オペレーションセンターでは、本番環境に公開されたタスクを表示し、テストやデータバックフィルなどの関連する運用保守 (O&M) を実行できます。このトピックでは、自動トリガーノードを例に、オペレーションセンターでの基本操作を説明します。タスク構成の確認、履歴期間のデータバックフィル、およびタスクが正しくスケジューリングされることを保証するためのインテリジェントモニタリングルールの構成方法を学びます。
前提条件
result_table という名前の自動トリガーノードが作成され、公開されていること。詳細については、「DataStudio」をご参照ください。
このトピックでは、result_table ノードを使用して O&M 操作を説明します。必要に応じて、ご自身のタスクでこれらの操作を実行できます。
背景情報
DataWorks オペレーションセンターは、自動トリガーノード、ワンタイムタスク、リアルタイム同期タスクなど、さまざまなタスクタイプの運用管理をサポートします。また、タスクやタスクが使用するリソースなどのオブジェクトに対して、複数のモニタリングメソッドを提供します。これにより、アラートに基づいて例外を迅速に特定して処理し、効率的で安定したデータ生成を保証できます。
このトピックでは、オペレーションセンターでのタスク実行に関する 基本的なワークフロー のみを説明します。必要に応じて、次のようなより高度な O&M 操作を実行できます。
タスクの公開、非公開、または凍結。詳細については、「自動トリガーノードの基本的な O&M 操作」をご参照ください。
タスクに対する O&M 操作の管理と制御。詳細については、「O&M 操作の管理と制御 (高度)」をご参照ください。
オペレーションセンターの詳細については、「オペレーションセンターの概要」をご参照ください。
オペレーションセンターへ移動
オペレーションセンターコンソールにログオンします。ターゲットリージョンに切り替え、ドロップダウンリストからワークスペースを選択し、[オペレーションセンターに入る] をクリックします。
手順
フェーズ 1: スケジューリングタスクのテストと検証
自動トリガーノードが予期せずスケジューリングされるのを防ぐには、公開後にその構成を確認する必要があります。スケジューリングパラメーターや専用スケジューリングリソースグループなどのパラメーターが正しいことを確認してください。正しくない場合は、構成を変更してタスクを再度公開します。
スモークテスト機能を使用して、自動トリガーノードが本番環境で正しく実行されることを確認します。エラーが発生した場合は、タスクが期待どおりに実行されるように、迅速に修正する必要があります。
ステップ 3: 自動トリガーノードの履歴データをバックフィルする
データバックフィル機能を使用して、履歴期間のデータを再計算します。
自動トリガーノードが公開されると、そのスケジュールに基づいて定期インスタンスが生成されます。DataStudio で [インスタンス生成モード] が [翌日 (T+1) に生成] に設定されている場合、タスクは翌日にスケジューリングを開始します。[公開後すぐに生成] に設定されている場合、タスクは同日にスケジューリングされます。インスタンスの生成および実行ステータスを表示して、タスクが期待どおりにスケジューリングされているかどうかを確認できます。
ノードをテストするか、データをバックフィルした後、データ書き込み操作のステータスを確認できます。
フェーズ 2: 自動トリガーノードのモニタリング
必要に応じて、自動トリガーノードにインテリジェントモニタリングルールを構成できます。これにより、タスクのスケジューリングおよび実行ステータスをモニタリングして、将来的に正しくスケジューリングされることを保証できます。
ステップ 7: インテリジェントベースラインを作成する (高度)
優先度の高いタスクが指定された時間までにデータを生成できるように、インテリジェントベースラインモニタリングを設定できます。システムがタスクが指定された時間までに完了できないと予測した場合、ベースラインはタスク例外に関するアラートを送信します。これにより、例外に関する情報を迅速に取得して処理できます。
ステップ 8: リソースグループの自動 O&M ルールを作成する
排他的リソースグループに対してカスタムモニタリングルールを作成できます。リソースグループの使用状況と待機中のインスタンス数に対してモニタリングアラートを設定し、関連する O&M 操作を実行できます。
ステップ 1: 自動トリガーノードの構成を表示する
自動トリガーノードが予期せずスケジューリングされるのを防ぐには、公開後にその構成を確認する必要があります。スケジューリングパラメーターやノードの依存関係などのパラメーターが正しいことを確認してください。
オペレーションセンターへ移動します。
ターゲットノードを見つけます。
左側のナビゲーションウィンドウで、 を選択します。
[自動トリガーノード] ページで、ターゲットノードを検索します。
ノード詳細を表示します。
ターゲットノードをクリックして、その有向非巡回グラフ (DAG) に移動します。
ノードの詳細情報を表示するには、[詳細を展開] をクリックします。
自動トリガーノードの操作の詳細については、「自動トリガーノードの管理」をご参照ください。
ノード構成が期待どおりでない場合は、DataStudio に移動してノードを見つけ、ノード編集ページで構成を変更して再度公開します。詳細については、「ノード関連の操作」をご参照ください。
この例では、自動トリガーノードリストで公開済みの result_table ノードを見つけ、その [スケジューリングパラメーター] と [スケジュールリソースグループ] が正しく構成されているかどうかを確認する方法を示します。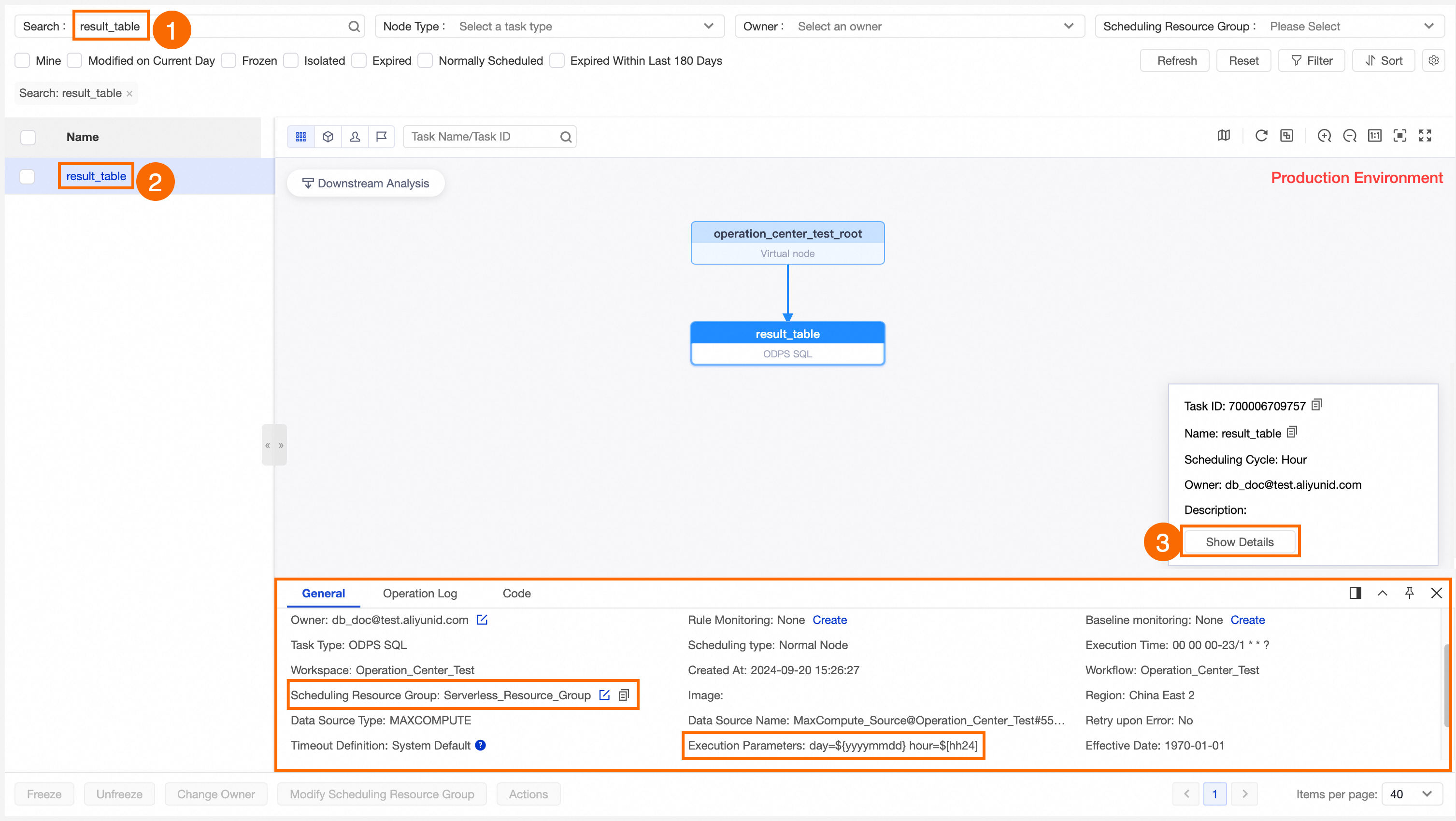
ステップ 2: 自動トリガーノードをテストする
自動トリガーノードのスモークテスト機能を使用して、本番環境でのスケジューリングと実行が期待どおりであることを確認できます。この操作は、実際のコードロジックを実行します。
スモークテストページに移動します。
次のいずれかの方法でスモークテストページに移動できます。
方法 1: 自動トリガーノードリストでターゲットタスクを見つけ、[操作] 列の [テスト] をクリックします。
方法 2: ターゲットタスクの DAG でタスクを右クリックし、[テスト] を選択します。
テストのデータタイムスタンプとランタイムを構成し、[OK] をクリックします。
タスクがテストされると、テストインスタンスが生成されます。 ページに移動して、インスタンスの詳細を表示し、実行ステータスを確認できます。
説明スモークテストの詳細については、「スモークテストの実行」をご参照ください。
テストインスタンスを表示するには、「テストを実行してテストインスタンスを表示する」をご参照ください。
この例では、result_table ノードをテストし、生成されたテストインスタンスの実行ステータスを表示する方法を示します。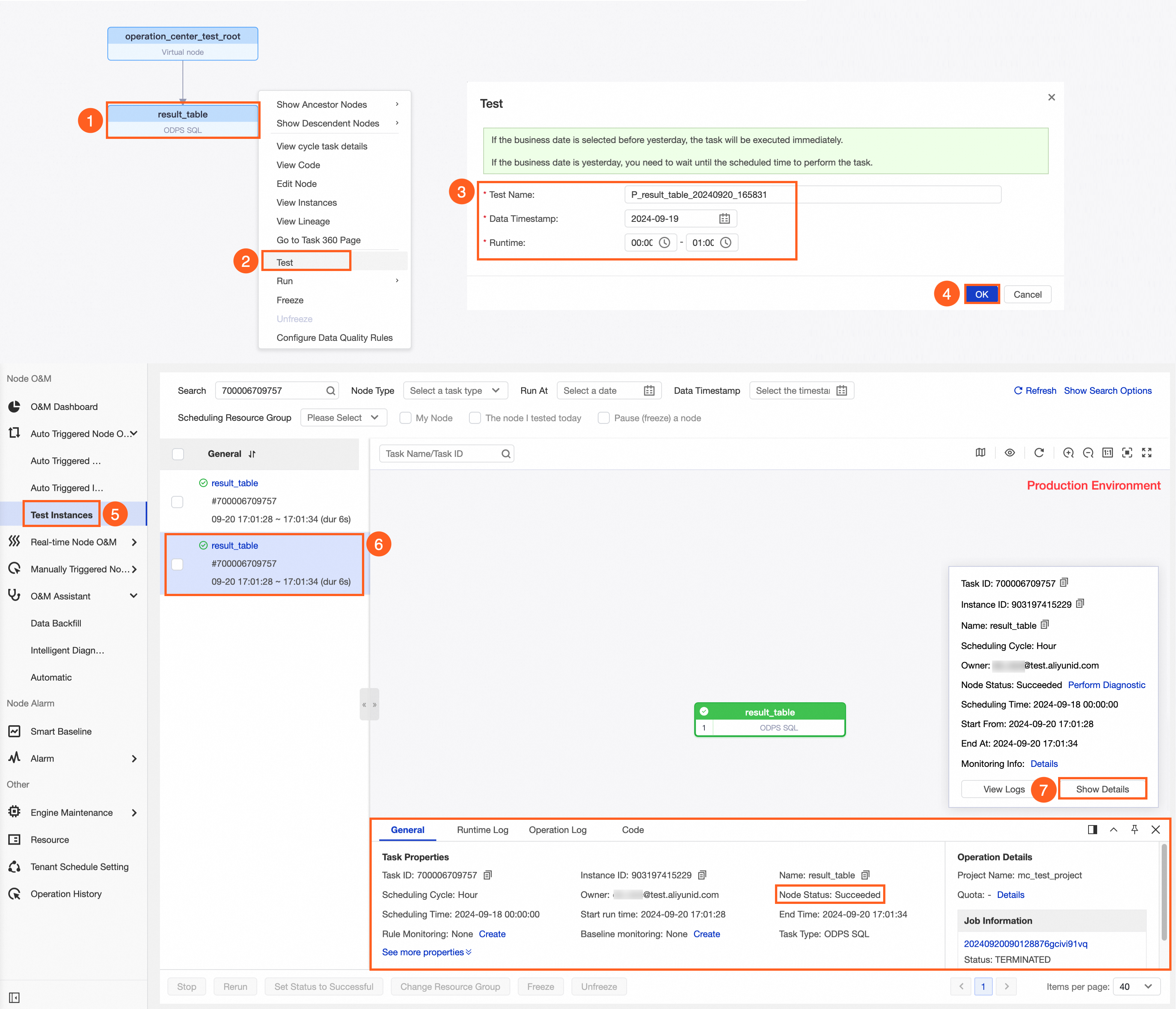
ステップ 3: 自動トリガーノードの履歴データをバックフィルする
自動トリガーノードが開発、送信、公開されると、スケジュールされた時刻に実行されます。履歴期間のデータを再計算する場合は、データバックフィル機能を使用できます。
データバックフィルページに移動します。
次のいずれかの方法でデータバックフィルページに移動できます。
方法 1: 自動トリガーノードリストでターゲットタスクを見つけ、[操作] 列の [データバックフィル] をクリックします。
方法 2: ターゲットタスクの DAG でタスクを右クリックし、[データバックフィル] を選択します。
データバックフィルモードを選択します。
必要に応じてデータバックフィルモードを選択します。
データバックフィルモード
説明
シナリオ
1 つ以上のタスクをルートタスクとして選択し、その子孫ノードを手動で選択してデータバックフィルの範囲とすることができます。子孫ノードのサブセットを指定することもできます。
説明このモードは、[現在のノード]、[現在のノードと子孫ノード]、[高度なモード] など、以前のデータバックフィルプランと互換性があります。
最大 500 のルートタスクと、ルートタスクとその子孫ノードを含む合計 2,000 のタスクがサポートされます。
このモードは、現在のノードとその子孫ノードのバッチデータバックフィルに使用されます。
このモードは、データバックフィル用のノードのバッチを柔軟に選択するために使用されます。ノードは依存関係を持つ必要はありません。
開始タスクをルートタスクとして、1 つ以上の終了タスクを選択できます。プラットフォームは、開始タスクと終了タスクの間のすべてのタスクを自動的に分析し、データバックフィルの範囲に含めます。
このモードは、複雑な依存関係を持つタスクのエンドツーエンドのデータバックフィルに使用されます。
タスクをルートタスクとして選択し、その子孫ノードのワークスペースに基づいてデータバックフィルの範囲を決定できます。
説明このモードは、以前の [大規模ノードモード] データバックフィルプランと互換性があります。最大
20,000タスクがサポートされます。タスクブラックリストを構成することはできません。
このモードは、現在のノードの子孫ノードが複数のワークスペースにあり、それらのワークスペースのノードのデータをバックフィルする必要がある場合に使用されます。
ルートタスクを選択すると、システムはタスクとそのすべての子孫ノードを自動的にデータバックフィルの範囲に含めます。
重要データバックフィルタスクの実行中にのみ、どのタスクがトリガーされるかを表示できます。このモードは注意して使用してください。
このモードは、ルートタスクとそのすべての子孫ノードのデータバックフィルに使用されます。
データバックフィルパラメーターを構成します。
必要に応じて、データタイムスタンプ、データをバックフィルするノード、およびその他のパラメーターを構成します。必要なパラメーターは、選択したモードによって異なります。詳細については、「データをバックフィルしてデータバックフィルインスタンスを表示する (新規)」をご参照ください。
この例では、データバックフィルモードとして [現在のノードのデータをバックフィル] が選択されています。00:00 から 01:00 までの毎日 2024-09-17 から 2024-09-19 までの期間に生成されたデータが、result_table ノードにバックフィルされます。次の図に示す操作を実行することで、ノードのデータをバックフィルできます。
データバックフィルを構成すると、ノードコード内の変数は、構成したスケジューリングパラメーターとデータタイムスタンプに基づいて特定の値に置き換えられます。

ステップ 4: 定期インスタンスを表示する
自動トリガーノードが公開されると、そのスケジュールに基づいて定期インスタンスが生成されます。DataStudio で [インスタンス生成モード] が [翌日 (T+1) に生成] に設定されている場合、タスクは翌日にスケジューリングを開始します。[公開後すぐに生成] に設定されている場合、タスクは同日にスケジューリングされます。生成された定期インスタンスを表示して、タスクが期待どおりにスケジューリングおよび実行されているかどうかを確認できます。
定期インスタンスページに移動します。
[オペレーションセンター] の左側のナビゲーションウィンドウで、 を選択します。
定期インスタンスを表示します。
タスクのスケジュール構成に基づいて、対応する定期インスタンスが生成され、期待どおりに実行されているかどうかを確認します。定期インスタンスの詳細については、「定期インスタンスの表示」をご参照ください。
インスタンスが実行されていない場合は、次の手順を実行します。
DAG パネルの [上流分析] 機能を使用して、現在のタスクをブロックしている主要な上流タスクを迅速に特定します。
[ランタイム診断] 機能を使用して、主要な上流タスクが実行されていない理由を診断したり、既存の問題を特定したりします。タスクの依存関係レイヤーが深い場合、ランタイム診断機能を使用して問題を迅速に特定し、O&M 効率を向上させることができます。

この例では、2024-09-19 に生成された時間単位でスケジューリングされたノード result_table の定期インスタンスを示します。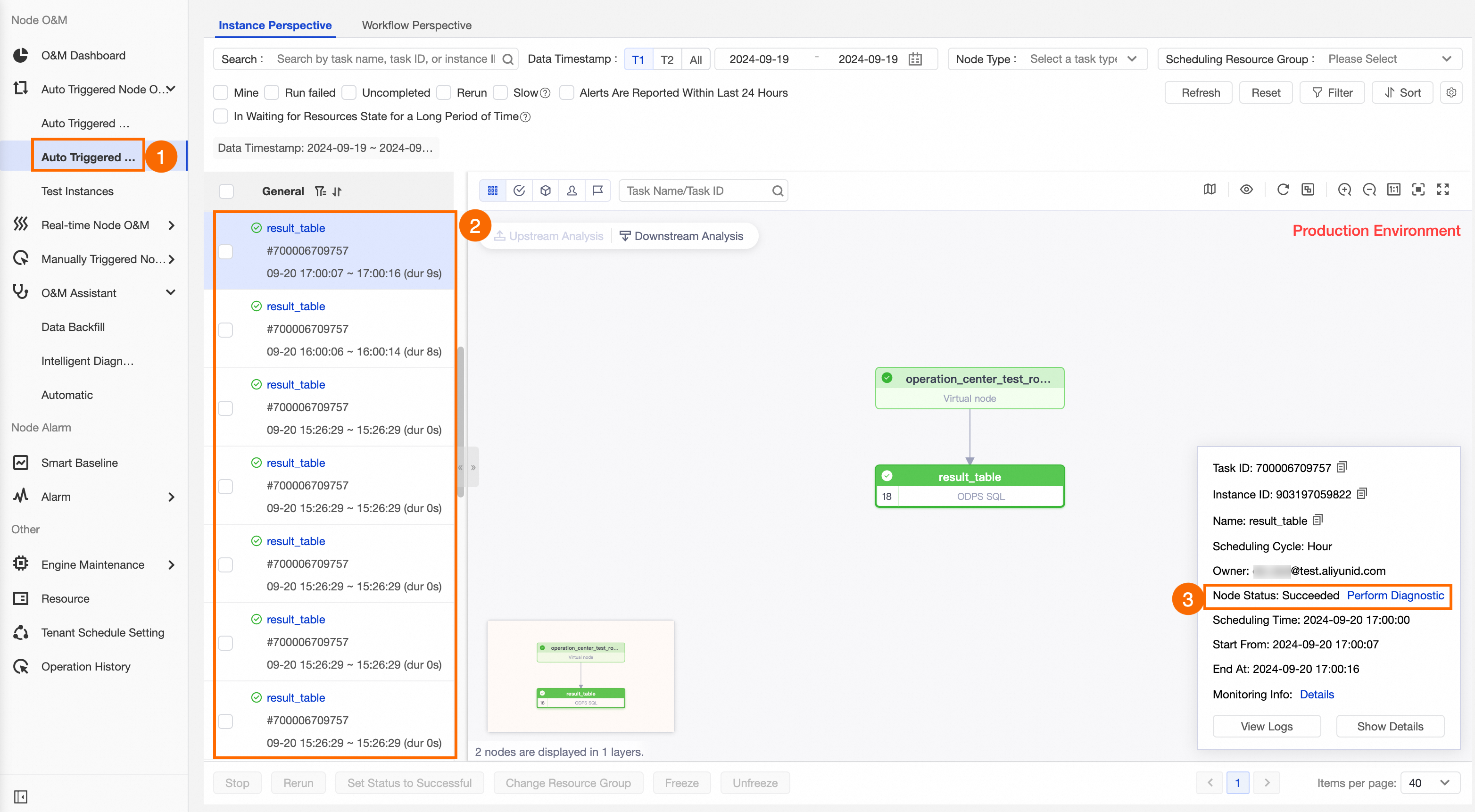
ステップ 5: 実行結果を表示する
自動トリガーノードをテストするか、データをバックフィルした後、次の方法でデータ書き込み操作のステータスを確認できます。
[データマップ] に移動して結果を表示します。
データマップでターゲットテーブルをクエリし、テーブルの詳細を表示して、データが正しく書き込まれていることを確認します。テーブルの検索と表示方法の詳細については、「テーブルの検索」および「テーブル詳細の表示」をご参照ください。
[アドホッククエリ] を使用して結果を表示します。
Data Studio でのみデータと関連する SQL コードをクエリして、実際のランタイム結果が期待と一致するかどうかを確認したり、コードを本番環境に公開せずにコードの正しさを検証したりするには、アドホッククエリファイルを作成できます。
デフォルトでは、Resource Access Management (RAM) ユーザーは MaxCompute DPI エンジンで本番テーブルをクエリする権限を持っていません。データマップに移動し、その製品ページでテーブルの権限をリクエストできます。詳細については、「テーブル権限のリクエスト」をご参照ください。
ノードが開発者環境で実行されると、データは開発者 DPI エンジンプロジェクトに書き込まれます。ノードが本番環境で実行されると、データは本番 DPI エンジンプロジェクトに書き込まれます。クエリを実行する前に、データが配置されている DPI エンジンプロジェクトを確認してください。[コンピューティングリソース] ページに移動して、対応する環境の DPI エンジンプロジェクト情報を表示できます。
MaxCompute は、他のデータソースで作成されたテーブルへのアクセスや、開発者プロジェクトから本番プロジェクトテーブルへのアクセスなど、クロスプロジェクトのテーブルアクセスをサポートしています。ただし、一部の DPI エンジンはこの機能をサポートしていません。DPI エンジンタイプがクロスプロジェクトのテーブルアクセスをサポートするかどうかは、その実際の機能によって異なります。
この例では、本番環境の result_table ノードの DPI エンジンプロジェクトは mc_test_project です。アドホッククエリを使用して ODPS SQL ノードを作成し、SQL 文を実行して mc_test_project.result_table テーブルのパーティションデータをクエリできます。
ステップ 6: カスタムモニタリングルールを作成する
ノードがテストおよび検証された後、ノードのカスタムモニタリングルールを作成して、その実行ステータスをモニタリングできます。ノードの実行に失敗した場合、DataWorks は構成に基づいてアラートを送信します。これにより、例外を迅速に特定して処理し、将来的にノードが期待どおりにスケジューリングされることを保証できます。
オペレーションセンターへ移動します。
左側のナビゲーションウィンドウで、 を選択します。
カスタムルールを作成します。
[カスタムルールを作成] をクリックします。
ルール情報を構成します。
必要に応じてルールをカスタマイズできます。構成の詳細については、「カスタムモニタリングルール」をご参照ください。
この例では、
result_tableノードが実行に失敗した場合のモニタリングアラートを構成する方法を示します。具体的な構成は次の図のとおりです。
result_tableノードの実行に失敗した場合、テストルールルールがトリガーされ、ノードのオーナーにショートメッセージでアラートが送信されます。アラートは 30 分間隔で最大 3 回送信されます。説明事前にアラート連絡先情報を構成する必要があります。詳細については、「アラート連絡先の表示と設定」をご参照ください。
ステップ 7: インテリジェントベースラインを作成する (高度)
タスクが指定された時間内にデータを生成できるように、タスクのベースラインモニタリングを設定できます。タスクをベースラインに追加し、その優先度とコミット時刻を設定できます。DataWorks は、実行履歴に基づいてベースラインタスクの推定完了時刻を計算し、優先度の高いタスクにスケジュールリソースへの優先アクセスを提供します。DataWorks がベースラインタスクがコミット時刻までに完了しない可能性があると予測した場合、アラートを送信します。アラートに基づいて例外を迅速に処理できます。
オペレーションセンターへ移動します。
左側のナビゲーションウィンドウで、[インテリジェントベースライン] をクリックします。
インテリジェントベースラインを作成します。
[ベースライン管理] タブで、[ベースラインを作成] をクリックします。
ベースライン情報を構成します。
必要に応じてベースライン情報を構成できます。構成の詳細については、「ベースラインの作成」をご参照ください。
この例では、
result_tableノードの時間単位のベースラインを構成して、その時間単位のデータ出力をモニタリングします。具体的な構成は次の図のとおりです。 次のリストは、一部のパラメーターについて説明しています。
次のリストは、一部のパラメーターについて説明しています。優先度: 値が大きいほど、優先度が高くなります。リソースが不足している場合、優先度の高いタスクにはスケジュールリソースへの優先アクセスが提供されます。
推定完了時刻: 推定完了時刻は、一定期間のノードの完了履歴に基づいて計算されます。
コミット時刻: ノードがデータを生成しなければならない最新の時刻。ビジネスニーズとノードの実際の完了履歴に基づいて設定できます。
アラートマージン: [コミット時刻] に基づいてアラートマージンを設定し、タスク例外を処理するための時間を確保できます。これにより、タスクがコミット時刻までに完了することを保証できます。
説明アラートマージンとコミット時刻の間隔は、少なくとも 5 分である必要があります。
result_tableノードの時間単位のインスタンスが各時間の 30 分以内に完了できない場合、テストベースラインベースラインがトリガーされます。ノードのオーナーにショートメッセージでアラートが送信されます。アラートは 30 分間隔で最大 3 回送信されます。
ステップ 8: リソースグループの自動 O&M ルールを作成する
タスクの実行に排他的リソースグループを使用する場合、必要に応じて排他的リソースグループの自動 O&M ルールを作成できます。これにより、リソースグループの使用状況と待機中のインスタンス数に対してモニタリングアラートを設定し、関連する O&M 操作を実行できます。
自動 O&M 機能は、モニタリングルールを排他的リソースグループに関連付けることで機能します。ターゲットリソースグループで実行されるインスタンスのモニタリングメトリックをカスタマイズし、ビジネスロジックに基づいて O&M ルールを定義できます。インスタンスがフィルター条件を満たす場合、O&M 操作が自動的にトリガーされて実行され、自動 O&M が実現されます。
現在、自動 O&M は専用スケジューリングリソースグループでのみサポートされています。
リソース不足によるタスク実行の遅延を防ぐために、タスクを専用スケジューリングリソースグループに移動できます。タスクが使用するリソースグループを変更する方法の詳細については、「一般的なリファレンス: リソースグループの切り替え」をご参照ください。
オペレーションセンターへ移動します。
リソースグループのモニタリングルールを作成します。
左側のナビゲーションウィンドウで、 を選択します。
リソースグループのモニタリングルールを作成して構成します。
リソースグループのモニタリングルールの構成は、ノードのモニタリングルールの構成と似ています。[オブジェクトタイプ] を [専用スケジューリングリソースグループ] に設定するだけで済みます。構成の詳細については、「カスタムモニタリングルール」をご参照ください。
この例では、
Exclusive_Scheduling_Resourceリソースグループのリソースグループ使用率をモニタリングします。構成は次の図のとおりです。説明このトピックでは、構成操作のみを説明します。ルールを構成する際は、使用するリソースグループに対して構成するようにしてください。

Exclusive_Scheduling_Resourceリソースグループのリソースグループ使用率が 10 分間 90% を超えた場合、リソースグループモニタリングルールルールがトリガーされます。受信者にショートメッセージでアラートが送信されます。このアラートは最大 3 回送信されます。
リソースグループモニタリングルールに基づいて自動 O&M ルールを構成します。
左側のナビゲーションウィンドウで、 を選択します。
[ルール管理] タブで、[ルールを追加] をクリックします。
ルール情報を構成します。
必要に応じてルール情報を構成できます。構成の詳細については、「リソースグループの自動 O&M ルールを作成する」をご参照ください。
この例では、
Automatic_testという名前のリソースグループを作成し、それを専用スケジューリングリソースグループを使用するモニタリングルールであるリソースグループモニタリングルールに関連付けます。リソースグループモニタリングルールルールがトリガーされると、DataWorks はフィルター条件を満たすAutomatic_test内のインスタンスに対して自動的に O&M 操作を実行します。次の図に構成を示します。 次のセクションでは、一部のパラメーターについて説明します。
次のセクションでは、一部のパラメーターについて説明します。関連付けられたモニタリングルール: 現在、ルールは専用スケジューリングリソースのモニタリングルールにのみ関連付けることができます。事前に必要なリソースグループモニタリングルールを作成する必要があります。
O&M 操作: 現在、[実行中のインスタンスを停止] のみを選択できます。これは、O&M ルールがトリガーされた後、条件を満たすインスタンスが停止されることを意味します。
Exclusive_Scheduling_Resource専用スケジューリングリソースグループの使用率が 10 分間 90% を超えた場合、DataWorks は、指定されたワークスペースのExclusive_Scheduling_Resourceリソースグループで実行されている定期インスタンス、テストインスタンス、およびデータバックフィルインスタンスに属する優先度 1 の時間単位および分単位のタスクを停止します。
O&M 操作の管理と制御 (高度)
オペレーションセンターは、ノードの凍結、ノードの復元、データバックフィル、ノードの非公開などの拡張ポイントをサポートしています。これらの拡張ポイントを拡張プログラムと組み合わせて使用して、タスクのロジック処理と O&M 操作をカスタマイズできます。詳細については、「拡張機能の概要」および「アプリケーション例: オペレーションセンターでトリガーイベントを確認する」をご参照ください。
次のステップ
ノードによって生成されたテーブルデータに対して Data Quality モニタリングルールを構成して、データ出力が期待どおりであることを保証できます。詳細については、「Data Quality」をご参照ください。