この実験では、OpenLake データレイクハウス環境における小売 e コマースのデータ開発および分析シナリオを体験します。DataWorks を使用して、マルチエンジン共同開発、ビジュアルワークフローオーケストレーション、およびデータカタログ管理を行います。また、Python プログラミングとデバッグを実践し、Notebook を使用して AI を活用したインタラクティブなデータ探索と分析を行います。
背景
DataWorks の概要
DataWorks は、データレイクハウスの開発とガバナンスのためのインテリジェントなプラットフォームです。Alibaba の 15 年にわたるビッグデータ構築手法に基づいて構築されています。MaxCompute、E-MapReduce、Hologres、Flink、PAI など、数十の Alibaba Cloud ビッグデータおよび AI コンピューティングサービスと深く統合されています。DataWorks は、データウェアハウス、データレイク、および OpenLake データレイクハウスアーキテクチャ向けに、インテリジェントな抽出・変換・書き出し (ETL) 開発、データ分析、およびプロアクティブなデータ資産ガバナンスサービスを提供します。これにより、「Data+AI」ライフサイクル全体を管理できます。2009 年以来、DataWorks は Alibaba のデータアーキテクチャを継続的に製品化してきました。政府、金融、小売、インターネット、自動車、製造など、さまざまな業界にサービスを提供しています。何万もの顧客が DataWorks を使用してデジタルトランスフォーメーションを推進し、価値を創造しています。
DataWorks Copilot の概要
DataWorks Copilot は DataWorks のインテリジェントアシスタントです。DataWorks では、DataWorks のデフォルトモデルである Qwen3-235B-A22B、DeepSeek-R2-0528、または Qwen3-Coder 大規模モデルを選択して Copilot 操作を実行できます。DeepSeek-R2 の深い推論機能により、DataWorks Copilot は自然言語対話を通じて SQL コードの生成、最適化、テストなどの複雑な操作を実行するのに役立ちます。これにより、ETL (抽出·変換·書き出し) 開発とデータ分析の効率が大幅に向上します。
DataWorks Notebook の概要
DataWorks Notebook は、データ開発と分析のためのインテリジェントでインタラクティブなツールです。複数のデータエンジンにまたがる SQL または Python 分析をサポートしています。コードを即座に実行またはデバッグし、視覚化されたデータ結果を表示できます。DataWorks Notebook は、他のタスクノードとオーケストレーションしてワークフローに組み込み、スケジューling システムに送信して実行することもできます。これにより、複雑なビジネスシナリオを柔軟に実装できます。
使用上の注意
DataWorks Copilot のパブリックプレビューは、リージョンとバージョンの制限を受けます。詳細については、「パブリックプレビューに関するお知らせ」をご参照ください。
DataStudio で Python と Notebook を使用するには、まず 個人開発者環境 に切り替える必要があります。
制限事項
OpenLake は Data Lake Formation (DLF) 2.0 のみをサポートします。
データカタログは Data Lake Formation (DLF) 2.0 のみをサポートします。
Qwen3-235B-A22B/DeepSeek-R2 モデルは、中国 (杭州)、中国 (上海)、中国 (北京)、中国 (張家口)、中国 (深圳)、および中国 (成都) のリージョンで利用できます。
Qwen3-Coder モデルは、中国 (杭州)、中国 (上海)、中国 (北京)、中国 (張家口)、中国 (ウランチャブ)、中国 (深圳)、および中国 (成都) で利用できます。
前提条件
Alibaba Cloud アカウントを準備したか、RAM ユーザーを準備したこと。
ワークスペースを作成したこと。
説明[Data Development (DataStudio) (New) のパブリックプレビューに参加] を選択します。
計算資源をアタッチしたこと。
手順
ステップ 1: データカタログを管理する
データレイクハウスの データカタログ 管理機能を使用すると、DLF、MaxCompute、Hologres などのサービスのデータカタログを管理および作成できます。
DataStudio で、左側のメニューの
 アイコンをクリックして [データカタログ] を開きます。ナビゲーションウィンドウで、管理するメタデータタイプを見つけ、[プロジェクトを追加] をクリックします。このボタンの名前はメタデータタイプによって異なる場合があります。このトピックでは MaxCompute を例として使用します。
アイコンをクリックして [データカタログ] を開きます。ナビゲーションウィンドウで、管理するメタデータタイプを見つけ、[プロジェクトを追加] をクリックします。このボタンの名前はメタデータタイプによって異なる場合があります。このトピックでは MaxCompute を例として使用します。DataWorks ワークスペースからデータソースを追加できます。[MaxCompute-Project] タブで権限を持つ MaxCompute プロジェクトを選択することもできます。

プロジェクトを追加すると、対応するメタデータタイプの下に表示されます。プロジェクト名をクリックして、データカタログの詳細ページに移動します。
データカタログの詳細ページで、スキーマを選択し、任意のテーブル名をクリックしてテーブルの詳細を表示します。
データカタログでは、テーブルを視覚的に作成できます。
データカタログを指定したスキーマの [テーブル] レベルまで展開します。右側の
 アイコンをクリックして [テーブルを作成] ページを開きます。
アイコンをクリックして [テーブルを作成] ページを開きます。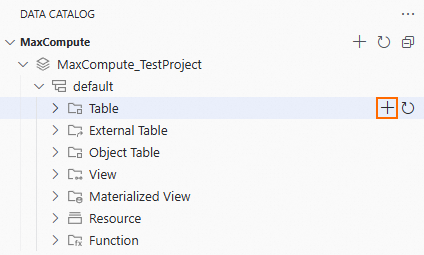
[テーブルを作成] ページでは、次の方法でテーブルを作成できます。
エリア ① で、[テーブル名] と [フィールド情報] を入力します。
エリア ② では、[DDL] 文を直接入力してテーブルを作成できます。
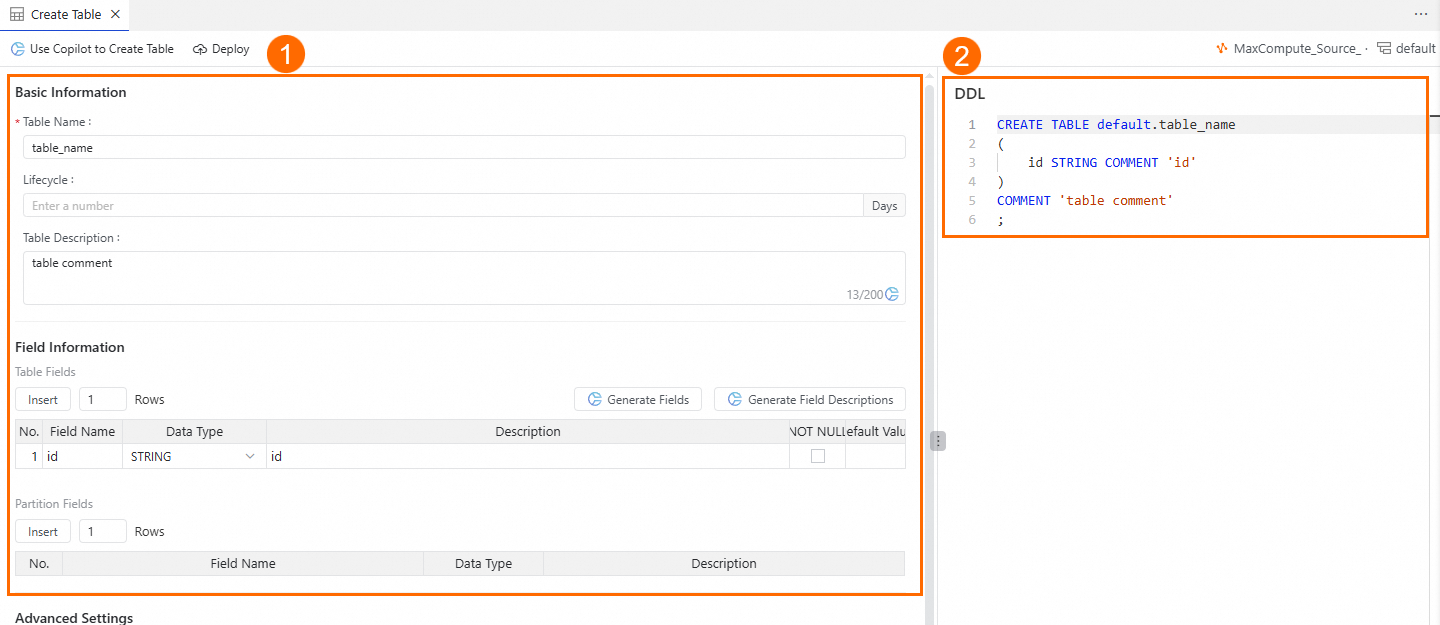
ページ上部の [公開] ボタンをクリックしてテーブルを作成します。
ステップ 2:ワークフローを調整する
ワークフローを使用すると、ビジネスロジックに基づいてさまざまなタイプのデータ開発ノードをドラッグアンドドロップしてオーケストレーションできます。各ノードのスケジューリング時間などの共通パラメーターを設定する必要はありません。これにより、複雑なタスクプロジェクトを簡単に管理できます。
DataStudio で、左側のプライマリメニューの
 アイコンをクリックして [データ開発] を開きます。左側のナビゲーションウィンドウで [プロジェクトフォルダ] を見つけ、その横にある
アイコンをクリックして [データ開発] を開きます。左側のナビゲーションウィンドウで [プロジェクトフォルダ] を見つけ、その横にある  アイコンをクリックし、[新しいワークフロー] を選択します。
アイコンをクリックし、[新しいワークフロー] を選択します。ワークフローの [名前] を入力し、[OK] をクリックしてワークフローエディターを開きます。
ワークフローエディターで、キャンバス上の [ノードをドラッグまたはクリックして追加] をクリックします。[ノードを追加] ダイアログボックスで、[ノードタイプ] を [ゼロロードノード] に設定し、カスタムの [ノード名] を入力してから [確認] をクリックします。
左側のノードタイプのリストから、必要なノードタイプを見つけてキャンバスにドラッグします。[ノードを追加] ダイアログボックスで、[ノード名] を入力し、[確認] をクリックします。
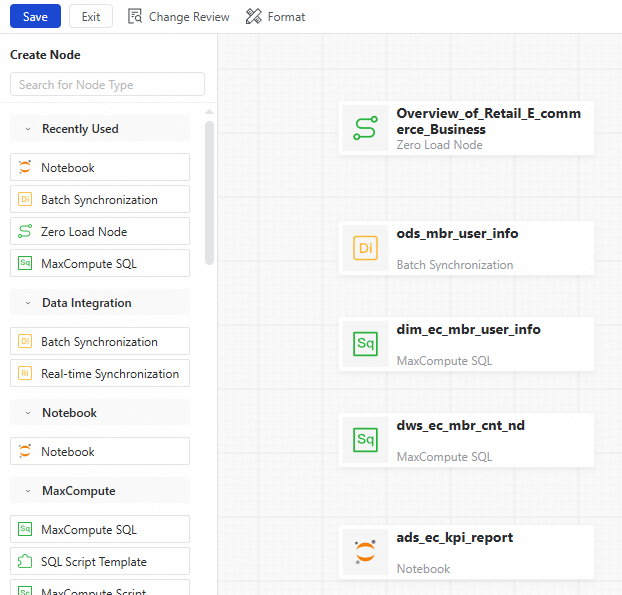
キャンバス上で、依存関係を作成する 2 つのノードを見つけます。一方のノードの下端の中央にマウスポインターを合わせます。ポインターが + に変わったら、矢印をもう一方のノードにドラッグしてマウスを離します。図のように依存関係を設定したら、上部のツールバーで [保存] をクリックします。
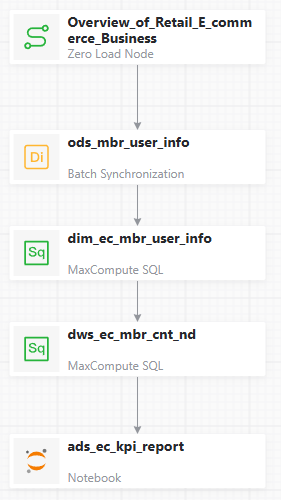
[保存] をクリックした後、必要に応じてキャンバスのレイアウトを調整できます。

ワークフローキャンバスの右側で、[スケジューリング構成] をクリックします。[スケジューリング構成] パネルを使用して、ワークフローのスケジューリングパラメーターとノードの依存関係を構成します。[スケジューリングパラメーター] セクションで、[パラメーターを追加] をクリックします。パラメーター名フィールドに bizdate と入力します。パラメーター値のドロップダウンリストから、$[yyyymmdd-1] を選択します。
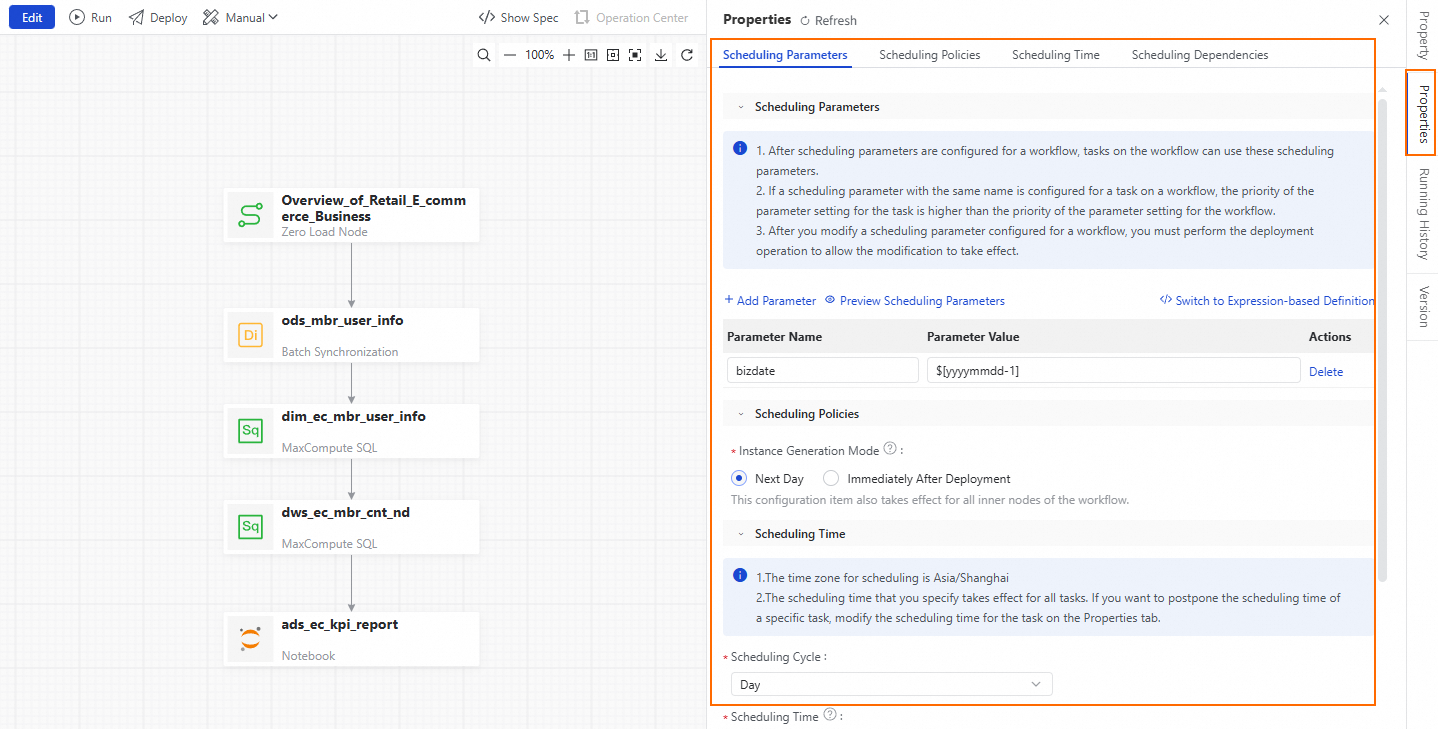
[ワークスペースルートノードを使用] をクリックして、このノードをワークフローの上流依存関係として設定します。

ワークフローキャンバスの上にある [公開] をクリックします。右下隅に [公開コンテンツ] パネルが表示されます。パネルで、[本番環境への公開を開始] をクリックし、プロンプトに従って確認します。

ステップ 3: マルチエンジン共同開発を使用する
DataStudio は、Data Integration、MaxCompute、Hologres、EMR、Flink、Python、Notebook、ADB など、さまざまなエンジンにまたがる数十種類のノードタイプのデータウェアハウス開発をサポートしています。複雑なスケジューリング依存関係をサポートし、開発環境を本番環境から分離する開発モデルを提供します。この実験では、Flink SQL Streaming ノードの作成を例として使用します。
DataStudio で、左側のナビゲーションウィンドウの
 アイコンをクリックして [データ開発] ページを開きます。ナビゲーションウィンドウで [プロジェクトフォルダ] を見つけ、その横にある
アイコンをクリックして [データ開発] ページを開きます。ナビゲーションウィンドウで [プロジェクトフォルダ] を見つけ、その横にある  アイコンをクリックします。カスケードメニューで [Flink SQL Streaming] をクリックしてノードエディターを開きます。エディターが開く前に、[ノード名] を入力して Enter キーを押します。
アイコンをクリックします。カスケードメニューで [Flink SQL Streaming] をクリックしてノードエディターを開きます。エディターが開く前に、[ノード名] を入力して Enter キーを押します。プリセットノード名:
ads_ec_page_visit_log。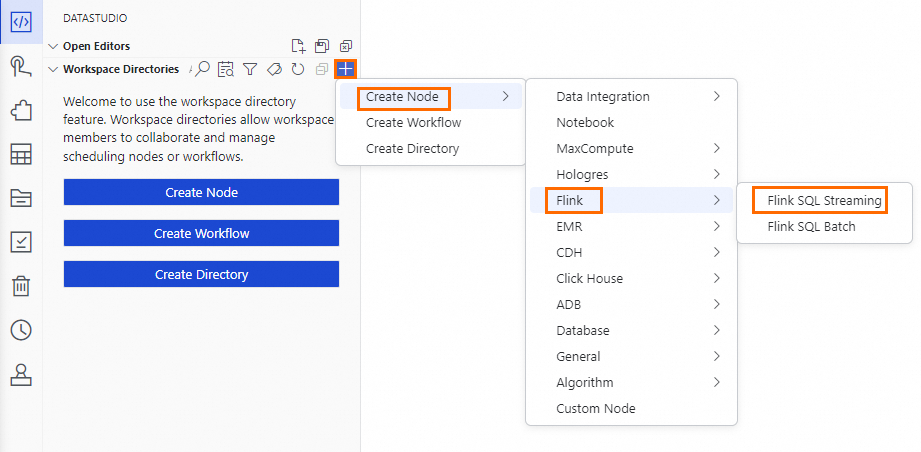
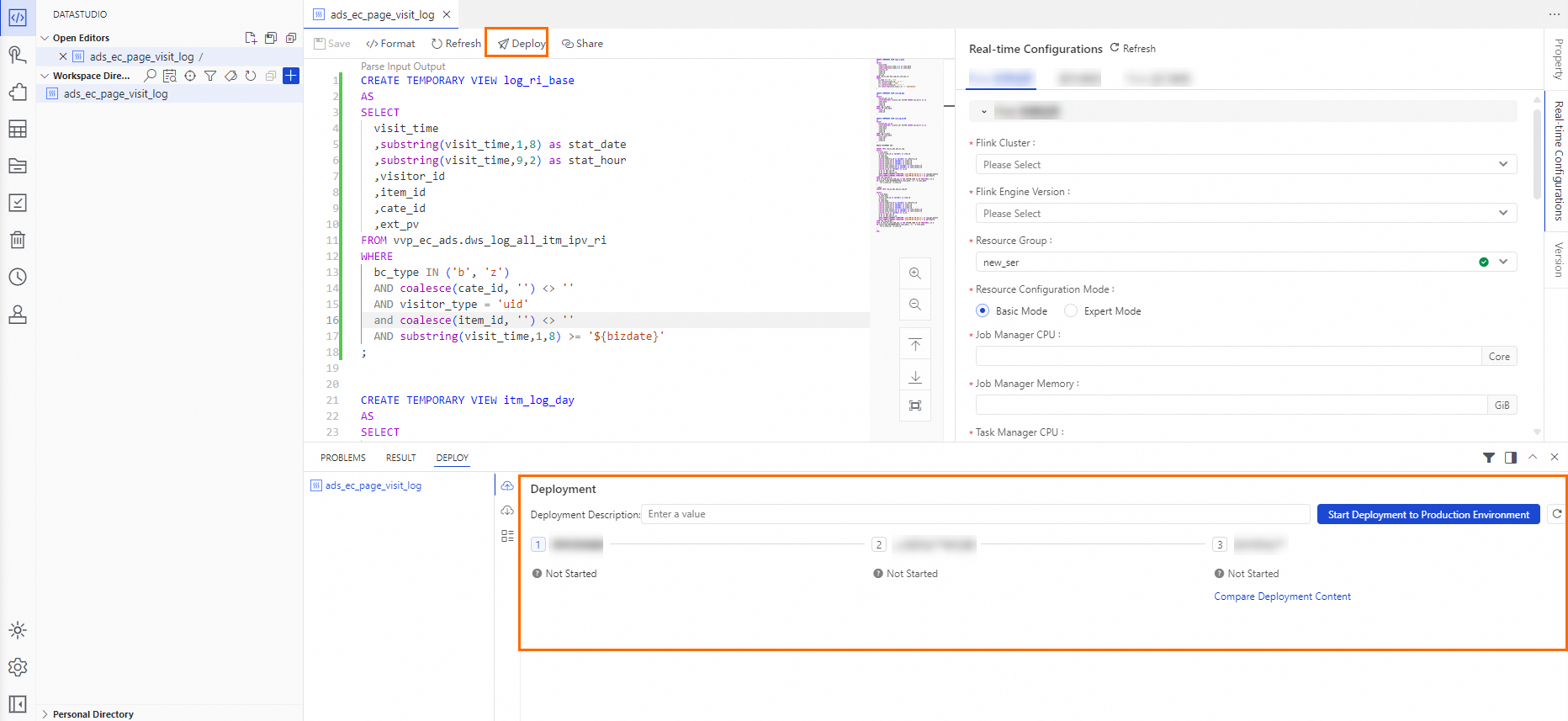
ノードエディターで、プリセットの Flink SQL Stream コードをコードエディターに貼り付けます。

ノードエディターで、コードエディターの右側にある [リアルタイム構成] をクリックして、[Flink リソース情報]、[スクリプトパラメーター]、および [Flink 実行時パラメーター] を構成します。

リアルタイム設定を構成した後、コードエディターの上にある [保存] をクリックします。次に [公開] をクリックします。右下隅に表示される [公開コンテンツ] パネルで、[本番環境への公開を開始] をクリックし、プロンプトに従って確認します。
ステップ 4:個人開発環境に入る
個人開発環境は、カスタムコンテナイメージ、ユーザー NAS および Git への接続、Notebook を使用した Python でのプログラミングをサポートしています。
DataStudio で、ページ上部の ![]() アイコンをクリックします。ドロップダウンメニューで、入りたい個人開発環境を選択し、ページが読み込まれるのを待ちます。
アイコンをクリックします。ドロップダウンメニューで、入りたい個人開発環境を選択し、ページが読み込まれるのを待ちます。

ステップ 5: Python でプログラミングとデバッグを行う
DataWorks は DSW と深く統合されています。個人開発環境に入った後、DataStudio は Python コードの記述、デバッグ、実行、スケジューリングをサポートします。
このステップを開始する前に、ステップ 4: 個人開発環境に入る を完了する必要があります。
DataStudio ページで、個人の開発者環境の
workspaceフォルダをクリックします。[個人用フォルダ] の右側にある アイコンをクリックします。左側のリストに無題のファイルが表示されます。ファイルに名前を付け、Enter キーを押し、生成されるのを待ちます。
アイコンをクリックします。左側のリストに無題のファイルが表示されます。ファイルに名前を付け、Enter キーを押し、生成されるのを待ちます。プリセットファイル名:
ec_item_rec.py。
Python ファイルページのコードエディターに、プリセットの Python コードを入力します。次に、コードエディターの上にある [Python ファイルを実行] をクリックし、ページ下部の [ターミナル] で結果を確認します。

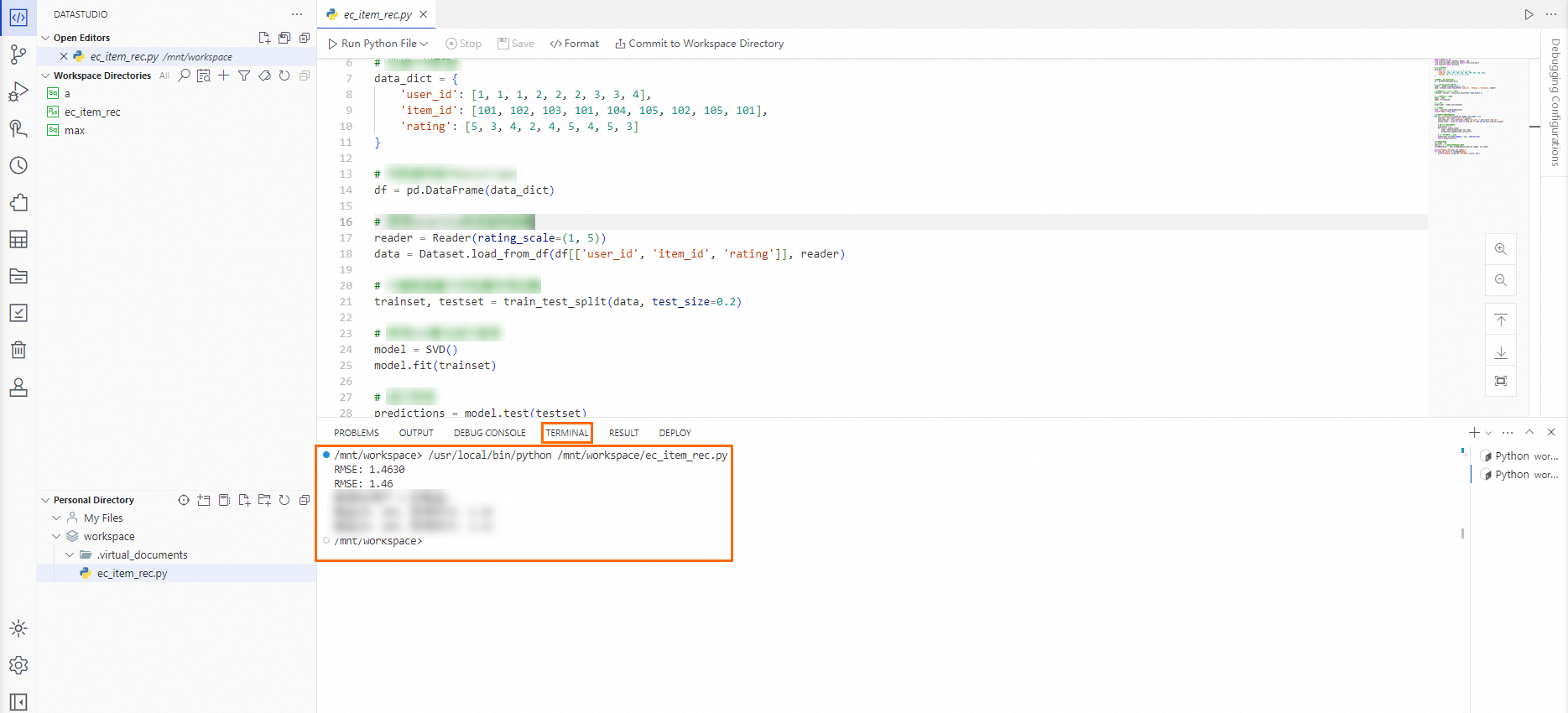
コードをデバッグするには、コードエディターの上にある [Python ファイルをデバッグ] をクリックするか、コードエディターの左側にあるパネルの
 アイコンをクリックします。行番号の左側をクリックしてブレークポイントを設定できます。
アイコンをクリックします。行番号の左側をクリックしてブレークポイントを設定できます。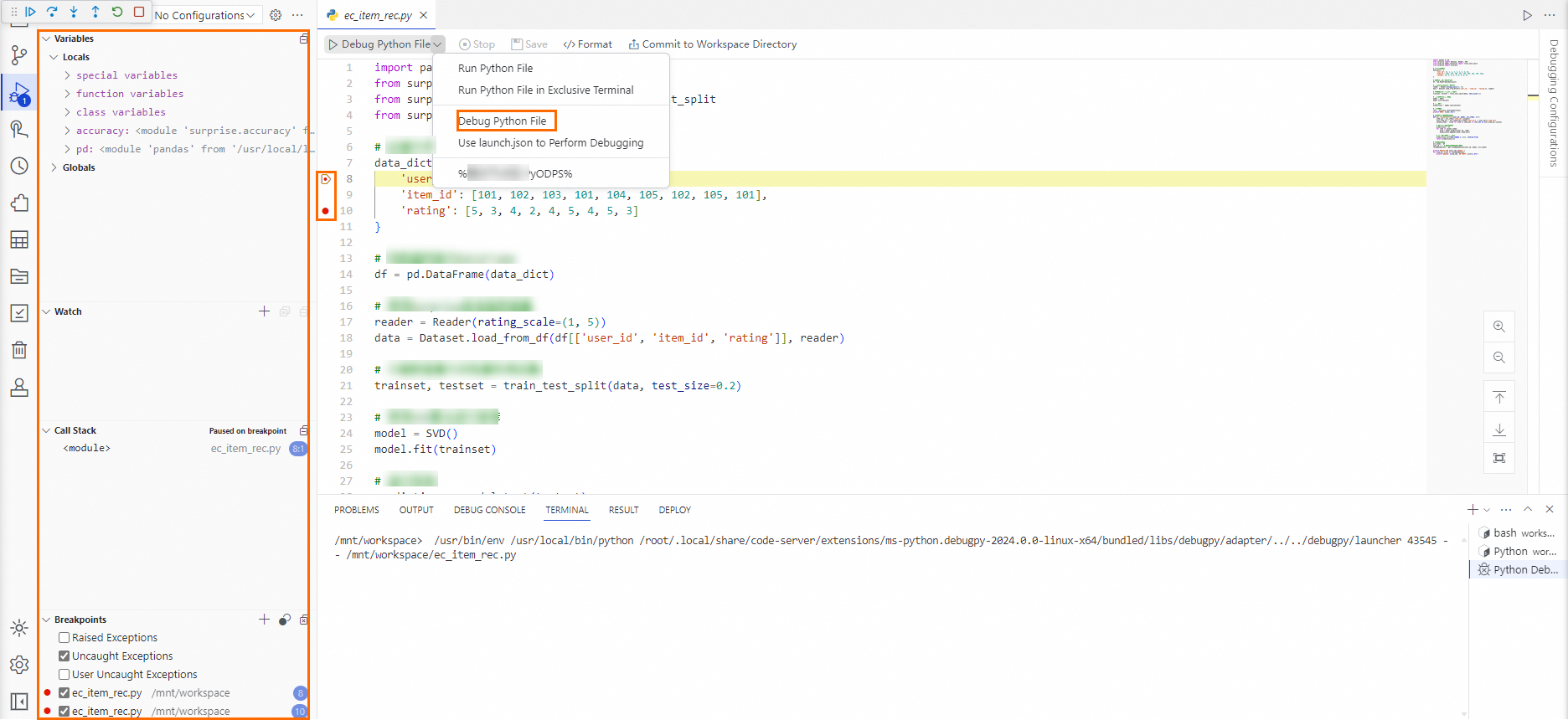
ステップ 6: Notebook でデータを探索する
Notebook のデータ探索操作は、個人開発環境で実行されます。開始する前に ステップ 4: 個人開発環境に入る を完了する必要があります。
Notebook の作成
[DataStudio] > [データ開発] に移動します。
[個人フォルダ] で、ターゲットフォルダを右クリックし、[新しい Notebook] を選択します。
Notebook の名前を入力し、Enter キーを押すか、ページ上の空白領域をクリックして名前を適用します。
個人フォルダで、Notebook 名をクリックしてエディターで開きます。
Notebook の使用
以下のステップは独立しており、任意の順序で実行できます。
Notebook マルチエンジン開発
EMR Spark SQL
DataWorks Notebook で、
 ボタンをクリックして新しい SQL Cell を作成します。
ボタンをクリックして新しい SQL Cell を作成します。SQL Cell に、dim_ec_mbr_user_info テーブルをクエリする次の文を入力します。
SQL Cell の右下隅で、SQL Cell タイプを EMR Spark SQL に、計算資源を
openlake_serverless_sparkに設定します。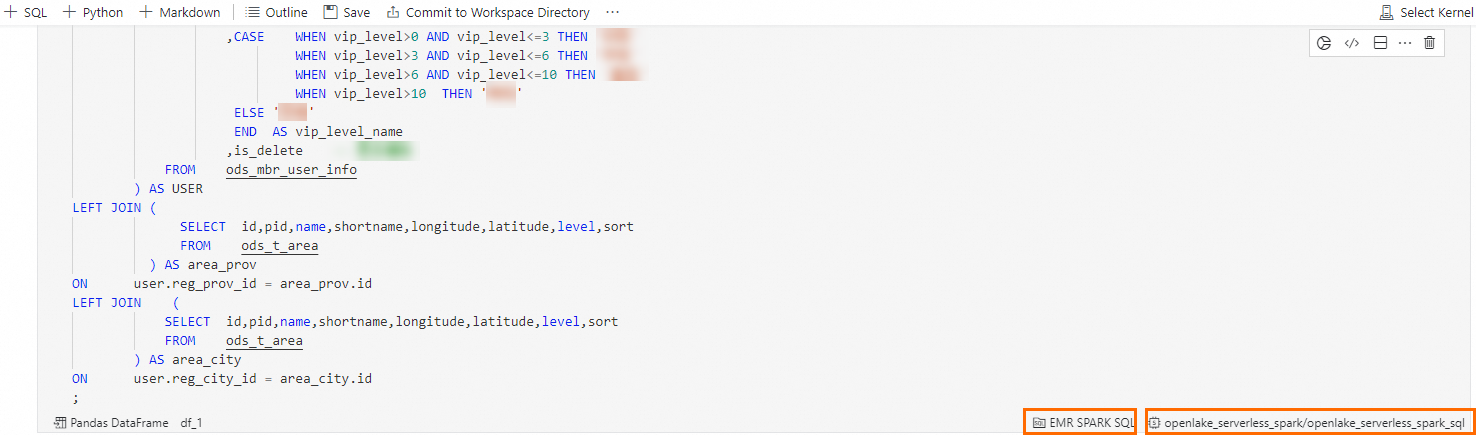
[実行] ボタンをクリックし、実行が完了するのを待って、データ結果を表示します。
StarRocks SQL
DataWorks Notebook で、
 ボタンをクリックして新しい SQL Cell を作成します。
ボタンをクリックして新しい SQL Cell を作成します。SQL Cell に、dws_ec_trd_cate_commodity_gmv_kpi_fy テーブルをクエリする次の文を入力します。
SQL Cell の右下隅で、SQL Cell タイプを StarRocks SQL に、計算資源を
openlake_starrocksに設定します。
[実行] ボタンをクリックし、実行が完了するのを待って、データ結果を表示します。
Hologres SQL
DataWorks Notebook で、
ボタンをクリックして新しい SQL Cell を作成します。SQL Cell に、dws_ec_mbr_cnt_std テーブルをクエリする次の文を入力します。
SQL Cell の右下隅で、SQL Cell タイプを Hologres SQL に、計算資源を
openlake_hologresに設定します。
[実行] ボタンをクリックし、実行が完了するのを待って、データ結果を表示します。
MaxCompute SQL
DataWorks Notebook で、
ボタンをクリックして新しい SQL Cell を作成します。SQL Cell に、dws_ec_mbr_cnt_std テーブルをクエリする次の文を入力します。
SQL Cell の右下隅で、SQL Cell タイプを MaxCompute SQL に、計算資源を
openlake_maxcomputeに設定します。
[実行] ボタンをクリックし、実行が完了するのを待って、データ結果を表示します。
Notebook インタラクティブデータ
DataWorks Notebook で、
 ボタンをクリックして新しい Python Cell を作成します。
ボタンをクリックして新しい Python Cell を作成します。Python Cell の右上隅にある
 ボタンをクリックして、DataWorks Copilot インテリジェントプログラミングアシスタントを開きます。
ボタンをクリックして、DataWorks Copilot インテリジェントプログラミングアシスタントを開きます。DataWorks Copilot の入力ボックスに、メンバーの年齢をクエリするための ipywidgets インタラクティブコンポーネントを生成する次の要件を入力します。
説明説明: Python を使用して、メンバーの年齢用のスライダーウィジェットを生成します。値の範囲は 1 から 100 で、デフォルト値は 20 です。ウィジェットの値の変更をリアルタイムで監視し、その値を query_age という名前のグローバル変数に保存します。
DataWorks Copilot によって生成された Python コードを確認し、[承認] ボタンをクリックします。

Python Cell の実行ボタンをクリックし、実行が完了するのを待って、生成されたインタラクティブコンポーネントを表示します。Copilot によって生成されたコードまたはプリセットコードを実行できます。インタラクティブコンポーネントをスライドしてターゲットの年齢を選択することもできます。

DataWorks Notebook で、
 ボタンをクリックして新しい SQL Cell を作成します。
ボタンをクリックして新しい SQL Cell を作成します。SQL Cell に、Python で定義されたメンバー年齢変数
${query_age}を含む次のクエリ文を入力します。SELECT * FROM openlake_win.default.dim_ec_mbr_user_info -- メンバー基本情報ディメンションテーブルからすべての列を選択 WHERE CAST(id_age AS INT) >= ${query_age}; -- 年齢が query_age 以上のメンバーを選択SQL Cell の右下隅で、SQL Cell タイプを Hologres SQL に、計算資源を
openlake_hologresに設定します。
[実行] ボタンをクリックし、実行が完了するのを待って、データ結果を表示します。
結果で、
 ボタンをクリックしてチャートを生成します。
ボタンをクリックしてチャートを生成します。
Notebook モデルの開発とトレーニング
DataWorks Notebook で、
ボタンをクリックして新しい SQL Cell を作成します。SQL Cell に、ods_trade_order テーブルをクエリする次の文を入力します。
SELECT * FROM openlake_win.default.ods_trade_order; -- 注文テーブルからすべての列を選択SQL クエリの結果を DataFrame 変数に書き込みます。df の場所をクリックし、
df_mlなどのカスタム DataFrame 変数名を入力します。
SQL Cell の [実行] ボタンをクリックし、実行が完了するのを待って、データ結果を表示します。
DataWorks Notebook で、
 ボタンをクリックして新しい Python Cell を作成します。
ボタンをクリックして新しい Python Cell を作成します。Python Cell に、Pandas を使用してデータをクリーンアップおよび処理し、
df_ml_cleanという名前の新しい DataFrame 変数に格納する次の文を入力します。import pandas as pd def clean_data(df_ml): # 新しい列を生成: 推定注文合計 = 商品価格 * 数量 df_ml['predict_total_fee'] = df_ml['item_price'].astype(float).values * df_ml['buy_amount'].astype(float).values # 'total_fee' 列を 'actual_total_fee' に名前変更 df_ml = df_ml.rename(columns={'total_fee': 'actual_total_fee'}) return df_ml df_ml_clean = clean_data(df_ml.copy()) df_ml_clean.head()Python Cell の [実行] ボタンをクリックし、実行が完了するのを待って、データクリーニングの結果を表示します。
DataWorks Notebook で、
ボタンをクリックして新しい Python Cell を作成します。Python Cell に、線形回帰機械学習モデルを構築、トレーニング、テストするための次の文を入力します。
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error # 商品価格と合計料金を取得 X = df_ml_clean[['predict_total_fee']].values y = df_ml_clean['actual_total_fee'].astype(float).values # データを準備 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.05, random_state=42) # モデルを作成してトレーニング model = LinearRegression() model.fit(X_train, y_train) # 予測と評価 y_pred = model.predict(X_test) for index, (x_t, y_pre, y_t) in enumerate(zip(X_test, y_pred, y_test)): print("[{:>2}] input: {:<10} prediction:{:<10} gt: {:<10}".format(str(index+1), f"{x_t[0]:.3f}", f"{y_pre:.3f}", f"{y_t:.3f}")) # 平均二乗誤差 (MSE) を計算 mse = mean_squared_error(y_test, y_pred) print("Mean Squared Error (MSE):", mse)[実行] ボタンをクリックし、実行が完了するのを待って、モデルトレーニングのテスト結果を表示します。