Data Studio は Alibaba Cloud が提供するインテリジェントなデータレイクハウス開発プラットフォームであり、10 年以上にわたるビッグデータ分野での専門知識に基づいて構築されています。幅広い Alibaba Cloud コンピュートサービスをサポートし、インテリジェント ETL、データカタログ管理、マルチエンジンによるワークフローのオーケストレーション機能を提供します。また、Python、ノートブック分析、Git 統合をサポートするパーソナル開発環境インスタンスを備えています。豊富なプラグインエコシステムと組み合わせることで、リアルタイム処理とバッチ処理、データレイクハウスアーキテクチャ、ビッグデータと AI を統合し、Data+AI データ管理ライフサイクル全体を強力に支援します。
Data Studio
Data Studio は Alibaba のビッグデータベストプラクティスを組み込んだインテリジェントなデータレイクハウス開発プラットフォームです。MaxCompute、E-MapReduce、Hologres、Flink、PAI など、数十種類の Alibaba Cloud ビッグデータおよび AI コンピュートサービスと深く統合されています。データウェアハウス、データレイク、OpenLake データレイクハウスアーキテクチャ向けのインテリジェント ETL 開発サービスを提供します。主な特徴は以下のとおりです。
-
データレイクハウスおよびマルチエンジン対応
統一された データカタログ を通じて、データレイク (OSS など) およびデータウェアハウス (MaxCompute など) にまたがるデータへシームレスにアクセスできます。豊富なエンジンノードにより、マルチエンジンのハイブリッド開発が可能になります。 -
柔軟なワークフローとスケジューリング
多彩なフローコントロールノードを使用して、ワークフロー内で マルチエンジンタスク を視覚的にオーケストレーションできます。時間ベースの 定期スケジューリング およびイベントドリブンの トリガー型スケジューリング の両方をサポートしています。 -
オープンな Data+AI 開発環境
パーソナル開発環境(カスタム依存関係の設定が可能)、SQL と Python コードを混在させた記述をサポートする ノートブック、データセット 管理、Git 統合 などの機能により、柔軟な AI 研究開発ワークステーションを構築できます。 -
インテリジェント支援と AI エンジニアリング
強力な内蔵型 Copilot がコード開発プロセス全体を支援します。専門的な PAI アルゴリズムノード および 大規模モデルノード により、エンドツーエンドの AI エンジニアリングをネイティブにサポートします。
基本概念
|
概念 |
定義 |
コアバリュー |
キーワード |
|
ワークフロー |
タスクを整理・オーケストレーションする単位です。 |
複雑なタスクの依存関係を管理し、スケジューリングを自動化します。開発およびスケジューリングのコンテナとして機能します。 |
可視化、DAG、定期/トリガー型、オーケストレーション |
|
ノード |
ワークフローにおける最小実行単位です。 |
コードを記述し、具体的なビジネスロジックを実装する場所です。データ処理におけるアトミック操作となります。 |
SQL、Python、Shell、データ統合 |
|
カスタムイメージ |
環境の標準化されたスナップショットです。 |
環境の拡張性、一貫性、再現性を保証します。 |
環境永続化、標準化、再現性、一貫性 |
|
スケジューリング |
タスクを自動的にトリガーするためのルールです。 |
手動タスクを自動化された本番ワークロードに変換することで、データ生成を自動化します。 |
定期スケジューリング、トリガー型スケジューリング、依存関係、自動化 |
|
データカタログ |
統一されたメタデータワークベンチです。 |
テーブルなどのデータ資産や、関数・リソースなどの計算リソースを構造化された形で整理・管理します。 |
メタデータ、テーブル管理、データ探索 |
|
データセット |
外部ストレージへの論理的マッピングです。 |
画像やドキュメントなどの外部非構造化データへのギャップを埋め、AI 開発における重要なデータブリッジとして機能します。 |
OSS/NAS アクセス、データマウント、非構造化 |
|
ノートブック |
インタラクティブな Data+AI 開発キャンバスです。 |
SQL と Python コードを統合し、データ探索およびアルゴリズム検証を加速します。 |
インタラクティブ、マルチ言語、可視化、探索的分析 |
開発プロセス
Data Studio はデータウェアハウス開発および AI 開発のためのプロセスを提供します。以下のセクションでは、2 つの一般的なパスについて説明します。お客様の具体的なニーズに応じて、他のパスもご検討いただけます。
標準パス:データウェアハウス開発
このプロセスは、安定した自動化されたバッチデータ処理を実現するエンタープライズデータウェアハウスの構築に適しています。
-
対象ユーザー:データエンジニアおよび ETL 開発者
-
主要目的:バッチデータ処理およびレポート生成のための、安定的で標準化された自動スケジューリング機能を備えたエンタープライズデータウェアハウスを構築すること
-
主要技術:データカタログ、定期ワークフロー、SQL ノード、スケジューリング構成
|
ステップ |
フェーズ |
説明 |
場所とリファレンス |
|
1 |
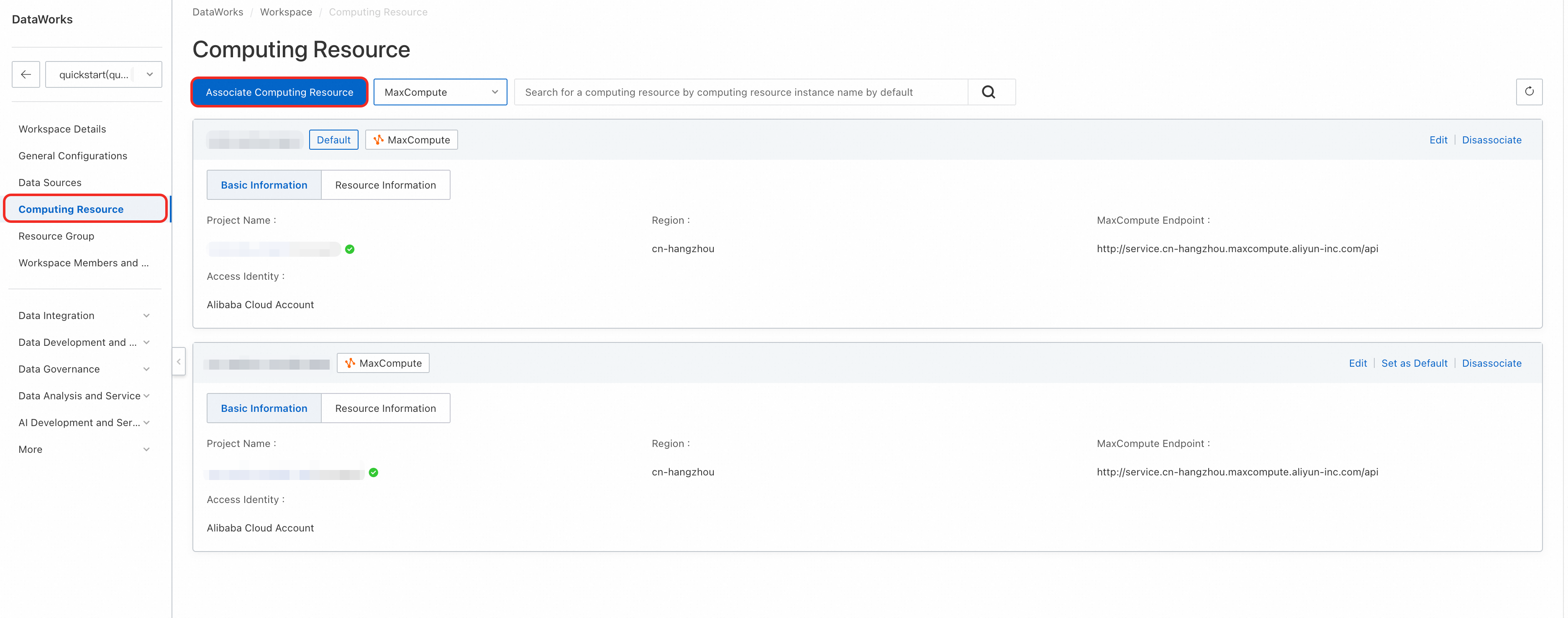
コンピュートエンジンの関連付け |
MaxCompute などの 1 つ以上のコアコンピュートエンジンをワークスペースに関連付けて、すべての SQL タスクを実行できるようにします。
|
コンソール > ワークスペース構成 関連ドキュメントについては、「コンピュートリソースの関連付け」をご参照ください。 |
|
2 |
データカタログの管理 |
データカタログで、データウェアハウスの各レイヤー (ODS、DWD、ADS など) に必要なテーブルスキーマを作成または探索します。これにより、データ処理の入出力が定義されます。 データモデリング モジュールを使用してデータウェアハウスシステムを構築することを推奨します。 |
Data Studio > データカタログ 関連ドキュメントについては、「データカタログ」をご参照ください。 |
|
3 |
定期ワークフローの作成 |
プロジェクトディレクトリ内に定期ワークフローを作成し、関連する ETL タスクを整理・管理するコンテナとして使用します。 |
Data Studio > プロジェクトディレクトリ > 定期ワークフロー 関連ドキュメントについては、「定期ワークフローのオーケストレーション」をご参照ください。 |
|
4 |
ノードの開発とデバッグ |
ODPS SQL ノードなどのノードを作成し、エディターでコアとなる ETL ロジック (データクレンジング、変換、集約) を記述します。その後、ノードをデバッグします。 |
関連ドキュメントについては、「ノード開発」をご参照ください。 |
|
5 |
Copilot の支援による開発 |
DataWorks Copilot を使用して、SQL および Python コードの生成、修正、再書き込み、変換を行います。 |
|
|
6 |
ノードのオーケストレーションとスケジューリング |
ワークフローの DAG キャンバス上で、ノード間の上流・下流の依存関係をドラッグ&接続によって定義します。複雑なオーケストレーションに対応するため、さまざまなフローコントロールノードが利用可能です。 ワークフローまたは個々のノードに対して、周期、時刻、依存関係などの本番スケジューリングプロパティを構成します。このプラットフォームは、1 日あたり数千万件のインスタンスの大規模スケジューリングをサポートしています。 |
関連ドキュメントについては、「汎用フローコントロールノード」および「ノードスケジューリング構成」をご参照ください。 |
|
7 |
ワークフロー/ノードのデプロイと運用保守 |
|
|
関連する入門例については、「上級編:売れ筋商品カテゴリの分析」をご参照ください。
高度なパス:ビッグデータおよび AI 開発
このプロセスは、AI モデル開発、データサイエンス探索、リアルタイム AI アプリケーションの構築に適しています。環境の柔軟性とインタラクティブ性を重視します。ユースケースに応じてステップを調整してください。
-
対象ユーザー:AI エンジニア、データサイエンティスト、アルゴリズムエンジニア
-
主要目的:データ探索、モデルトレーニング、アルゴリズム検証、またはリアルタイム AI アプリケーション (例:Retrieval-Augmented Generation (RAG) やリアルタイム推論サービス) の構築
-
主要技術:パーソナル開発環境、ノートブック、イベントトリガー型ワークフロー、データセット、カスタムイメージ
|
ステップ |
フェーズ |
説明 |
場所とリファレンス |
|
1 |
パーソナル開発環境の作成 |
複雑な Python 依存関係をインストールし、プロフェッショナルな AI 開発を行うための、分離されカスタマイズ可能なクラウドコンテナインスタンスを作成します。 |
Data Studio > パーソナル開発環境 関連ドキュメントについては、「パーソナル開発環境」をご参照ください。 |
|
2 |
イベントトリガー型ワークフローの作成 |
プロジェクトディレクトリ内に外部イベントによって駆動されるワークフローを作成します。これは、リアルタイム AI アプリケーションのオーケストレーションコンテナとして機能します。 |
Data Studio > プロジェクトディレクトリ > イベントトリガー型ワークフロー 関連ドキュメントについては、「イベントトリガー型ワークフロー」をご参照ください。 |
|
3 |
トリガーの作成と設定 |
オペレーションセンターで、OSS イベントや Kafka メッセージなどの外部イベントによってワークフローを開始するトリガーを構成します。 |
関連ドキュメントについては、「トリガーの管理」および「イベントトリガー型ワークフロー」をご参照ください。 |
|
4 |
ノートブックノードの作成 |
AI および Python コードを記述するためのコア開発ユニットを作成します。通常、パーソナルフォルダー内のノートブックから探索を開始します。 |
プロジェクトディレクトリ > イベントトリガー型ワークフロー > ノートブックノード 関連ドキュメントについては、「ノードの作成」をご参照ください。 |
|
5 |
データセットの作成と使用 |
OSS や NAS に保存されている画像やドキュメントなどの非構造化データをデータセットとして登録し、開発環境またはタスクにマウントしてコードからアクセスできるようにします。 |
関連ドキュメントについては、「データセットの管理」および「データセットの使用」をご参照ください。 |
|
6 |
ノートブック/ノードの開発とデバッグ |
パーソナル開発環境が提供するインタラクティブ環境で、アルゴリズムロジックを記述し、データを探索し、モデルを検証し、迅速に反復処理を行います。 |
Data Studio > ノートブックエディター 関連ドキュメントについては、「ノートブック開発の基本」をご参照ください。 |
|
7 |
カスタム依存パッケージのインストール |
パーソナル開発環境のターミナルまたはノートブックセルで、 |
Data Studio > パーソナル開発環境 > ターミナル 関連ドキュメントについては、「付録:パーソナル開発環境の整備」をご参照ください。 |
|
8 |
カスタムイメージの作成 |
構成済みのパーソナル開発環境を標準化されたイメージとしてスナップショット化します。これにより、本番環境が開発環境と同一であることが保証されます。 カスタム依存パッケージをインストールしていない場合は、このステップをスキップできます。 |
関連ドキュメントについては、「パーソナル開発環境から DataWorks イメージを作成する」をご参照ください。 |
|
9 |
ノードスケジューリングの構成 |
本番ノードのスケジューリング構成では、前ステップで作成したカスタムイメージを実行環境として必ず指定し、必要なデータセットをマウントする必要があります。 |
Data Studio > ノートブックノード > スケジューリング構成 関連ドキュメントについては、「ノードスケジューリング構成」をご参照ください。 |
|
10 |
ノード/ワークフローのデプロイと運用保守 |
|
|
コアモジュール
|
モジュール |
主要機能 |
|
ワークフローのオーケストレーション |
ドラッグ&ドロップインターフェイスにより、複雑なプロジェクトを簡単に構築・管理できる視覚的な有向非巡回グラフ (DAG) キャンバスを提供します。定期ワークフローのオーケストレーション、イベントトリガー型ワークフロー、手動ビジネスプロセス をサポートし、さまざまな自動化ニーズに対応します。 |
|
実行環境とモード |
開発効率とコラボレーションを向上させる柔軟でオープンな開発環境を提供します。
|
|
ノード開発 |
柔軟なデータ処理および分析を実現するため、幅広いノードタイプおよびコンピュートエンジンをサポートします。
詳細については、「コンピュートリソース管理」および「ノード開発」をご参照ください。 |
|
ノードスケジューリング |
タスクが時間通りかつ秩序正しく実行されるよう、強力で柔軟な自動スケジューリング機能を提供します。
|
|
開発リソース管理 |
データ開発プロセスに関与するさまざまな資産を一元管理します。 |
|
品質管理 |
標準化されたデータ生成プロセスと正確なデータ出力を保証するため、複数の組み込み制御メカニズムを備えています。
|
|
オープン性と拡張性 |
外部システムとの統合およびカスタム開発を容易にするため、豊富なオープンインターフェイスおよび拡張ポイントを提供します。 |
課金
DataWorks 側の課金 (DataWorks 請求書に含まれる)
リソースグループ料金:ノード開発およびパーソナル開発環境の使用はリソースグループに依存します。リソースグループのタイプに応じて、サーバーレスリソースグループ料金 または 専用スケジューリングリソースグループ料金 が発生します。
大規模モデルサービス を使用する場合も、サーバーレスリソースグループ料金が発生します。
タスクスケジューリング料金:タスクを本番環境にデプロイしてスケジュール実行する場合、タスクスケジューリング料金 (サーバーレスリソースグループ使用時) または 専用スケジューリングリソースグループ料金 (専用リソースグループ使用時) が発生します。
Data Quality 料金:スケジュールタスクに品質モニタリングを構成し、インスタンスが正常にトリガーされた場合、Data Quality インスタンス料金 が発生します。
インテリジェントベースライン料金:スケジュールタスクにインテリジェントベースラインを構成すると、有効化されたインテリジェントベースラインに対して インテリジェントベースラインインスタンス料金 が発生します。
アラート SMS および電話料金:スケジュールタスクにモニタリングアラートを構成し、SMS または電話アラートが正常にトリガーされた場合、アラート SMS および電話料金 が発生します。
説明関連モジュール:Data Studio、Data Quality、オペレーションセンター
DataWorks 以外の課金 (DataWorks 請求書に含まれない)
データ開発ノードタスクを実行する際に発生する可能性のある コンピュートエンジンの計算およびストレージ料金 (OSS ストレージ料金など) は、DataWorks によって課金されません。
クイックスタート
Data Studio の作成または有効化
-
ワークスペースを作成する際、「新しいバージョンのData Development (Data Studio) を使用する」を選択します。詳細については、「ワークスペースの作成」をご参照ください。
-
旧 DataStudio を使用している場合、DataStudio ページの上部にある 新バージョンにアップグレード をクリックし、画面の指示に従ってデータを Data Studio に移行できます。詳細については、「Data Studio アップグレードガイド」をご参照ください。
Data Studio の開き方
DataWorks コンソールの ワークスペース ページにアクセスします。上部ナビゲーションバーで目的のリージョンを選択し、目的のワークスペースを見つけたら、操作 列で を選択します。
よくある質問
-
Q:新 Data Studio と旧 DataStudio の違いをどのように見分ければよいですか?
A:ユーザーインターフェースはまったく異なります。新 Data Studio は上部バーがダークカラーで、左側にツリー形式のディレクトリが表示されます。一方、旧バージョンは背景がライトカラーで、従来のパネルレイアウトになっています。
-
Q:新 Data Studio にアップグレードした後、旧バージョンに戻すことはできますか?
A:アップグレードは不可逆です。アップグレードが成功した後は、旧バージョンに戻すことはできません。切り替える前に、新 Data Studio を有効にしてワークスペースを作成し、ビジネスニーズを満たすかどうかをテストすることを推奨します。また、新旧バージョンのデータは別々に管理されます。
-
Q:ワークスペース作成時に 新しいバージョンのData Development (Data Studio) を使用する のオプションが表示されないのはなぜですか?
A:このオプションが表示されない場合、ワークスペースで新 Data Studio がデフォルトで有効になっているためです。
重要新 Data Studio の使用中に問題が発生した場合は、Data Studio アップグレードサポート用の DataWorks DingTalk グループ に参加してご支援を受けることができます。