DataWorks DataStudio では、オンプレミスの CSV ファイルまたはカスタムテキストファイルのデータを MaxCompute テーブルにインポートできます。このトピックでは、MaxCompute テーブルにデータをインポートする方法について説明します。
前提条件
開発環境に MaxCompute テーブルが作成されていること。詳細については、「MaxCompute テーブルの作成と管理」をご参照ください。
制限事項
DataStudio では、オンプレミスの CSV ファイルまたはテキストファイルのデータのみを MaxCompute テーブルにインポートできます。 DataStudio では、SQL ファイルのデータを MaxCompute テーブルにインポートすることはできません。
より多くのデータアップロード関連機能を使用する場合は、DataWorks のアップロードおよびダウンロードサービスを使用できます。アップロードおよびダウンロードサービスで提供されるデータアップロード機能を使用すると、オンプレミスファイル、DataAnalysis ワークブック、および Object Storage Service (OSS) オブジェクトを MaxCompute、E-MapReduce (EMR) Hive、および Hologres にアップロードできます。詳細については、「データのアップロード」をご参照ください。
データインポートのエントリポイント
MaxCompute テーブルへのデータは、[スケジュールワークフロー] ペインの上部ツールバー、[スケジュールワークフロー] ペインのビジネスフローセクションの MaxCompute フォルダ、および [ワークスペーステーブル] ペインからインポートできます。次の図は、データインポートのエントリポイントを示しています。
[スケジュールワークフロー] ペインの上部ツールバーにある [データのインポート] アイコンをクリックします。

[スケジュールワークフロー] ペインで目的のワークフローを見つけ、MaxCompute フォルダ内のデータをインポートするテーブルの名前を右クリックし、[データのインポート] を選択します。
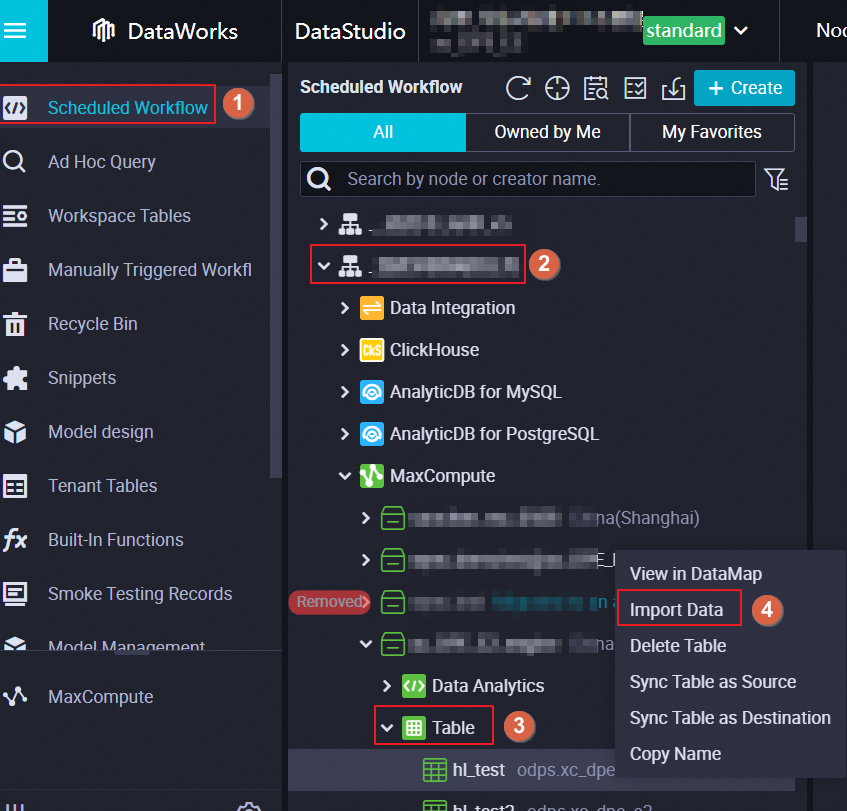
標準モードのワークスペースで、DataStudio ページの左側のナビゲーションペインにある [ワークスペーステーブル] をクリックし、データをインポートするテーブルの名前を右クリックして、[データのインポート] を選択します。

データのインポート
DataStudio では、オンプレミスの CSV ファイルまたはテキストファイルのデータのみを MaxCompute テーブルにインポートできます。 DataStudio では、SQL ファイルのデータを MaxCompute テーブルにインポートすることはできません。
上記のいずれかの方法を使用して、[データインポートウィザード] ダイアログボックスを開きます。
[データインポートウィザード] ダイアログボックスで、データをインポートするテーブルの名前を入力または確認し、テーブル情報を確認して、[次へ] をクリックします。
パーティションテーブルを選択した場合は、データをインポートするパーティションを指定できます。次に、[確認] をクリックして、パーティションが存在するかどうかを確認します。
指定したパーティションが存在しない場合、システムは後続の操作のためにパーティションを作成し、データは作成されたパーティションにインポートされます。
指定したパーティションが存在する場合、データはこのパーティションにインポートされます。

ファイル形式を指定し、データをインポートするファイルを選択します。
ファイルをアップロードし、[区切り文字の選択] や [元の文字セット] などのパラメータを設定します。次に、[次へ] をクリックします。
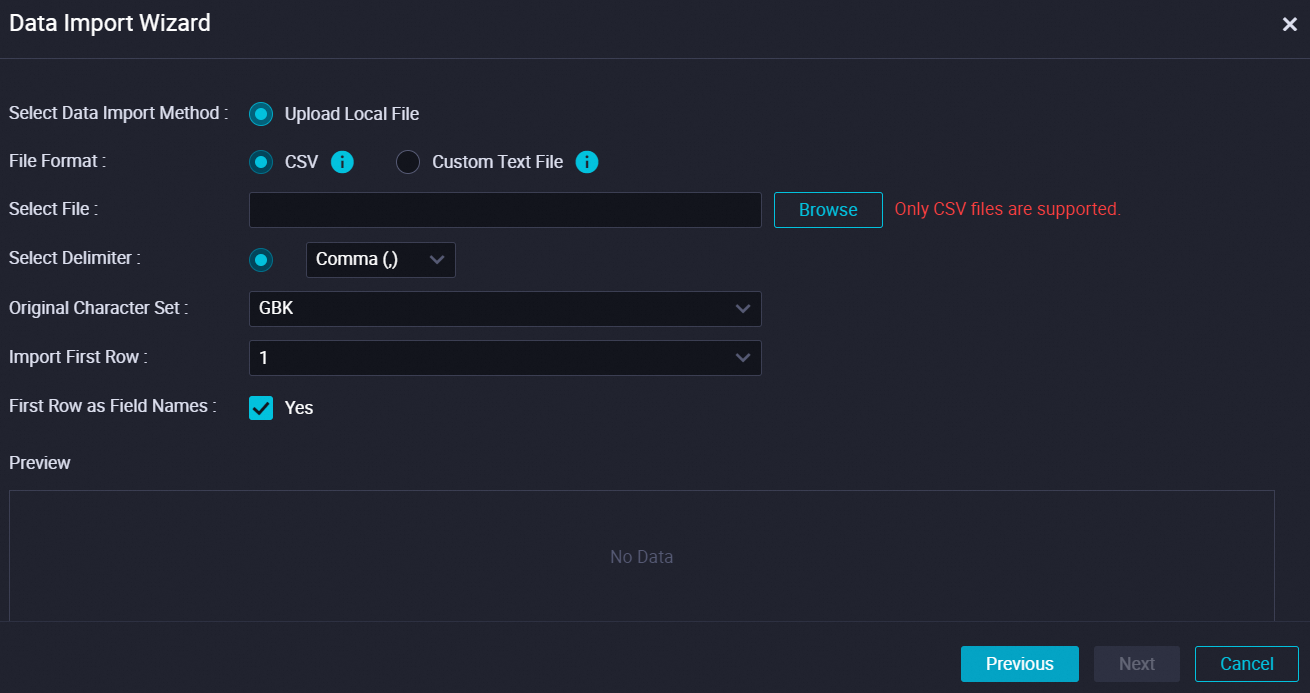
次の表にパラメータを示します。
パラメータ
説明
ファイル形式
アップロードするファイルの形式。有効な値: [CSV] および [カスタムテキストファイル]。このパラメーターをカスタムテキストファイルに設定すると、
.txt、.csv、および.logファイルをアップロードできます。ファイルの選択
アップロードするファイル。[参照] をクリックし、プロンプトに従ってファイルを選択できます。
区切り文字の選択
フィールドを区切るために使用する区切り文字。有効な値:
カンマ (,)、タブ、セミコロン (;)、スペース、|、#、および&。説明ファイル形式 パラメータを カスタムテキストファイル に設定した場合、[区切り文字の選択] フィールドに文字または文字列を入力して、フィールドを区切る区切り文字として使用できます。
元の文字セット
アップロードするファイルのエンコード形式。有効な値:GBK、UTF-8、CP936、および ISO-8859-1。
最初の行をインポート
データのインポートを開始する行。
最初の行をフィールド名として使用
アップロードするファイルの最初の行をヘッダー行として設定するかどうかを指定します。
はい を選択すると、ファイルの最初の行はインポートされません。
それ以外の場合、ファイルの最初の行がインポートされます。
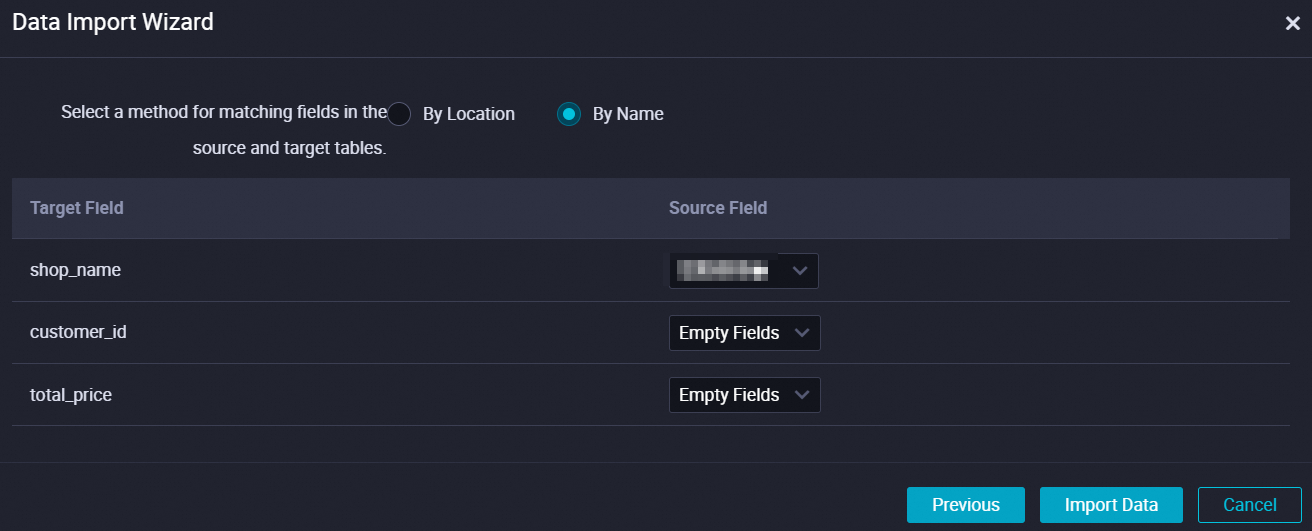
アップロードされたファイルと MaxCompute テーブルの間でフィールドを一致させるために使用される方法を指定します。次に、[データのインポート] をクリックします。
アップロードされたファイルと MaxCompute テーブルの間でフィールドを一致させるには、[場所別] または [名前別] を選択できます。
操作が完了すると、オンプレミスファイルのデータが MaxCompute テーブルにインポートされたことを示すメッセージが表示されます。インポートされたデータは、アドホッククエリを実行することで表示できます。詳細については、「アドホッククエリの作成」をご参照ください。
参照
より多くのデータアップロード関連機能を使用する場合は、DataWorks のアップロードおよびダウンロードサービスを使用できます。アップロードおよびダウンロードサービスで提供されるデータアップロード機能を使用すると、オンプレミスファイル、DataAnalysis ワークブック、および Object Storage Service (OSS) オブジェクトを MaxCompute、E-MapReduce (EMR) Hive、および Hologres にアップロードできます。詳細については、「データのアップロード」をご参照ください。