データ同期の際、生データにはフォーマットの不整合、冗長な情報、あるいは非構造化データが含まれていることがあります。DataWorks のオフライン同期タスクに組み込まれたデータ処理機能を使用すると、データ同期パイプライン内で直接データのクレンジング、AI 支援による処理、ベクトル化を行うことができます。これにより、抽出・変換・書き出し (ETL) アーキテクチャが簡素化されます。
制限事項
この機能は、新バージョンのデータ開発が有効になっているワークスペースでのみ利用可能です。
Serverless リソースグループのみがサポートされています。
現在、この機能は単一の非パーティションテーブルをオフラインで同期する一部のチャネルでのみ利用可能です。
データ処理を有効にすると、追加の計算ユニット (CU) が消費されます。リソースクォータを監視してください。
設定のエントリポイント
新規または既存のオフライン同期タスクの設定ページで、データ処理セクションまで下にスクロールします。
デフォルトでは、この機能は無効になっています。トグルをクリックして、データ処理モジュールを有効にし、設定を行います。
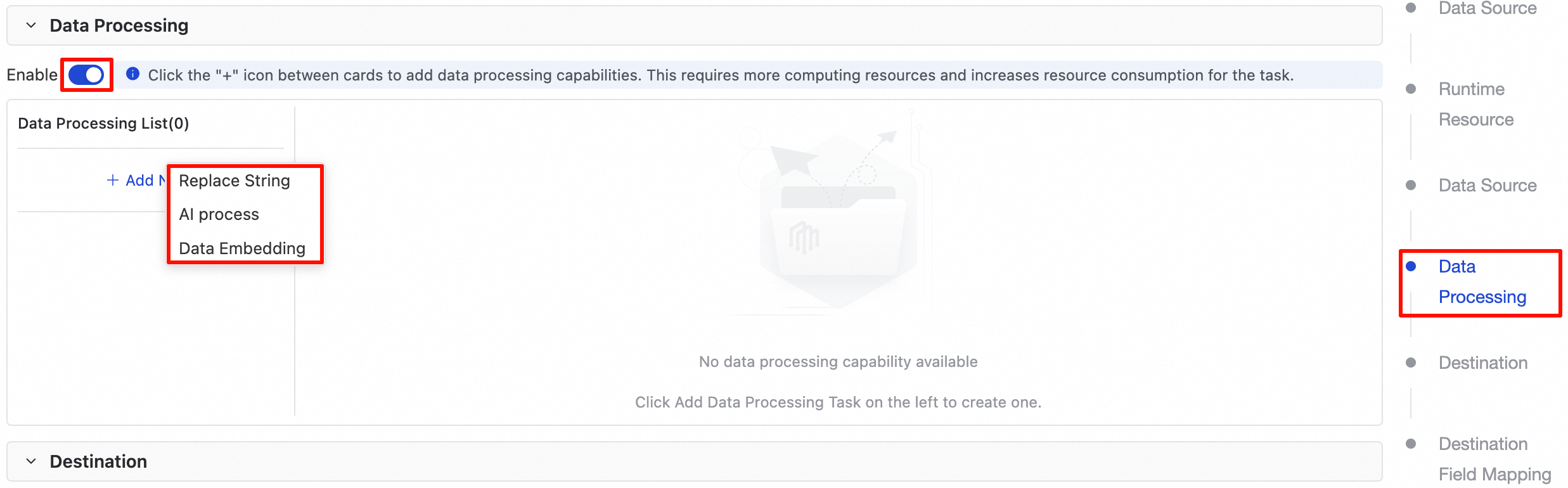
機能
データ処理モジュールを有効にすると、必要に応じて以下の処理ルールを 1 つ以上追加できます。
1. 文字列置換
文字列置換は、基本的で一般的なデータクレンジング機能です。現在のタスク内の異なるフィールドに対して、複数の置換ルールを設定できます。
コードレス UI 設定
データ処理リストで、+ ノードを追加 ボタンをクリックし、文字列置換 を選択して新しい置換ルールを追加します。設定項目は以下の通りです:
設定項目 | 説明 |
名前 | 識別しやすいように、置換ルールのカスタム名を入力します。 |
説明 | (任意) ルールの目的について詳細な説明を記述します。 |
フィールド名 | + ルールを追加 ボタンをクリックしてフィールドルールを追加します。ソーステーブルのフィールドドロップダウンリストから、このルールを適用するフィールドを選択します。 |
置換対象のコンテンツ | 検索して置換する元の文字列を入力します。 |
置換後の文字列 | 新しい文字列を入力します。 |
| 正規表現を有効にするためのトグルです。これにより、正規表現を使用して置換対象の元の文字列を検索できます。 |
| 置換対象のコンテンツの検索で大文字と小文字を区別するかどうかを制御するトグルです。デフォルトでは、大文字と小文字は区別されません。 |
複数のルールを追加して、異なるフィールドの異なるコンテンツを詳細に置き換えることができます。たとえば、gender フィールドで 'male' を '1' に置き換えるルールや、status フィールドで 'active' を 'valid' に置き換える別のルールを作成できます。
データ出力プレビュー
ルールを設定した後、データ処理セクションの右上隅にある [データ出力プレビュー] をクリックします。
表示されるダイアログボックスで、[入力データ] を設定します。2 つのメソッドがサポートされています:
自動:システムはデフォルトで先祖ノードの出力からデータをフェッチします。[上流の出力を再取得] をクリックしてデータをリフレッシュできます。
手動:[+ 手動でデータを構築] をクリックして、データ行の各フィールドにカスタム値を入力したり、
NULLや空文字列などの特定の境界条件をテストしたりします。
[プレビュー結果] エリアで [プレビュー] ボタンをクリックします。
システムは設定されたすべての処理ルールを実行し、その結果を以下に表示します。結果を期待値と比較して、ルールが正しく設定されていることを確認します。
プレビュー結果はテストおよび参照用です。最終的な実行結果は、実際のタスクのランタイムに依存します。
コードエディタ設定
コードエディタでデータ処理を構成するには、"category": "map" および "stepType": "stringreplace" を含む JSON オブジェクトを JSON スクリプトの `steps` モジュールに追加します。コードエディタでの一般的な構成プロセスの詳細については、「コードエディタの構成」をご参照ください。
{
"category": "map",
"stepType": "stringreplace",
"parameter": {
"condition": [
{
"name": "<field_to_process>",
"replaceString": "<string_to_replace>",
"replaceByString": "<replacement_string>",
"useRegex": false,
"caseSensitive": false
}
]
},
"displayName": "<rule_name>",
"description": "<rule_description>"
}2. AI 支援処理
この機能は、組み込みの大規模言語モデル (LLM) を呼び出して、指定されたフィールドのコンテンツをインテリジェントに処理し、データにさらなるビジネス価値を付加します。
主な利用シーン:
コンテンツ要約:製品レビューやニュース記事などの大量のテキストブロックから主要な要約を抽出します。
情報抽出:非構造化テキストから名前、住所、連絡先などの重要な情報を抽出します。
テキスト翻訳:フィールドのコンテンツを指定された言語に翻訳します。
感情分析:テキストの感情 (肯定的、否定的、中立など) を判断します。
設定と使用方法:
ノードを追加 する際に、AI 支援処理を選択します。この機能の設定メソッドと典型的な利用シーンの詳細については、「AI 支援処理」をご参照ください。
3. データベクトル化
データベクトル化とは、埋め込みモデルを使用してテキストやその他のデータ型を高次元の数学的ベクトルに変換するプロセスです。これらのベクトルはデータのセマンティック情報を捉えます。これらは、検索拡張生成 (RAG)、セマンティック検索、推奨システムなどの AI アプリケーションを構築する上で重要なステップです。
主な利用シーン:
ナレッジベースの構築:ドキュメント、チケット、製品マニュアルのテキストデータをベクトル化し、ベクトルデータベースに保存して、LLM の外部ナレッジベースとして機能させます。
パーソナライズされた推奨:ユーザーとアイテムのベクトル表現に基づいて類似度を計算し、正確な推奨を提供します。
設定と使用方法:
ノードを追加 をクリックする際に、データベクトル化 を選択します。次に、処理するフィールドと使用する埋め込みモデルを選択します。詳細な設定命令と例については、「ベクトル化処理」をご参照ください。