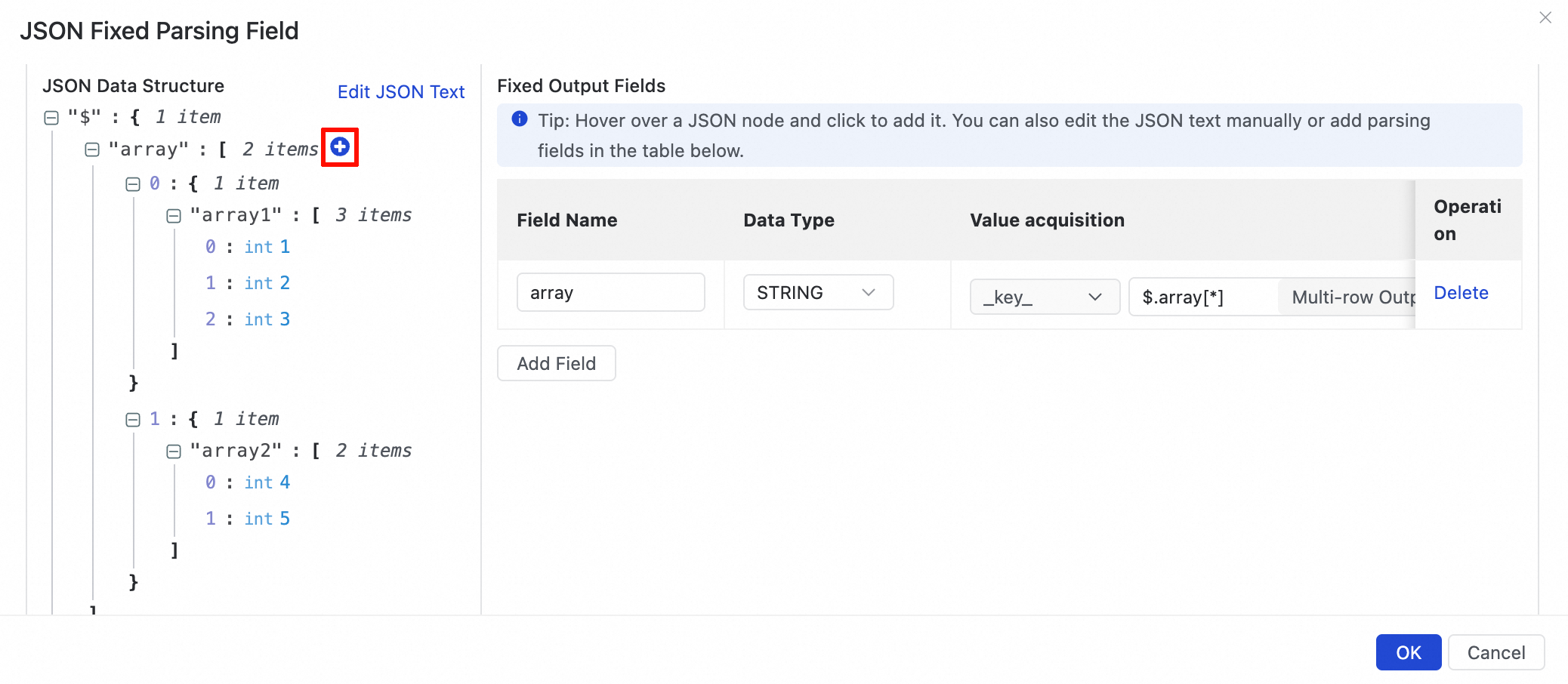
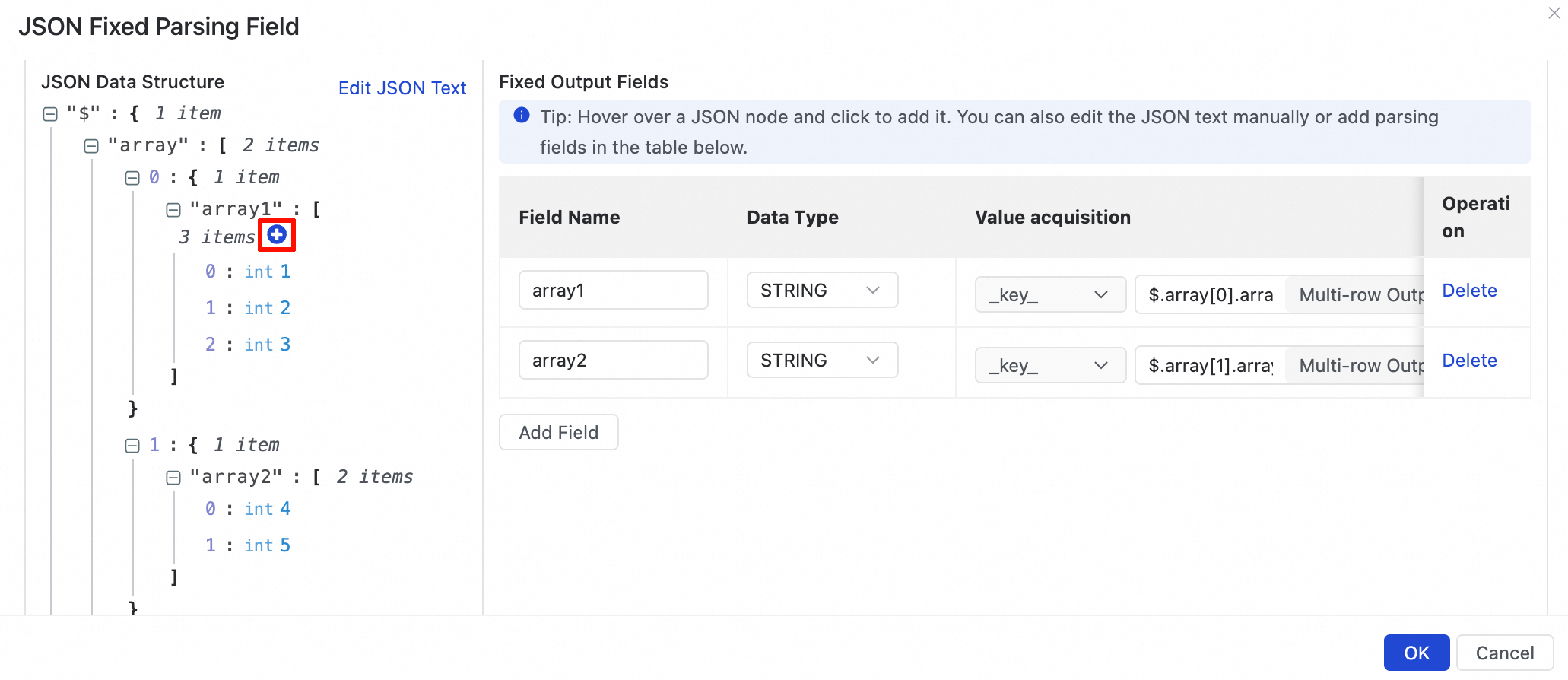
図の JSON について、array1 と array2 フィールドの横にある
アイコンをクリックし、ダイアログボックスで [配列を複数行出力として追加] を選択します。説明配列にオブジェクトが含まれ、オブジェクト内の値も配列である場合、このネストされた配列は解析されません。
図の JSON について、配列フィールドの横にある
アイコンをクリックし、[配列全体を単一のフィールドとして追加し、値を配列の JSON 文字列とする] を選択します。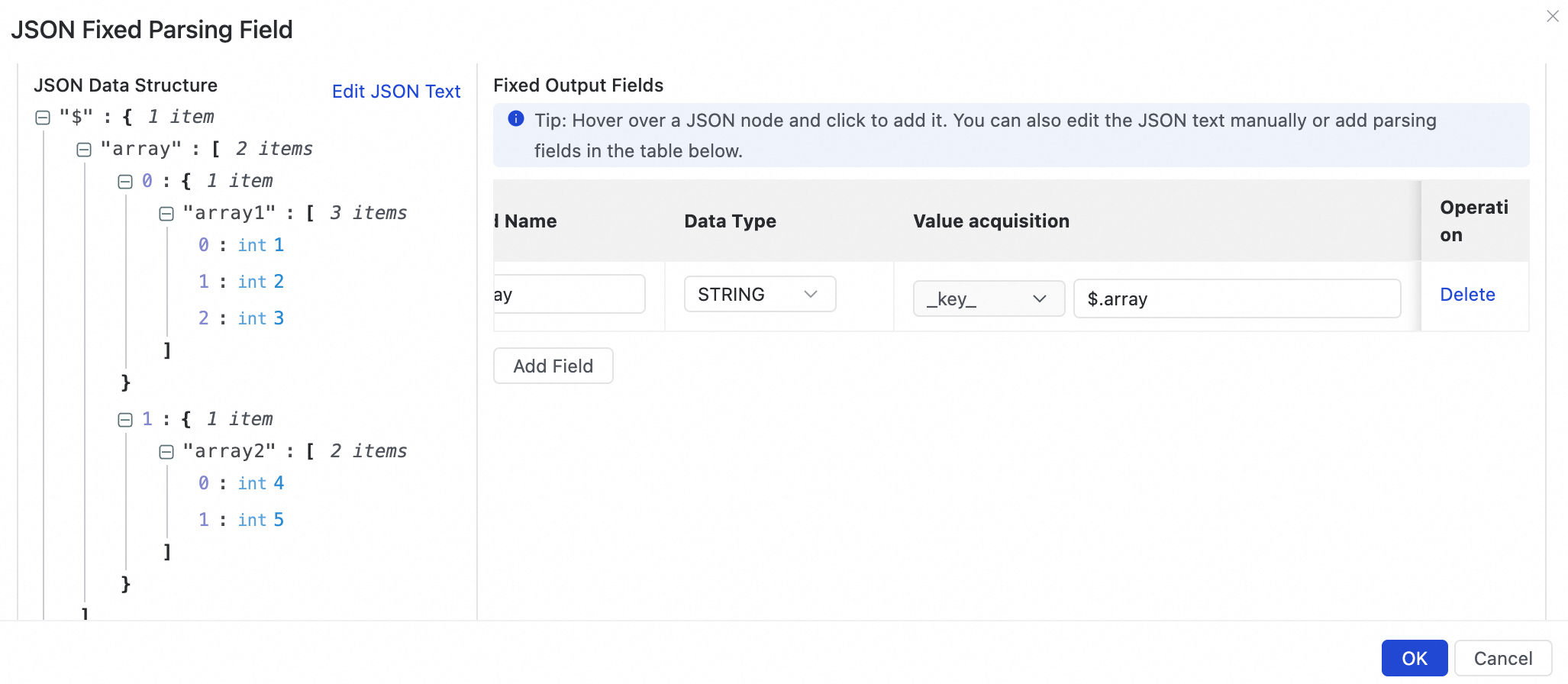
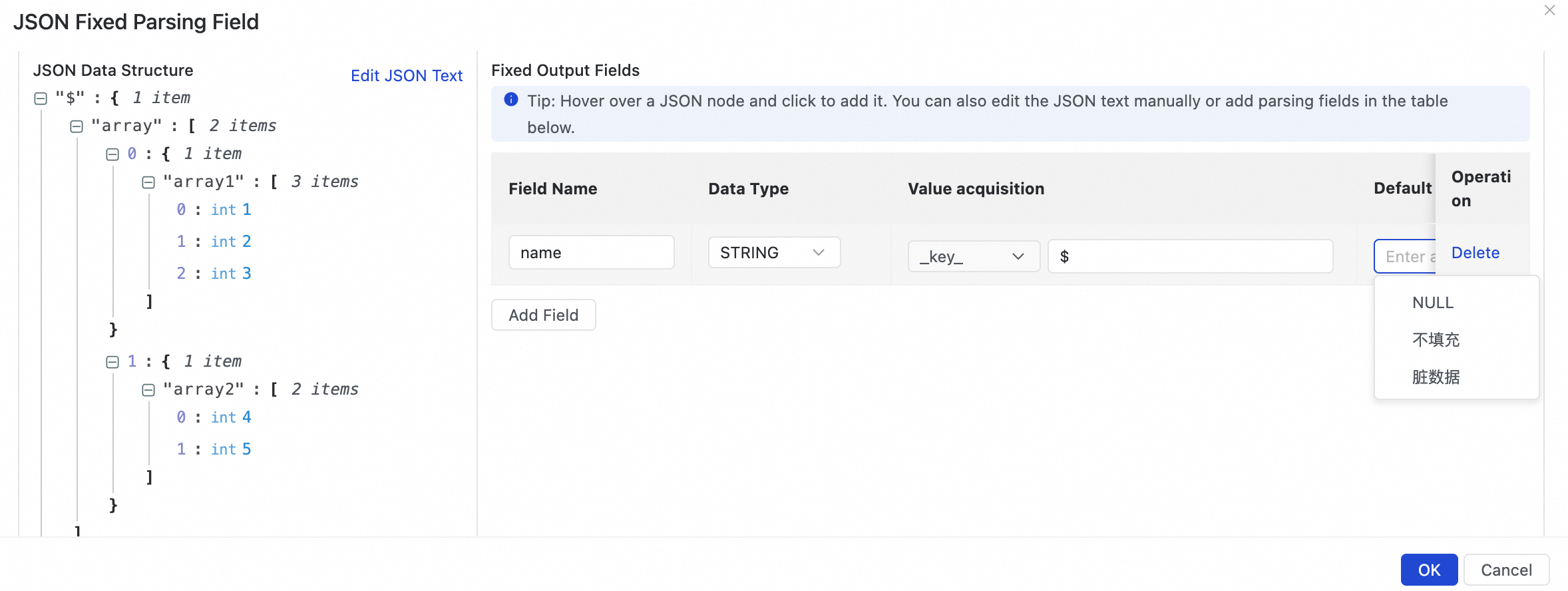
手動で Add Field をクリックします。アップストリームのフィールド値を取得できず、[JSON テキストの編集] ボタンで JSON コンテンツをアップロードしていない場合は、値のコンテンツを編集して手動で固定フィールド解析ルールを定義できます。手動でフィールドを追加するためのパラメーターは次のとおりです:
パラメーター
説明
Field
解析後の新しいフィールドの名前。ダウンストリームノードはこの名前を使用してフィールドを参照します。
Value acquisition
JSON 解析パスを指定します。構文は次のとおりです:
$:ルートノード。.:子ノード。[]:[number]は配列インデックスを示し、0 から始まります。[*]:配列を複数行出力に展開します。各要素はレコード内の他のフィールドと組み合わされて新しい行を形成し、ダウンストリームノードに送信されます。
説明JSON 解析パス内の JSON フィールド名には、英字、数字、ハイフン (-)、アンダースコア (_) のみを含めることができます。
Default
指定された JSON パスが存在しない場合に使用するデフォルト値。これは、例えば、アップストリームテーブルのフィールドが変更された場合に発生する可能性があります。
NULL:フィールドに NULL 値が割り当てられます。
Do Not Fill:フィールドは入力されません。送信先テーブルの対応するフィールドにデフォルト値がある場合、その値が使用されます。
Dirty Data:レコードをダーティデータとしてマークします。システムは、タスクのダーティデータ許容設定に基づいて処理し、タスクを停止させることがあります。
定数を手動で入力:指定した定数をフィールドの値として使用します。
動的 JSON 解析フィールドの追加
フォーマット済みの JSON コンテンツで、動的解析の対象となる JSON オブジェクトフィールドを選択します。システムは、JSON オブジェクト内の各フィールドの解析設定を固定出力フィールドに自動的に追加します。
動的 JSON オブジェクト解析を設定すると、同期タスクの実際の実行中に、指定されたパスにある各 JSON オブジェクトのすべてのフィールドが、元の JSON フィールド名と値を使用して STRING 型としてレコードに追加され、ダウンストリームノードに出力されます。これにより、同期中に指定された JSON オブジェクトの構造が変更されたり、新しいフィールドが追加されたりした場合でも、システムは自動的にそれらを検出してダウンストリームノードに出力できます。
フォーマット済みの JSON データを取得
JSON ソース
説明
図
データサンプリングから JSON データを取得
データサンプリング後、Add Dynamic Parsing Field をクリックします。[JSON 解析の動的出力フィールドの追加] ダイアログボックスで、ソースフィールドを選択し、Get JSON Structure をクリックして JSON 構造を取得します。
手動で入力した JSON データを取得
データサンプリングを実行していない場合や、ソースデータが空の場合は、手動でフィールドを編集できます:
[JSON テキストの編集] ボタンをクリックして編集モードに入ります。[JSON テキストの編集] ウィンドウで、手動で JSON コンテンツを入力し、Back to Selection をクリックしてフィールドを選択します。
JSON オブジェクトの動的解析
設定:
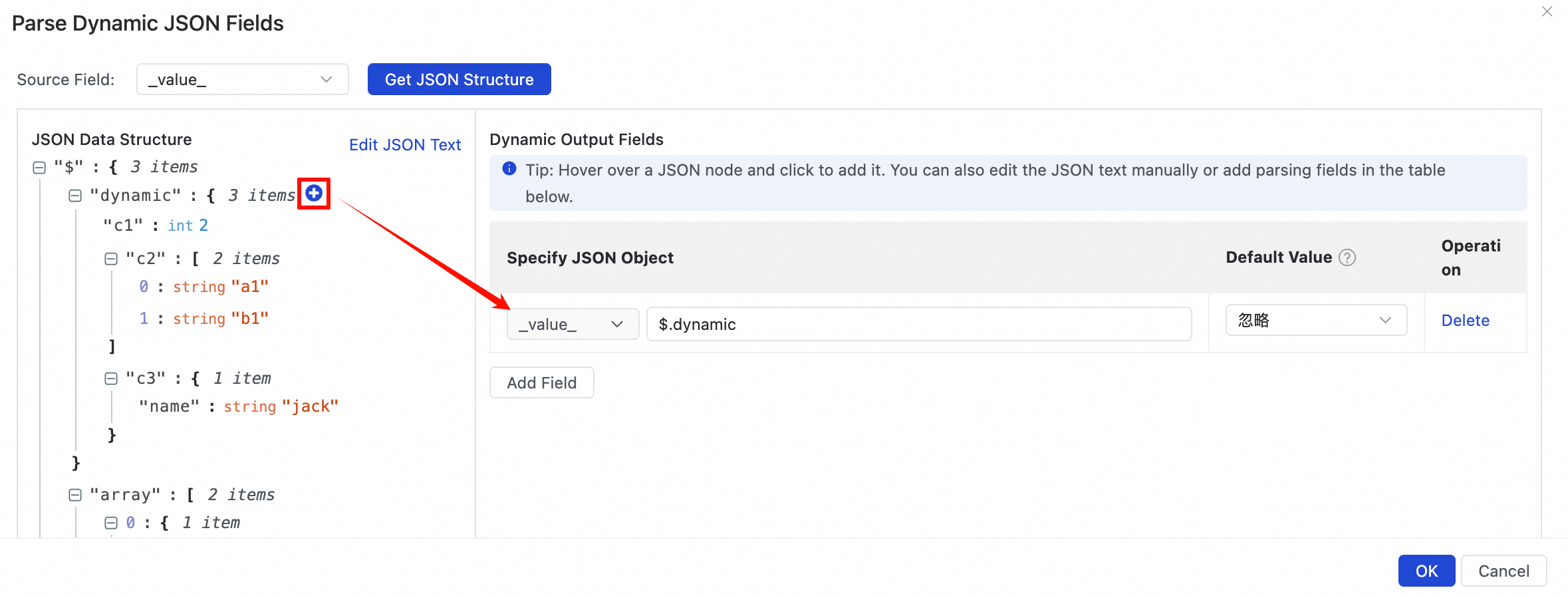
動的オブジェクトに新しいフィールド c3 が追加されたと仮定します。次の表は、解析結果を比較したものです。
_value_(STRING)
c1(STRING)
c2(STRING)
c3(STRING)
{ "dynamic": { "c1": 2, "c2": ["a1","b1"] } }2["a1","b1"]入力しない
{ "dynamic": { "c1": 2, "c2": ["a1","b1"], "c3": {"name": "jack"} } }2["a1","b1"]{"name": "jack"}
手動でのフィールド追加
手動でのフィールド追加とは、アップストリームの子フィールド値を取得できず、[JSON テキストの編集] ボタンで JSON コンテンツをアップロードしていない場合に、手動で固定フィールド解析ルールを定義し、値のコンテンツを編集して動的フィールド解析ルールをカスタマイズすることを意味します:
パラメーター
説明
Specify JSON Object
JSON オブジェクトの解析パスを指定します。解析構文は次のとおりです:
$:ルートノード。.:子ノード。[]:[number] は配列インデックスを示し、0 から始まります。
注意:JSON 解析パス内の JSON フィールド名には、英字、数字、ハイフン (-)、アンダースコア (_) のみを含めることができます。
Default
指定された JSON 解析パスが解析できない場合や、対応するフィールドが存在しない場合のデフォルトの動作を指定します。
無視:動的解決は実行されません。ダーティデータ:このデータは同期タスクのダーティデータ統計にカウントされ、ダーティデータ許容設定によってタスクが異常終了するかどうかが決まります。
フィールド名が既存のフィールドと競合する場合のポリシー。
動的 JSON フィールドがキーと値のペアで展開される場合、最初のレベルのみが展開されます。後続で展開されたフィールドが既存のフィールドと同じ名前を持つ場合、ポリシーを選択する必要があります。利用可能なポリシーは次のとおりです:
Overwrite:既存のフィールドの値を新しいフィールドの値で置き換えます。
Discard:既存のフィールドの値を保持し、新しいフィールドの値を破棄します。
Error:タスクはエラーを報告して停止します。
次のステップ
Data Source と JSON Parsing の設定が完了したら、Output Preview をクリックして現在のノードの出力データを表示し、要件を満たしていることを確認します。