DataWorks では、E-MapReduce (EMR) MapReduce (MR) ノードを作成して、大規模なデータセットを並列マップタスクに分割することで、データ処理効率を大幅に向上させることができます。このトピックでは、Object Storage Service (OSS) からテキストファイルを読み取り、その中の単語をカウントする EMR MR ジョブを開発および設定する例を示します。
前提条件
Alibaba Cloud E-MapReduce (EMR) クラスターを作成し、DataWorks に登録済みであること。詳細については、「DataStudio:EMR コンピューティングリソースのバインド」をご参照ください。
-
(任意、RAM ユーザーの場合) タスク開発用の RAM ユーザーが対応するワークスペースに追加され、Development または スペース管理者 (このロールは広範な権限を持つため、注意して付与してください) のロールが付与されていること。メンバーの追加方法の詳細については、「ワークスペースへのメンバーの追加」をご参照ください。
Alibaba Cloud アカウントを使用している場合は、このステップをスキップできます。
このトピックの例に従うには、Object Storage Service (OSS) にバケットを作成します。詳細については、「バケットの作成」をご参照ください。
制限事項
このタイプのノードは、サーバーレスリソースグループ (推奨) または専用スケジューリングリソースグループでのみ実行できます。
DataWorks で DataLake またはカスタムクラスターのメタデータを管理するには、まずクラスターに EMR-HOOK を設定する必要があります。詳細については、「Hive EMR-HOOK の設定」をご参照ください。
説明クラスターに EMR-HOOK が設定されていない場合、DataWorks はリアルタイムのメタデータを表示したり、監査ログを生成したり、データリネージを表示したり、EMR 関連のデータガバナンスタスクを実行したりできません。
初期データと JAR パッケージの準備
初期データの準備
input01.txt という名前のサンプルファイルを作成し、次の内容を記述します。
hadoop emr hadoop dw
hive hadoop
dw emr初期データファイルのアップロード
OSS コンソールにログインします。左側のナビゲーションウィンドウで、[バケット] をクリックします。
対象のバケット名をクリックして、File Management ページを開きます。
この例では、
onaliyun-bucket-2という名前のバケットを使用します。Create Directory をクリックして、初期データと JAR リソース用のディレクトリを作成します。
[ディレクトリ名] を
emr/datas/wordcount02/inputsに設定して、初期データ用のディレクトリを作成します。[ディレクトリ名] を
emr/jarsに設定して、JAR リソース用のディレクトリを作成します。
初期データファイルをそのディレクトリにアップロードします。
/emr/datas/wordcount02/inputsパスに移動し、Upload File をクリックします。[アップロードするファイル] エリアで、[ファイルの選択] をクリックし、
input01.txtファイルをバケットに追加してから、Upload File をクリックします。
MapReduce ジョブと JAR パッケージのビルド
IntelliJ IDEA プロジェクトを開き、pom.xml ファイルに次の依存関係を追加します。
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-common</artifactId> <version>2.8.5</version> <!--EMR MR で使用されているバージョン 2.8.5 を使用します。--> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.8.5</version> </dependency>MapReduce で OSS ファイルの読み書きを行うには、次のパラメーターを設定する必要があります。
重要リスク警告:Alibaba Cloud アカウントの AccessKey ペアは、すべての API オペレーションへのフルアクセスを許可します。AccessKey ID と AccessKey Secret が漏洩すると、アカウント配下のすべてのリソースのセキュリティが侵害されます。API 呼び出しや日常の運用には、RAM ユーザーを使用することを強く推奨します。AccessKey ID や AccessKey Secret をプロジェクトコードやその他の一般にアクセス可能な場所にハードコーディングしないでください。以下のコードはデモンストレーションのみを目的としています。AccessKey 情報を安全に保管してください。
conf.set("fs.oss.accessKeyId", "${accessKeyId}"); conf.set("fs.oss.accessKeySecret", "${accessKeySecret}"); conf.set("fs.oss.endpoint","${endpoint}");次の表にパラメーターを示します。
${accessKeyId}:ご利用の Alibaba Cloud アカウントの AccessKey ID。${accessKeySecret}:ご利用の Alibaba Cloud アカウントの AccessKey Secret。${endpoint}:OSS のパブリックエンドポイント。エンドポイントは、EMR クラスターが存在するリージョンによって異なります。OSS バケットとクラスターは同じリージョンにある必要があります。詳細については、「リージョンとエンドポイント」をご参照ください。
次の Java コードは、公式の Hadoop WordCount サンプルを修正したものです。これには、ジョブに OSS ファイルへのアクセス権限を付与するための AccessKey ID と AccessKey Secret の設定が含まれています。
Java コードを編集した後、JAR ファイルにパッケージ化します。この例では、
onaliyun_mr_wordcount-1.0-SNAPSHOT.jarという名前の JAR ファイルが生成されます。
操作手順
EMR MR ノードの設定タブで、次のようにタスクを開発します。
EMR MR タスクの開発
要件に応じて、次のいずれかの方法を選択します。
方法 1:JAR のアップロードと参照
ローカルマシンから DataStudio にリソースをアップロードし、ノードで参照することもできます。リソースが大きすぎて DataWorks コンソール経由でアップロードできない場合は、HDFS に保存してコード内で参照できます。
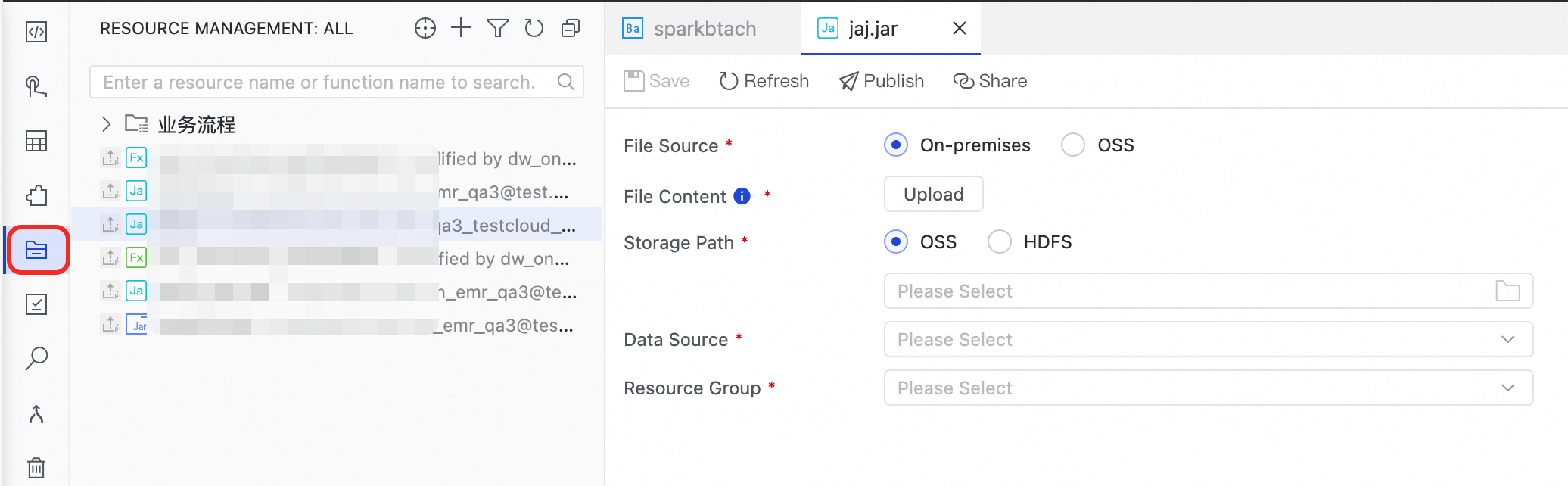
JAR リソースの作成
詳細については、「リソースの管理」をご参照ください。「初期データと JAR パッケージの準備」ステップの JAR パッケージを
emr/jarsディレクトリに保存します。Click Upload をクリックします。Storage Path、Data Sources、および Resource Group パラメーターを設定します。
Save をクリックします。
JAR リソースの参照
EMR MR ノードを開き、設定タブに移動します。
左側のリソース管理ペインで、参照したいリソースを見つけます。この例では、リソースは
onaliyun_mr_wordcount-1.0-SNAPSHOT.jarです。リソースを右クリックし、Insert Resource Path を選択します。リソースを参照すると、EMR MR ノードの設定タブに参照文が表示され、リソースが正常に参照されたことを示します。次のコマンドを実行します。リソースパッケージ、バケット名、パスを実際の情報に置き換えてください。
##@resource_reference{"onaliyun_mr_wordcount-1.0-SNAPSHOT.jar"} onaliyun_mr_wordcount-1.0-SNAPSHOT.jar cn.apache.hadoop.onaliyun.examples.EmrWordCount oss://onaliyun-bucket-2/emr/datas/wordcount02/inputs oss://onaliyun-bucket-2/emr/datas/wordcount02/outputs説明EMR MR ノードのコードエディタではコメントはサポートされていません。
方法 2:OSS リソースの参照
OSS REF メソッドを使用して、OSS から直接リソースを参照できます。ノードが実行されると、DataWorks は参照された OSS リソースを自動的にローカル環境にダウンロードします。この方法は、EMR タスクが JAR ファイルやスクリプトに依存するシナリオでよく使用されます。
JAR リソースのアップロード
コードを開発した後、OSS コンソールにログインします。左側のナビゲーションウィンドウで、[バケット] をクリックします。
対象のバケット名をクリックして、File Management ページを開きます。
この例では、
onaliyun-bucket-2という名前のバケットを使用します。JAR リソースをそのディレクトリにアップロードします。
emr/jarsディレクトリに移動します。Upload File をクリックします。[アップロードするファイル] エリアで、[ファイルの選択] をクリックし、onaliyun_mr_wordcount-1.0-SNAPSHOT.jarファイルを追加してから、Upload File をクリックします。
JAR リソースの参照
EMR MR ノードの設定タブで、JAR リソースを参照するコードを記述します。
hadoop jar ossref://onaliyun-bucket-2/emr/jars/onaliyun_mr_wordcount-1.0-SNAPSHOT.jar cn.apache.hadoop.onaliyun.examples.EmrWordCount oss://onaliyun-bucket-2/emr/datas/wordcount02/inputs oss://onaliyun-bucket-2/emr/datas/wordcount02/outputs説明コマンドのフォーマットは次のとおりです:
hadoop jar <実行する JAR のパス> <メインクラスの完全名> <入力ファイルディレクトリ> <出力ディレクトリ>。次の表に JAR パスのパラメーターを示します。
パラメーター
説明
実行する JAR のパス
フォーマットは
ossref://{endpoint}/{bucket}/{object}です。Endpoint:OSS のパブリックエンドポイント。このパラメーターを空のままにすると、EMR クラスターと同じリージョンにあるバケットからのみリソースを参照できます。
Bucket:OSS がオブジェクトを保存するために使用するコンテナ。各 Bucket には一意の名前があります。OSS コンソールにログインして、アカウント配下のすべての Bucket を表示できます。
object:bucket に保存されている特定のオブジェクトで、ファイルまたはパスを指定できます。
(任意) 詳細パラメーターの設定
右側のペインで、Scheduling Settings タブをクリックします。 セクションで、次のパラメーターを設定できます。
説明利用可能な詳細パラメーターは、次の表に示すように、EMR クラスターのタイプによって異なります。
Scheduling Settings タブの セクションで、追加の オープンソース Spark プロパティ を設定します。
DataLake およびカスタムクラスター:EMR on ECS
パラメーター
説明
queue
ジョブがサブミットされるキュー。デフォルト値は default です。EMR YARN の詳細については、「基本的なキュー設定」をご参照ください。
priority
ジョブの優先度。デフォルト値は 1 です。
FLOW_SKIP_SQL_ANALYZE
SQL ステートメントの実行モード。有効な値:
true:一度に複数の SQL ステートメントを実行します。false(デフォルト):一度に 1 つの SQL ステートメントを実行します。
説明このパラメーターは、データ開発環境でのテスト実行でのみサポートされます。
その他
詳細設定セクションでカスタム MR ジョブパラメーターを追加することもできます。コードをコミットすると、DataWorks は
-D key=valueステートメントを使用して、新しいパラメーターをコマンドに自動的に追加します。Hadoop クラスター:EMR on ECS
パラメーター
説明
queue
ジョブがサブミットされるキュー。デフォルト値は default です。EMR YARN の詳細については、「基本的なキュー設定」をご参照ください。
priority
ジョブの優先度。デフォルト値は 1 です。
USE_GATEWAY
このノードからゲートウェイクラスター経由でジョブをサブミットするかどうかを指定します。有効な値:
true:ゲートウェイクラスター経由でジョブをサブミットします。false(デフォルト):ゲートウェイクラスター経由でジョブをサブミットしません。ジョブはデフォルトでマスターノードにサブミットされます。
説明このパラメーターを
trueに設定しても、ノードのクラスターがゲートウェイクラスターに関連付けられていない場合、EMR ジョブのサブミットは失敗します。タスクの実行
Run Configuration の Compute Resource で、Compute Resource と Resource Group を設定します。
説明タスクの要件に応じて、CUs for Scheduling を指定することもできます。デフォルト値は
0.25です。パブリックインターネットまたは Virtual Private Cloud (VPC) 経由でデータソースにアクセスするには、データソースに接続できるスケジューリング用のリソースグループを使用する必要があります。詳細については、「ネットワーク接続ソリューション」をご参照ください。
ツールバーのパラメーターダイアログボックスで、作成したデータソースを選択し、Run をクリックします。
ノードタスクを定期的に実行する必要がある場合は、そのスケジューリングプロパティを設定します。詳細については、「ノードのスケジューリングプロパティの設定」をご参照ください。
ノードを設定した後、デプロイする必要があります。詳細については、「ノードのデプロイ」をご参照ください。
タスクがデプロイされた後、オペレーションセンターでそのステータスを表示できます。詳細については、「オペレーションセンターの概要」をご参照ください。
結果の表示
OSS コンソールにログインします。バケット内の送信先ディレクトリで出力ファイルを表示できます。この例では、パスは emr/datas/wordcount02/outputs です。

DataWorks で統計結果を読み取ります。
EMR Hive ノードを作成します。詳細については、「スケジュールされたワークフローのノードの作成」をご参照ください。
EMR Hive ノードで、OSS 内のデータにマッピングされた Hive 外部テーブルを作成し、テーブルデータをクエリします。以下はサンプルコードです:
CREATE EXTERNAL TABLE IF NOT EXISTS wordcount02_result_tb ( `word` STRING COMMENT 'Word', `count` STRING COMMENT 'Count' ) ROW FORMAT delimited fields terminated by '\t' location 'oss://onaliyun-bucket-2/emr/datas/wordcount02/outputs/'; SELECT * FROM wordcount02_result_tb;次の図に結果を示します。
