Data Integration を使用すると、ApsaraDB for OceanBase、MySQL、Oracle、PolarDB などのソースから MaxCompute へ、データベース全体の完全および増分同期を実行できます。このプロセスは、初回の完全なデータ移行と、継続的な増分データのリアルタイム同期を組み合わせたものです。増分データは、翌日 (T+1) に送信先にマージされます。このトピックでは、MySQL から MaxCompute への同期を例に、完全および増分同期タスクの作成方法を説明します。
仕組み
完全および増分同期タスクは、統一されたプロセスを使用して、初回の既存データの完全ロードと、その後の増分データの継続的な同期を実行します。タスクが開始されると、システムは自動的にオフラインおよびリアルタイムのサブタスクを作成・調整し、データを送信先のテーブル (ベーステーブル) にマージします。
主要なプロセスは、次の 3 つのフェーズで構成されます。
初回の完全ロード:タスクが開始されると、まずバッチ同期タスクが実行されます。このタスクは、ソースデータベース内のすべてのテーブルのテーブル構造と既存データを、MaxCompute の送信先ベーステーブルに移行します。初回の完全ロードが完了すると、このバッチ同期タスクは一時停止します。
増分データの同期:完全移行後、システムはリアルタイム同期タスクを開始します。このタスクは、ソースデータベース (例えば MySQL のバイナリログ (binlog)) からの増分データ変更 (Insert、Update、Delete 操作) を継続的にキャプチャします。その後、これらの変更をほぼリアルタイムで MaxCompute の一時的なログテーブルに書き込みます。
定期的なマージ:システムは毎日 (T+1) 自動的にマージタスクを実行します。このタスクは、前日 (T) にログテーブルに蓄積された増分データを、ベーステーブルの完全データとマージします。このプロセスにより、T 日のデータの最新の完全スナップショットが生成され、ベーステーブルの新しいパーティションに書き込まれます。マージタスクは 1 日に 1 回実行されます。
次の図は、パーティションテーブルへの書き込み時のデータフローを示しています。

このタスクには、次の特徴があります。
多対多または多対一のテーブルマッピング:複数のソーステーブルを、対応する複数の送信先テーブルに同期できます。また、マッピングルールを使用して、複数のソーステーブルから単一の送信先テーブルにデータをマージすることもできます。
タスクの構成:完全および増分同期タスクは、初回の完全ロード用のバッチ同期サブタスク、増分データ用のリアルタイム同期サブタスク、およびデータ統合用のマージタスクで構成されます。
送信先テーブルのサポート:MaxCompute のパーティションテーブルと非パーティション化テーブルの両方にデータを書き込むことができます。
制限事項
リソース要件:このタスクには Serverless リソースグループ が必要です。インスタンスベースの同期の場合、最小リソース仕様は、Data Integration 専用リソースグループが 8 コア 16 GB、Serverless リソースグループが 2 CU です。
ネットワーク接続:Data Integration リソースグループと、ソース (例:MySQL) および送信先 (例:MaxCompute) の両方のデータソースとの間にネットワーク接続が確保されていることを確認してください。詳細については、「ネットワーク接続ソリューション」をご参照ください。
リージョンの制限:同期は、現在の DataWorks ワークスペースと同じリージョンにある、ユーザーが作成した MaxCompute データソースに対してのみサポートされます。ユーザーが作成した MaxCompute データソースを使用する場合でも、DataWorks ワークスペースのデータ開発セクションで MaxCompute 計算リソースをバインドする必要があります。そうしないと、MaxCompute SQL ノードを作成できず、完全同期の 'done' ノードの作成も失敗します。
スケジューリングリソースグループの制限:タスクは、設定された Serverless リソースグループ をスケジューリングリソースグループとして使用します。
送信先テーブルタイプの制限:MaxCompute 外部テーブルにデータを同期することはできません。
注意事項
プライマリキーの要件:プライマリキーのないテーブルは同期できません。プライマリキーがないテーブルについては、設定時に Specify Primary Key オプションを使用して、1 つ以上の列をビジネスプライマリキーとして手動で指定する必要があります。
データ可視性の遅延:MaxCompute への完全および増分同期タスクを設定した後、同日にクエリできるのは既存データのみです。増分データは、翌日にマージタスクが完了した後にのみ MaxCompute でクエリ可能になります。詳細については、「仕組み」セクションの定期的なマージの説明をご参照ください。
ストレージとライフサイクル:完全および増分同期タスクは、毎日新しい完全パーティションを作成します。過剰なストレージ使用量を防ぐため、同期タスクが自動的に作成する MaxCompute テーブルのデフォルトのライフサイクルは 30 日です。この期間がビジネス要件を満たさない場合は、タスク設定時に対応する MaxCompute テーブル名をクリックしてライフサイクルを変更できます。詳細については、「送信先テーブル構造の編集 (オプション)」をご参照ください。
SLA:Data Integration は、データのアップロードとダウンロードに MaxCompute データチャネルを使用します。同期データチャネルのサービスレベルアグリーメント (SLA) の詳細については、「データ転送サービス (アップロード) のシナリオとツール」をご参照ください。MaxCompute データチャネルの SLA に基づいて、技術的な選択を評価してください。
binlog 保持ポリシー:リアルタイム同期は、ソース MySQL データベースのバイナリログ (binlog) に依存します。同期の失敗を防ぐために、binlog の保持期間が十分であることを確認してください。タスクが長時間一時停止されたり、失敗後に再試行されたりすると、必要な binlog が消去されている場合に開始位置を見つけられずに失敗することがあります。
課金
完全および増分同期タスクには、完全ロードフェーズのバッチ同期タスク、増分フェーズのリアルタイム同期タスク、および定期マージフェーズの定期タスクが含まれます。これら 3 つのタスクは個別に課金されます。3 つのフェーズすべてで、リソースグループの CU が消費されます。課金の詳細については、「Serverless リソースグループの課金」をご参照ください。定期タスクには、スケジューリング料金も発生します。詳細については、「スケジューリングインスタンス料金」をご参照ください。
さらに、MaxCompute への同期プロセスでは、完全データと増分データの定期的なマージが必要であり、これにより MaxCompute 計算リソースが消費されます。これらの料金は MaxCompute によって直接請求され、完全データセットのサイズとマージ頻度に比例します。詳細については、「課金項目と料金」をご参照ください。
操作手順
ステップ 1: 同期タスクの種類の選択
Data Integration ページに移動します。
DataWorks コンソールにログインします。上部のナビゲーションバーで、目的のリージョンを選択します。左側のナビゲーションウィンドウで、 を選択します。表示されたページで、ドロップダウンリストから目的のワークスペースを選択し、[データ統合へ] をクリックします。
左側のナビゲーションウィンドウで、Synchronization Task をクリックします。ページの上部で Create Synchronization Task をクリックし、次のパラメーターを設定します。
Source Type:
MySQL。Destination Type:
MaxCompute。Specific Type:
データベース全体の完全および増分。Sync Procedure:Schema Migration、Incremental Sync、Full Synchronization、定期的マージ。
ステップ 2: データソースとリソースグループの設定
Source Information で
MySQLデータソースを選択します。Destination でMaxComputeデータソースを選択します。Running Resources セクションで、同期タスクの Resource Group を選択し、CU の Resource Group を割り当てます。完全同期と増分同期に別々の CU を設定することで、リソースを正確に制御し、無駄を防ぐことができます。
説明DataWorks は、スケジューリングリソースグループを介して、バッチ同期タスクを Data Integration 実行リソースグループに送信します。その結果、オフラインタスクは実行リソースグループとスケジューリングリソースグループの両方のリソースを消費し、後者にはスケジューリング料金が発生します。
ソースと送信先の両方のデータソースが 接続チェック に合格することを確認します。
ステップ 3: ソーステーブルの選択
[ソーステーブル] エリアで、ソースデータソースから同期するテーブルを選択します。![]() アイコンをクリックして、テーブルを [選択したテーブル] リストに移動します。
アイコンをクリックして、テーブルを [選択したテーブル] リストに移動します。
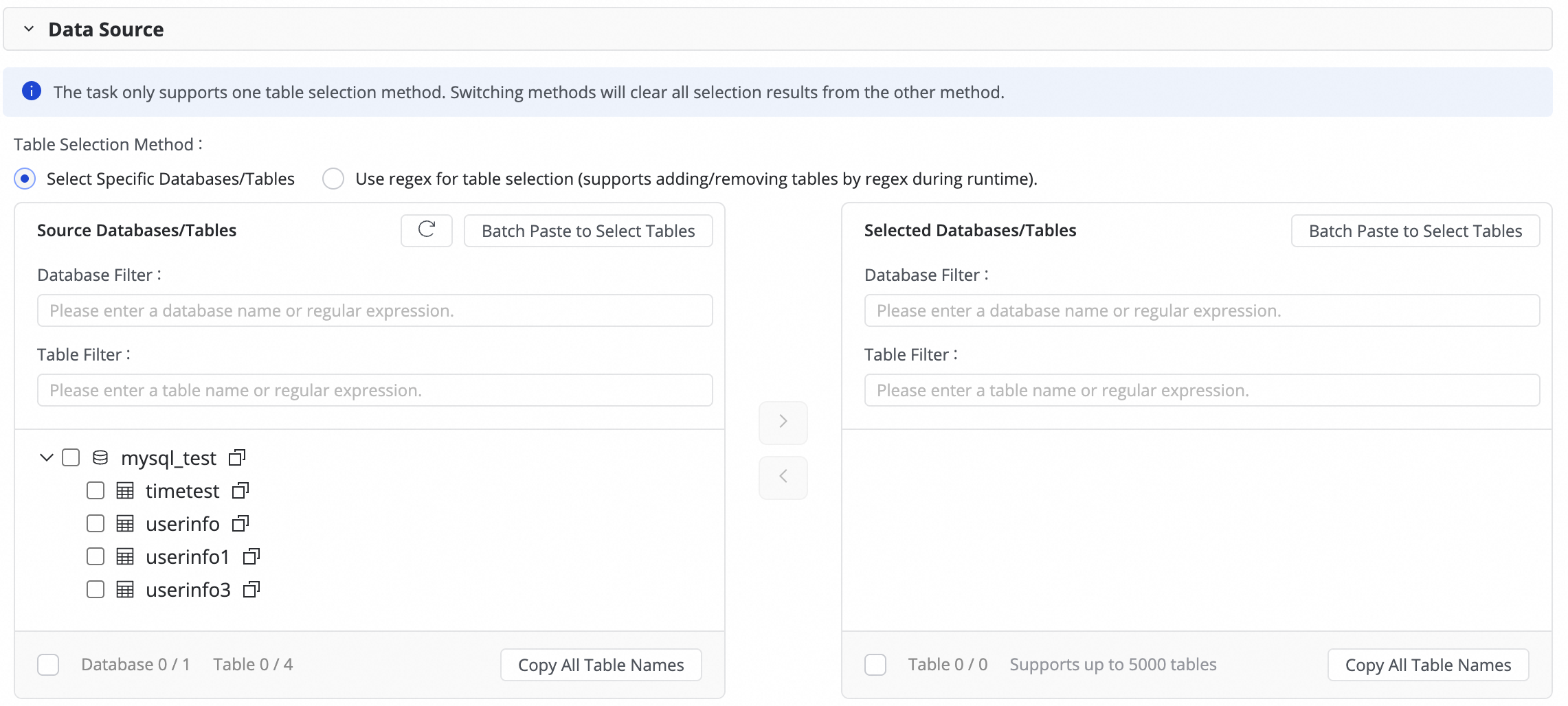
テーブルの数が多い場合は、Database Filtering、Search for Tables を使用するか、正規表現を設定して必要なテーブルを選択できます。
ステップ 4: タスク設定の構成
ログテーブルの時間範囲:このパラメーターは、送信先パーティションにマージするためにログテーブルからデータをクエリする時間範囲を定義します。
データ遅延による日をまたぐパーティションエラーを防ぐために、この範囲を少し広げてください。これにより、パーティションのすべてのデータが正しくマージされるようになります。
マージタスクのスケジューリング:毎日のマージタスクのスケジュールを設定します。スケジューリングの設定方法の詳細については、「スケジューリング設定」をご参照ください。
定期スケジューリングパラメーター:後でパーティションに値を割り当てるために使用できるスケジューリングパラメーターを設定します。これにより、日付に基づいてパーティションを自動的に作成できます。
テーブルパーティション設定:送信先テーブルのパーティションを設定します。パーティション列名や値の割り当て方法などの主要なパラメーターを設定できます。割り当て列には、スケジューリングパラメーターを使用して、日付に基づいてパーティションを自動的に生成できます。
ステップ 5: 送信先テーブルマッピングの設定
このステップでは、ソーステーブルと送信先テーブル間のマッピングルールを定義します。また、プライマリキー、動的パーティション、および DDL/DML 設定のルールを指定して、データの書き込み方法を決定します。
操作 | 説明 | ||||||||||||
Refresh | システムは選択したソーステーブルを自動的にリストアップします。ただし、送信先テーブルのプロパティを有効にするには、マッピングを更新する必要があります。
| ||||||||||||
Customize Mapping Rules for Destination Table Names (オプション) | システムにはデフォルトのテーブル命名ルールがあります:
この機能は、次のシナリオをサポートします。
| ||||||||||||
フィールドデータ型のマッピングを編集 (オプション) | システムは、ソースと送信先のフィールドデータ型間にデフォルトのマッピングを提供します。テーブルの右上隅にある Edit Mapping of Field Data Types をクリックして、マッピングをカスタマイズできます。設定後、Apply and Refresh Mapping をクリックします。 データ型のマッピングを編集する際は、変換ルールが正しいことを確認してください。不正なルールは、型変換の失敗、ダーティデータの生成、タスク実行の中断を引き起こす可能性があります。 | ||||||||||||
送信先テーブル構造の編集 (オプション) | システムは、カスタムテーブル名マッピングルールに基づいて、送信先テーブルが存在しない場合は自動的に作成し、同じ名前の既存テーブルがある場合はそれを使用します。 DataWorks は、ソーステーブルの構造に基づいて送信先テーブルの構造を自動的に生成します。ほとんどの場合、手動での介入は不要です。また、次の方法でテーブル構造を変更することもできます。
既存のテーブルについては、フィールドの追加のみが可能です。新しいテーブルについては、フィールド、パーティションフィールドの追加、およびテーブルタイプやプロパティの設定ができます。詳細については、UI の編集可能なセクションをご参照ください。 | ||||||||||||
Value assignment | ネイティブフィールドは、ソーステーブルと送信先テーブル間で一致するフィールド名に基づいて自動的にマッピングされます。前のステップで追加した新規フィールドには、手動で値を割り当てる必要があります。これを行うには:
定数または変数を割り当てることができます。Value Type ドロップダウンリストでタイプを切り替えます。次のメソッドがサポートされています。
| ||||||||||||
[ソース分割 PK] | [ソース分割 PK] ドロップダウンリストから、ソーステーブルのフィールドを選択するか、Not Split を選択できます。同期タスクが実行されると、このフィールドに基づいてタスクが複数のサブタスクに分割され、データを同時に読み取ります。 プライマリキーなど、データが均等に分散しているフィールドを分割列として使用してください。文字列、浮動小数点、日付型はサポートされていません。 現在、ソース分割 PK 機能は、ソースが MySQL の場合にのみサポートされています。 | ||||||||||||
[完全同期の実行] | ステップ 3 で完全データ同期を設定した場合、このオプションをクリアすることで、特定のテーブルの完全データ同期をスキップできます。これは、別の方法で既に完全データセットを送信先に同期している場合に便利です。 | ||||||||||||
Full condition | 完全ロードフェーズ中にソースにフィルター条件を適用します。 | ||||||||||||
Configure DML Rule | DML メッセージ処理を使用して、キャプチャされたデータ変更 ( | ||||||||||||
完全データマージサイクル | 現在、日次マージのみがサポートされています。[マージ時間のカスタマイズ] 設定で、マージタスクの特定のスケジューリング時間を設定できます。 | ||||||||||||
プライマリキーのマージ | テーブルから 1 つ以上の列を選択して、プライマリキーを定義できます。
|
 アイコンをクリックし、Manual Input と Built-in Variable のオプションを組み合わせて、送信先テーブル名を構築できます。変数には、ソースデータソース名、ソースデータベース名、ソーステーブル名が含まれます。
アイコンをクリックし、Manual Input と Built-in Variable のオプションを組み合わせて、送信先テーブル名を構築できます。変数には、ソースデータソース名、ソースデータベース名、ソーステーブル名が含まれます。





 アイコンをクリックします。
アイコンをクリックします。ステップ 6: 詳細設定の構成
詳細パラメーター設定
タスクを微調整し、カスタムの同期ニーズを満たすには、Advanced Parameters タブに移動して詳細パラメーターを変更します。
ページの右上隅にある [詳細設定] をクリックして、詳細パラメーター設定ページに移動します。
ツールチップに基づいてパラメーター値を変更します。各パラメーターの説明は、その名前の横に表示されます。
AI を活用した設定も使用できます。タスクの同時実行数の調整など、自然言語でコマンドを入力すると、AI モデルが推奨パラメーター値を生成します。その後、AI が生成したパラメーターを受け入れるかどうかを選択できます。
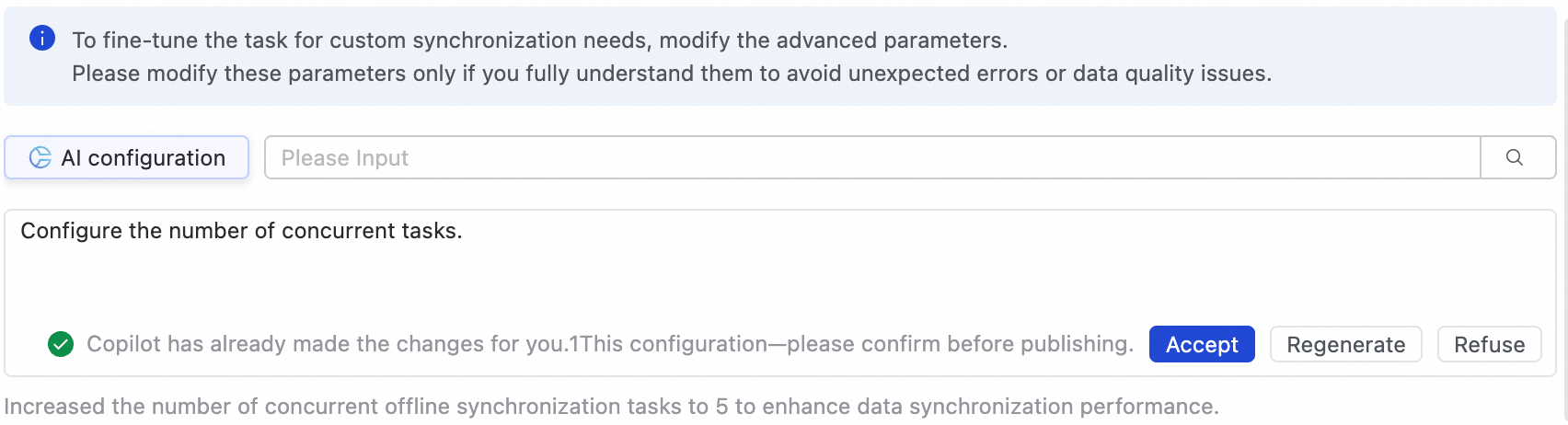
これらのパラメーターは、その目的を完全に理解している場合にのみ変更してください。誤った変更は、タスクの遅延、他のタスクをブロックする過剰なリソース消費、またはデータ損失などの予期しない問題につながる可能性があります。
DDL 機能設定
一部のリアルタイム同期パイプラインは、ソーステーブル構造のメタデータ変更を検出し、送信先に通知できます。送信先はそれに応じて更新するか、アラートの送信、変更の無視、タスクの終了などの他のアクションを実行できます。
ページの右上隅にある Configure DDL Capability をクリックして、各変更タイプに対する処理ポリシーを設定します。サポートされているポリシーは、チャネルによって異なります。
通常:送信先はソースからの DDL 変更を処理します。
無視:変更メッセージは無視され、送信先は変更されません。
エラー:データベース全体のリアルタイム同期タスクが終了し、そのステータスが [エラー] に設定されます。
アラート:ソースでこのタイプの変更が発生したときにユーザーにアラートが送信されます。Configure Alert Rule で DDL 通知ルールを設定する必要があります。
ソースで新しい列が追加され、DDL 同期を介して送信先でも作成された場合、システムは送信先テーブルの既存の行に対してデータをバックフィルしません。
ステップ 7: 同期タスクの実行
同期タスクの設定が完了したら、ページ下部の [完了] をクリックします。
[データ統合] ページの [同期タスク] セクションで、作成した同期タスクを見つけ、Operation 列の Deploy をクリックします。[デプロイ後すぐに開始] を選択した場合、[確認] をクリックするとタスクはすぐに実行されます。それ以外の場合は、手動で開始する必要があります。
説明Data Integration タスクは、実行するために本番環境にデプロイする必要があります。そのため、新しく作成または編集されたタスクは、デプロイ後にのみ有効になります。
Tasks セクションの同期タスクの Name/ID をクリックし、同期タスクの詳細な実行プロセスを表示します。
次のステップ
タスクを設定した後、タスクの管理、テーブルの追加または削除、モニタリングとアラートの設定、主要な運用メトリックの表示ができます。詳細については、「完全および増分同期タスクの O&M」をご参照ください。
よくある質問
Q: ベーステーブルのデータが期待どおりに更新されないのはなぜですか?
A: これにはいくつかの理由が考えられます。一般的な原因と解決策については、以下の表をご参照ください。

症状 | 原因 | 解決策 |
増分ログテーブルの T-1 パーティションのデータ出力チェックが失敗しました。 | リアルタイム同期タスクの失敗により、増分ログテーブルの T-1 パーティションのデータが生成されませんでした。 |
|
送信先ベーステーブルの T-2 パーティションのデータ出力チェックが失敗します。 |
|
|