DataWorks と MaxCompute を使用して CSV データセットをアップロードし、SQL で住宅購入レコードをフィルタリングし、住宅ローンを利用している独身購入者の学歴分布を可視化します。
ケーススタディ
ローカルの住宅購入データを MaxCompute の bank_data テーブルにアップロードし、MaxCompute SQL タスクノードを実行して result_table を生成し、result_table を可視化して購入者セグメントをプロファイリングします。
このケーススタディではサンプルデータを使用します。実際のシナリオでは、お客様の特定のビジネスデータに合わせてプロセスを調整する必要があります。
結果は、ローンを利用している独身の住宅購入者の学歴が主に university.degree または high.school であることを示しています。

前提条件
DataWorks のアクティベート
このチュートリアルでは、中国 (上海) リージョンを使用します。DataWorks コンソールにログインし、中国 (上海) リージョンに切り替えて、DataWorks がアクティベートされていることを確認します。
このチュートリアルでは、中国 (上海) を例として使用します。実際の使用では、ビジネスデータの所在地に基づいてリージョンを選択してください:
-
ビジネスデータが他の Alibaba Cloud サービスに保存されている場合は、それらのサービスと同じリージョンを選択します。
-
ビジネスがオンプレミスにあり、パブリックネットワークアクセスが必要な場合は、地理的に最も近いリージョンを選択してレイテンシーを削減します。
新規ユーザー
DataWorks を初めて使用する新規ユーザーの場合、次のコンテンツが表示され、現在のリージョンで DataWorks がアクティベートされていないことを示します。$0コンビネーション購入 をクリックします。

-
セット購入ページでパラメーターを構成します。
パラメーター
説明
例
リージョン
DataWorks をアクティベートするリージョンを選択します。
中国 (上海)
DataWorksのバージョン
購入する DataWorks のエディションを選択します。
説明このチュートリアルでは Basic Edition を例として使用します。すべてのエディションがこのチュートリアルで説明する機能をサポートしています。「エディションの比較」をご参照のうえ、ビジネス要件に応じて適切な DataWorks エディションを選択できます。
Basic Edition
-
注文を確認して支払う をクリックし、支払いを完了します。
以前にアクティベートしたが期限切れの場合
中国 (上海) リージョンで以前に DataWorks をアクティベートしたが、DataWorks エディションの有効期限が切れている場合は、次のプロンプトが表示されます。購入バージョン をクリックします。
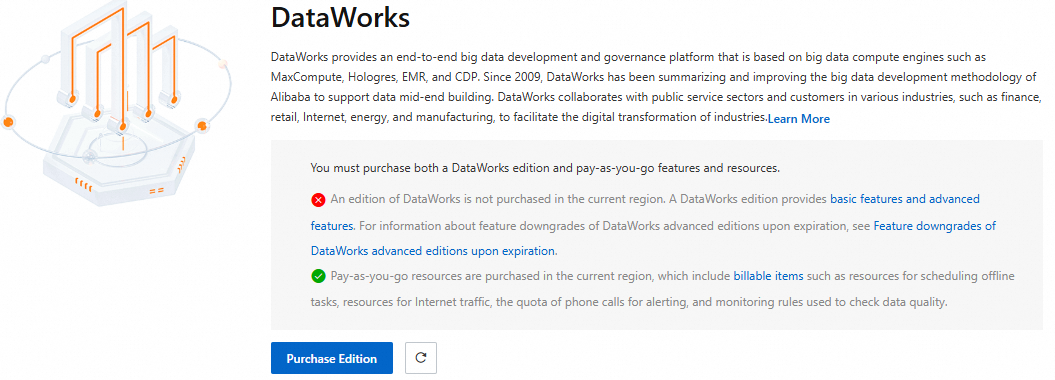
-
購入ページでパラメーターを構成します。
パラメーター
説明
例
Version
購入する DataWorks のエディションを選択します。
説明このチュートリアルでは Basic Edition を例として使用します。すべてのエディションがこのチュートリアルで説明する機能をサポートしています。「エディションの比較」をご参照のうえ、ビジネス要件に応じて適切な DataWorks エディションを選択できます。
Basic Edition
リージョン
DataWorks をアクティベートするリージョンを選択します。
中国 (上海)
-
Buy Now をクリックし、支払いを完了します。
購入後に DataWorks エディションが表示されない場合:
-
数分待ってからページをリフレッシュしてください。
-
現在のリージョンが DataWorks を購入したリージョンと一致していることを確認してください。
すでにアクティベート済みの場合
すでに 中国 (上海) リージョンで DataWorks をアクティベートしている場合は、DataWorks の概要ページが表示され、次のステップに進むことができます。
ワークスペースの作成
リソースグループの作成とワークスペースへの関連付け
MaxCompute 計算リソースの作成と関連付け
手順
サンプルデータを MaxCompute プロジェクトにアップロードし、DataStudio ワークフローを作成してデータをクリーンアップし、デバッグパスを実行して、SQL クエリで結果を確認します。
1. テーブルの作成
DataWorks のデータマップを使用して、サンプルデータをアップロードする前に MaxCompute プロジェクトに bank_data テーブルを作成します。
-
DataWorks コンソールにログインします。ターゲットリージョンに切り替えた後、左側のナビゲーションウィンドウで をクリックします。ドロップダウンリストからワークスペースを選択し、[DataStudio に入る] をクリックします。
-
DataStudio ページで、左側のナビゲーションウィンドウの
 アイコンをクリックして Data Catalog ページに移動します。
アイコンをクリックして Data Catalog ページに移動します。 -
(任意) MaxCompute プロジェクトがデータマップに追加されていない場合は、MaxCompute ディレクトリの横にある
 アイコンをクリックします。DataWorks Data Sources タブで、すでに計算リソースまたはデータソースとして構成されている MaxCompute プロジェクトを MaxCompute ディレクトリに追加します。
アイコンをクリックします。DataWorks Data Sources タブで、すでに計算リソースまたはデータソースとして構成されている MaxCompute プロジェクトを MaxCompute ディレクトリに追加します。 -
MaxCompute ディレクトリを展開し、目的のプロジェクトを選択してから、Table フォルダに MaxCompute テーブルを作成します。
説明-
MaxCompute プロジェクトでスキーマが有効になっている場合は、プロジェクトを展開し、ターゲットスキーマを開いてから、Table フォルダに MaxCompute テーブルを作成します。
-
このチュートリアルでは標準モードのワークスペースを使用し、開発環境でのデバッグ実行のみを含みます。したがって、開発環境に対応する MaxCompute プロジェクトに
bank_dataテーブルを作成するだけで済みます。基本モードのワークスペースを使用する場合は、本番環境に対応する MaxCompute プロジェクトにbank_dataテーブルを作成するだけで済みます。
-
-
テーブルディレクトリの右側にある
 アイコンをクリックしてテーブルを追加し、テーブルエディターを開きます。
アイコンをクリックしてテーブルを追加し、テーブルエディターを開きます。エディターの右側にある DDL セクションに、次の SQL コードを入力します。すると、システムが自動的にテーブル情報を入力します。
CREATE TABLE IF NOT EXISTS bank_data ( age BIGINT COMMENT '年齢', job STRING COMMENT '職種', marital STRING COMMENT '婚姻状況', education STRING COMMENT '学歴', `default` STRING COMMENT 'クレジットカードの有無', housing STRING COMMENT '住宅ローン', loan STRING COMMENT '個人ローン', contact STRING COMMENT '連絡方法', month STRING COMMENT '月', day_of_week STRING COMMENT '曜日', duration STRING COMMENT '持続時間', campaign BIGINT COMMENT 'このキャンペーン中の連絡回数', pdays DOUBLE COMMENT '前回の連絡からの日数', previous DOUBLE COMMENT 'クライアントとの以前の連絡回数', poutcome STRING COMMENT '前回のマーケティングキャンペーンの結果', emp_var_rate DOUBLE COMMENT '雇用変動率', cons_price_idx DOUBLE COMMENT '消費者物価指数', cons_conf_idx DOUBLE COMMENT '消費者信頼感指数', euribor3m DOUBLE COMMENT 'ユーロ圏 3 ヶ月物金利', nr_employed DOUBLE COMMENT '従業員数', y BIGINT COMMENT '定期預金の有無' ); -
エディターで Publish をクリックして、開発環境の MaxCompute プロジェクトに
bank_dataテーブルを作成します。 -
bank_dataテーブルが作成されたら、データマップでその名前をクリックして詳細を表示します。
2. データのアップロード
banking.csv ファイルをローカルコンピューターにダウンロードし、DataWorks のデータアップロード機能を使用して MaxCompute プロジェクトの bank_data テーブルにアップロードします。制限については「使用制限」をご確認ください。
アップロードする前に、スケジューリングリソースグループと Data Integration リソースグループをデータアップロード機能に割り当てます。「使用制限」をご参照ください。
-
左上隅の
 アイコンをクリックします。表示されるペインで、 を選択して、アップロード/ダウンロードページに移動します。
アイコンをクリックします。表示されるペインで、 を選択して、アップロード/ダウンロードページに移動します。 -
Recent Upload Records セクションで、Upload Data をクリックしてデータアップロード構成ページに移動します。次の表の説明に従ってパラメーターを構成します。
パラメーター
説明
Data Source
ローカルファイル。
Specify Data to Be Uploaded
Select File
ローカルコンピューターにダウンロードした
banking.csvファイルをアップロードします。Configure Destination Table
Compute Engine Type
MaxCompute
MaxCompute プロジェクト名
bank_dataテーブルがある MaxCompute プロジェクトを選択します。Select Destination Table
ターゲットテーブルとして
bank_dataテーブルを選択します。Preview Data of Uploaded File
[順序でマッピング] をクリックして、ファイルデータを
bank_dataテーブルのフィールドにマッピングします。説明-
ローカルファイルは
.csv、.xls、.xlsx、.json形式でアップロードできます。 -
スプレッドシートの場合、DataWorks はデフォルトで最初のシートのみをアップロードします。
-
.csvファイルの最大サイズは 5 GB です。他のファイルタイプの最大サイズは 100 MB です。
-
-
Upload Data をクリックして、CSV ファイルのデータを MaxCompute 計算リソースの
bank_dataテーブルにアップロードします。 -
データが正常にアップロードされたことを確認します。
SQL クエリ (レガシー) を使用して、データが
bank_dataテーブルに書き込まれたことを確認します。-
左上隅の
アイコンをクリックし、 を選択します。 -
マイファイルの横にある
 > Create File をクリックします。カスタムの File Name を指定し、Determine をクリックします。
> Create File をクリックします。カスタムの File Name を指定し、Determine をクリックします。 -
SQL クエリページで、次の SQL ステートメントを入力します。
SELECT * FROM bank_data limit 10;SELECT * FROM bank_data limit 10; -
右上隅で、
bank_dataテーブルのワークスペースと MaxCompute データソースを選択し、Determine をクリックします。説明このチュートリアルでは標準モードのワークスペースを使用し、
bank_dataテーブルは開発環境でのみ作成されます。データソースを選択する際は、開発環境の MaxCompute データソースを選択する必要があります。基本モードのワークスペースを使用する場合は、本番環境の MaxCompute データソースを選択できます。 -
ページ上部の Run をクリックします。Estimate Costs ページで Run をクリックします。クエリが正常に実行されると、ページの下部に
bank_dataテーブルの最初の 10 レコードが表示されます。これは、ローカルデータをbank_dataテーブルに正常にアップロードしたことを示します。bank_data テーブルには、age、job、marital、education、default、housing、loan、contact、month、day_of_week、duration、campaign、pdays などのフィールドが含まれています。
-
3. データ処理
MaxCompute SQL ノードで bank_data テーブルをフィルタリングして、住宅ローンを利用している独身者の学歴分布を取得し、結果を新しい result_table に書き込みます。
データ処理ワークフローの構築
-
左上隅の
 アイコンをクリックし、 を選択して DataStudio ページに移動します。
アイコンをクリックし、 を選択して DataStudio ページに移動します。 -
ページの上部で、このチュートリアル用に作成したワークスペースに切り替えます。左側のナビゲーションウィンドウで
 をクリックして DataStudio に移動します。
をクリックして DataStudio に移動します。 -
Project Directory セクションで
 をクリックし、Create Workflow を選択します。ワークフロー名を
をクリックし、Create Workflow を選択します。ワークフロー名を dw_basic_caseに設定し、Confirm をクリックしてワークフローを保存し、ワークフローオーケストレーションキャンバスに移動します。 -
キャンバスの左側から Zero-Load Node 1 つと MaxCompute SQL 2 つをキャンバスにドラッグし、各ノードに名前を設定します。
次の表に、このチュートリアルで使用するノードとその目的を示します。
Node Type
Node Name
目的
 仮想ノード
仮想ノードworkshop_startワークフローの開始をアンカーします。これはコードを必要としない Dry-run Task です。
 MaxCompute SQL ノード
MaxCompute SQL ノードddl_result_tablebank_dataからクリーンアップされたデータを保存するためにresult_tableを作成します。 MaxCompute SQL ノードinsert_result_tablebank_dataをフィルタリングし、結果をresult_tableに書き込みます。 -
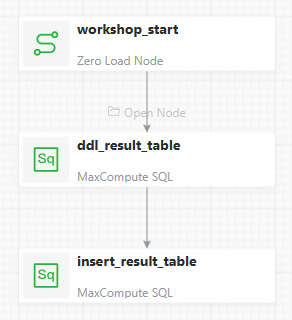 説明
説明上流と下流の依存関係は、ノード間に線を描画して手動で定義するか、子ノードのコードを解析してシステムに検出させることができます。このチュートリアルでは手動での配線を使用します。「依存関係の自動解析」をご参照ください。
-
ノードツールバーで Save をクリックします。
データ処理ノードの構成
4. デバッグと実行
dw_basic_case オーケストレーションキャンバスで、 アイコンをクリックしてワークフロー全体をデバッグモードで実行します。実行が失敗した場合は、デバッグログを確認してください。
アイコンをクリックしてワークフロー全体をデバッグモードで実行します。実行が失敗した場合は、デバッグログを確認してください。
実行が成功すると、workshop_start、ddl_result_table、insert_result_table に緑色のチェックマークが表示されます。
5. データのクエリと可視化
SQL クエリ (レガシー) で result_table データをクエリして分析します。
-
左上隅の
アイコンをクリックし、 を選択します。 -
マイファイルの横にある
> Create File をクリックします。カスタムの File Name を指定し、Determine をクリックします。 -
SQL クエリページで、次の SQL ステートメントを入力します。
SELECT * FROM result_table;SELECT * FROM result_table; -
右上隅で、
result_tableテーブルの ワークスペース と MaxCompute データソース を選択し、Determine をクリックします。説明このチュートリアルでは標準モードのワークスペースを使用し、
result_tableテーブルは開発環境で作成されますが、本番環境にはデプロイされません。したがって、開発環境の MaxCompute データソースを選択する必要があります。基本モードのワークスペースを使用する場合は、本番環境の MaxCompute データソースを選択できます。 -
ページ上部の Run をクリックします。Estimate Costs ページで Run をクリックします。
-
クエリ結果で
 をクリックして可視化チャートを表示します。チャートの右上隅にある
をクリックして可視化チャートを表示します。チャートの右上隅にある  をクリックして、チャートのスタイルをカスタマイズできます。
をクリックして、チャートのスタイルをカスタマイズできます。 -
また、チャートの右上隅にある Save をクリックしてカードとして保存し、左側のナビゲーションウィンドウで Card (
 ) をクリックして表示することもできます。
) をクリックして表示することもできます。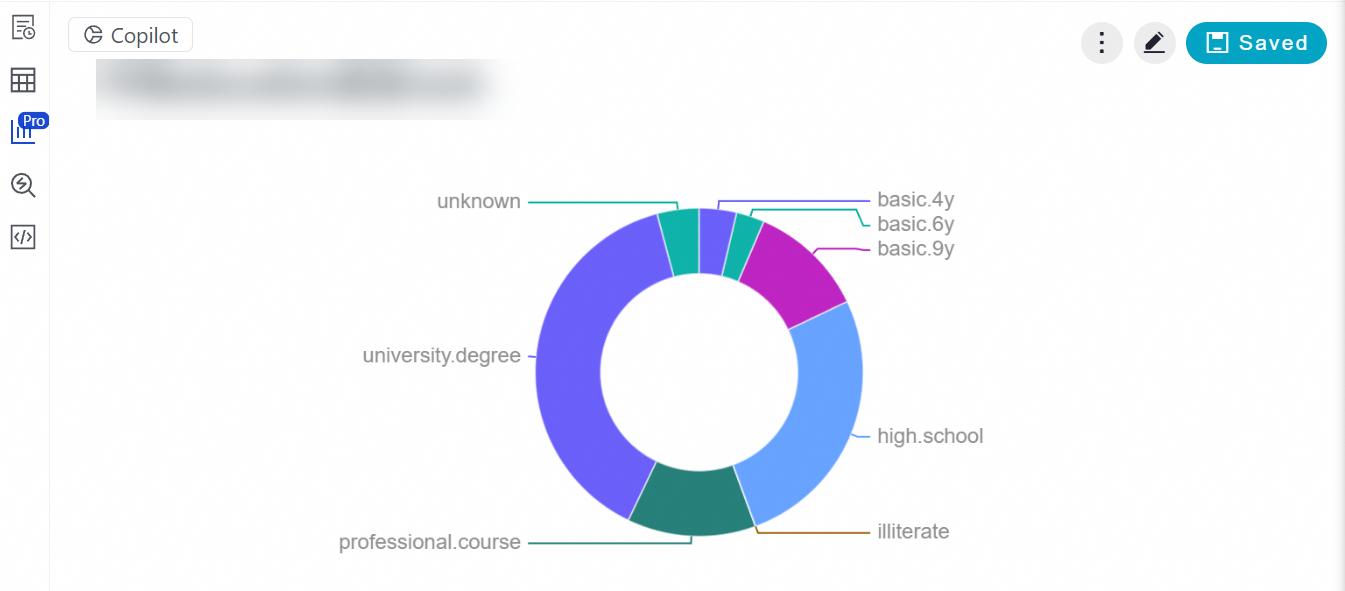
次のステップ
-
ここで使用したモジュールの詳細については、「Data Studio (新)」と「データ分析」をご参照ください。
-
DataWorks は、エンドツーエンドのデータモニタリングと O&M のために、データモデリング、Data Quality、データセキュリティガード、Data Service、Data Integration、ノードスケジューリング構成も提供しています。
-
その他の実践的な演習については、「その他のユースケースとチュートリアル」をご参照ください。
リソースのクリーンアップ
不要な料金を避けるために、このチュートリアルで作成したリソースを解放します。
-
定期タスクを停止します。
-
DataWorks コンソールにログインします。ターゲットリージョンで、左側のナビゲーションウィンドウの をクリックします。ドロップダウンリストからワークスペースを選択し、入力 操作とメンテナンスセンター をクリックします。
-
で、以前に作成したすべての定期タスクを選択し (ワークスペースのルートノードはアンデプロイする必要はありません)、下部にある をクリックします。
-
-
データ開発ワークフローを削除し、MaxCompute 計算リソースの関連付けを解除します。
-
DataWorks コンソールの [ワークスペース] ページに移動します。上部のナビゲーションバーで、目的のリージョンを選択します。目的のワークスペースを見つけ、[アクション] 列の を選択します。
-
Data Studio の左側のナビゲーションウィンドウで
 をクリックしてデータ開発ページに移動します。Project Directory セクションで、作成したワークフローを見つけ、右クリックして Delete をクリックします。
をクリックしてデータ開発ページに移動します。Project Directory セクションで、作成したワークフローを見つけ、右クリックして Delete をクリックします。 -
左側のナビゲーションウィンドウで
 > [計算リソース管理] をクリックします。関連付けられた MaxCompute 計算リソースを見つけ、解绑 をクリックします。確認ダイアログで、オプションを選択し、指示に従って関連付けの解除を完了します。
> [計算リソース管理] をクリックします。関連付けられた MaxCompute 計算リソースを見つけ、解绑 をクリックします。確認ダイアログで、オプションを選択し、指示に従って関連付けの解除を完了します。
-
-
MaxCompute プロジェクトを削除します。
MaxCompute プロジェクト管理ページに移動し、作成した MaxCompute プロジェクトを見つけて、Operation 列の Delete をクリックします。指示に従って削除を完了します。
-
DataWorks ワークスペースを削除します。
-
DataWorks コンソールにログインします。ターゲットリージョンに切り替え、左側のナビゲーションウィンドウで [ワークスペース] をクリックします。ワークスペースリストで、削除したい DataWorks ワークスペースを見つけ、[アクション] 列の
 アイコンをクリックし、[ワークスペースの削除] を選択します。
アイコンをクリックし、[ワークスペースの削除] を選択します。 -
ワークスペースの削除 ダイアログボックスで、Confirm をクリックしてワークスペースを削除します。
-